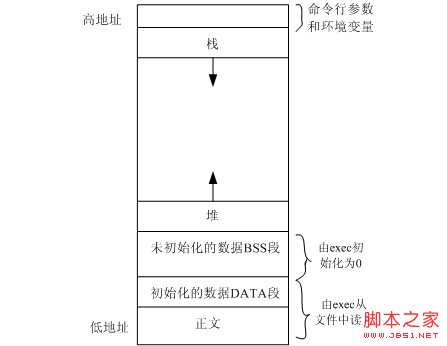
我們都知道C++中有三種創建對象的方法,如下:
代碼如下:
#include <iostream>
using namespace std;
class A
{
private:
int n;
public:
A(int m):n(m)
{
}
~A(){}
};
int main()
{
A a(1); //棧中分配
A b = A(1); //棧中分配
A* c = new A(1); //堆中分配
delete c;
return 0;
}
第一種和第二種沒什麼區別,一個隱式調用,一個顯式調用,兩者都是在進程虛擬地址空間中的棧中分配內存,而第三種使用了new,在堆中分配了內存,而棧中內存的分配和釋放是由系統管理,而堆中內存的分配和釋放必須由程序員手動釋放,所以這就產生一個問題是把對象放在棧中還是放在堆中的問題,這個問題又和堆和棧本身的區別有關:
這裡面有幾個問題:
1.堆和棧最大可分配的內存的大小
2.堆和棧的內存管理方式
3.堆和棧的分配效率
首先針對第一個問題,一般來說對於一個進程棧的大小遠遠小於堆的大小,在linux中,你可以使用ulimit -s (單位kb)來查看一個進程棧的最大可分配大小,一般來說不超過8M,有的甚至不超過2M,不過這個可以設置,而對於堆你會發現,針對一個進程堆的最大可分配的大小在G的數量級上,不同系統可能不一樣,比如32位系統最大不超過2G,而64為系統最大不超過4G,所以當你需要一個分配的大小的內存時,請用new,即用堆。
其次針對第二個問題,棧是系統數據結構,對於進程/線程是唯一的,它的分配與釋放由操作系統來維護,不需要開發者來管理。在執行函數時,函數內局部變量的存儲單元都可以在棧上創建,函數執行結束時,這些存儲單元會被自動釋放。棧內存分配運算內置於處理器的指令集中,效率很高,不同的操作系統對棧都有一定的限制。 堆上的內存分配,亦稱動態內存分配。程序在運行的期間用malloc申請的內存,這部分內存由程序員自己負責管理,其生存期由開發者決定:在何時分配,分配多少,並在何時用free來釋放該內存。這是唯一可以由開發者參與管理的內存。使用的好壞直接決定系統的性能和穩定。
由上可知,但我們需要的內存很少,你又能確定你到底需要多少內存時,請用棧。而當你需要在運行時才知道你到底需要多少內存時,請用堆。
最後針對第三個問題,棧是機器系統提供的數據結構,計算機會在底層對棧提供支持:分配專門的寄存器存放棧的地址,壓棧出棧都有專門的指令執行,這就決定了棧的效率 比較高。堆則是C/C++函數庫提供的,它的機制是很復雜的,例如為了分配一塊內存,庫函數會按照一定的算法(具體的算法可以參考數據結構/操作系統)在 堆內存中搜索可用的足夠大小的空間,如果沒有足夠大小的空間(可能是由於內存碎片太多),就有可能調用系統功能去增加程序數據段的內存空間,這樣就有機會 分 到足夠大小的內存,然後進行返回。顯然,堆的效率比棧要低得多。
由上可知,能用棧則用棧。
代碼如下:
#include <stdio.h>
#include <stdlib.h>
void main()
{
int n,*p,i,j,m;
printf("本程序可對任意個整數排序;\n");
printf("請輸入整數的總個數: ");
scanf("%d",&n);
p=(int *)calloc(n,sizeof(int)); //運行時決定內存分配大小
if(p==0) {
printf("分配失敗!\n");
exit(1);
}