linux提供了select、poll、epoll接口來實現IO復用,三者的原型如下所示,本文從參數、實現、性能等方面對三者進行對比。
代碼如下:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
select、poll、epoll_wait參數及實現對比
1.select的第一個參數nfds為fdset集合中最大描述符值加1,fdset是一個位數組,其大小限制為__FD_SETSIZE(1024),位數組的每一位代表其對應的描述符是否需要被檢查。
select的第二三四個參數表示需要關注讀、寫、錯誤事件的文件描述符位數組,這些參數既是輸入參數也是輸出參數,可能會被內核修改用於標示哪些描述符上發生了關注的事件。所以每次調用select前都需要重新初始化fdset。
timeout參數為超時時間,該結構會被內核修改,其值為超時剩余的時間。
select對應於內核中的sys_select調用,sys_select首先將第二三四個參數指向的fd_set拷貝到內核,然後對每個被SET的描述符調用進行poll,並記錄在臨時結果中(fdset),如果有事件發生,select會將臨時結果寫到用戶空間並返回;當輪詢一遍後沒有任何事件發生時,如果指定了超時時間,則select會睡眠到超時,睡眠結束後再進行一次輪詢,並將臨時結果寫到用戶空間,然後返回。
select返回後,需要逐一檢查關注的描述符是否被SET(事件是否發生)。
2.poll與select不同,通過一個pollfd數組向內核傳遞需要關注的事件,故沒有描述符個數的限制,pollfd中的events字段和revents分別用於標示關注的事件和發生的事件,故pollfd數組只需要被初始化一次。
poll的實現機制與select類似,其對應內核中的sys_poll,只不過poll向內核傳遞pollfd數組,然後對pollfd中的每個描述符進行poll,相比處理fdset來說,poll效率更高。
poll返回後,需要對pollfd中的每個元素檢查其revents值,來得指事件是否發生。
3.epoll通過epoll_create創建一個用於epoll輪詢的描述符,通過epoll_ctl添加/修改/刪除事件,通過epoll_wait檢查事件,epoll_wait的第二個參數用於存放結果。
epoll與select、poll不同,首先,其不用每次調用都向內核拷貝事件描述信息,在第一次調用後,事件信息就會與對應的epoll描述符關聯起來。另外epoll不是通過輪詢,而是通過在等待的描述符上注冊回調函數,當事件發生時,回調函數負責把發生的事件存儲在就緒事件鏈表中,最後寫到用戶空間。
epoll返回後,該參數指向的緩沖區中即為發生的事件,對緩沖區中每個元素進行處理即可,而不需要像poll、select那樣進行輪詢檢查。
select、poll、epoll_wait性能對比select、poll的內部實現機制相似,性能差別主要在於向內核傳遞參數以及對fdset的位操作上,另外,select存在描述符數的硬限制,不能處理很大的描述符集合。這裡主要考察poll與epoll在不同大小描述符集合的情況下性能的差異。
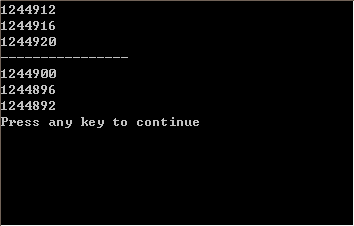
測試程序會統計在不同的文件描述符集合的情況下,1s內poll與epoll調用的次數。統計結果如下,從結果可以看出,對poll而言,每秒鐘內的系統調用數目雖集合增大而很快降低,而epoll基本保持不變,具有很好的擴展性。
描述符集合大小
poll
epoll
1
331598
258604
10
330648
297033
100
91199
288784
1000
27411
296357
5000
5943
288671
10000
2893
292397
25000
1041
285905
50000
536
293033
100000
224
285825
一、連接數我本人也曾經在項目中用過select和epoll,對於select,感觸最深的是linux下select最大數目限制(windows 下似乎沒有限制),每個進程的select最多能處理FD_SETSIZE個FD(文件句柄),
如果要處理超過1024個句柄,只能采用多進程了。
常見的使用slect的多進程模型是這樣的: 一個進程專門accept,成功後將fd通過unix socket傳遞給子進程處理,父進程可以根據子進程負載分派。曾經用過1個父進程+4個子進程 承載了超過4000個的負載。
這種模型在我們當時的業務運行的非常好。epoll在連接數方面沒有限制,當然可能需要用戶調用API重現設置進程的資源限制。
二、IO差別1、select的實現這段可以結合linux內核代碼描述了,我使用的是2.6.28,其他2.6的代碼應該差不多吧。
先看看select:select系統調用的代碼在fs/Select.c下,
代碼如下:
asmlinkage long sys_select(int n, fd_set __user *inp, fd_set __user *outp,
fd_set __user *exp, struct timeval __user *tvp)
{
struct timespec end_time, *to = NULL;
struct timeval tv;
int ret;
if (tvp) {
if (copy_from_user(&tv, tvp, sizeof(tv)))
return -EFAULT;
to = &end_time;
if (poll_select_set_timeout(to,
tv.tv_sec + (tv.tv_usec / USEC_PER_SEC),
(tv.tv_usec % USEC_PER_SEC) * NSEC_PER_USEC))
return -EINVAL;
}
ret = core_sys_select(n, inp, outp, exp, to);
ret = poll_select_copy_remaining(&end_time, tvp, 1, ret);
return ret;
}
前面是從用戶控件拷貝各個fd_set到內核空間,接下來的具體工作在core_sys_select中,
core_sys_select->do_select,真正的核心內容在do_select裡:
代碼如下:
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
ktime_t expire, *to = NULL;
struct poll_wqueues table;
poll_table *wait;
int retval, i, timed_out = 0;
unsigned long slack = 0;
rcu_read_lock();
retval = max_select_fd(n, fds);
rcu_read_unlock();
if (retval < 0)
return retval;
n = retval;
poll_initwait(&table);
wait = &table.pt;
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
wait = NULL;
timed_out = 1;
}
if (end_time && !timed_out)
slack = estimate_accuracy(end_time);
retval = 0;
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
set_current_state(TASK_INTERRUPTIBLE);
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
unsigned long in, out, ex, all_bits, bit = 1, mask, j;
unsigned long res_in = 0, res_out = 0, res_ex = 0;
const struct file_operations *f_op = NULL;
struct file *file = NULL;
in = *inp++; out = *outp++; ex = *exp++;
all_bits = in | out | ex;
if (all_bits == 0) {
i += __NFDBITS;
continue;
}
for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1) {
int fput_needed;
if (i >= n)
break;
if (!(bit & all_bits))
continue;
file = fget_light(i, &fput_needed);
if (file) {
f_op = file->f_op;
mask = DEFAULT_POLLMASK;
if (f_op && f_op->poll)
mask = (*f_op->poll)(file, retval ? NULL : wait);
fput_light(file, fput_needed);
if ((mask & POLLIN_SET) && (in & bit)) {
res_in |= bit;
retval++;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
}
}
}
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
cond_resched();
}
wait = NULL;
if (retval || timed_out || signal_pending(current))
break;
if (table.error) {
retval = table.error;
break;
}
/*
* If this is the first loop and we have a timeout
* given, then we convert to ktime_t and set the to
* pointer to the expiry value.
*/
if (end_time && !to) {
expire = timespec_to_ktime(*end_time);
to = &expire;
}
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
}
__set_current_state(TASK_RUNNING);
poll_freewait(&table);
return retval;
}
上面的代碼很多,其實真正關鍵的代碼是這一句:
代碼如下:
mask = (*f_op->poll)(file, retval ? NULL : wait);
這個是調用文件系統的 poll函數,不同的文件系統poll函數自然不同,由於我們這裡關注的是tcp連接,而socketfs的注冊在 net/Socket.c裡。
register_filesystem(&sock_fs_type);
socket文件系統的函數也是在net/Socket.c裡:
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.open = sock_no_open, /* special open code to disallow open via /proc */
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
從sock_poll跟隨下去,
最後可以到 net/ipv4/tcp.c的
unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
這個是最終的查詢函數,
也就是說select 的核心功能是調用tcp文件系統的poll函數,不停的查詢,如果沒有想要的數據,主動執行一次調度(防止一直占用cpu),直到有一個連接有想要的消息為止。
從這裡可以看出select的執行方式基本就是不同的調用poll,直到有需要的消息為止,如果select 處理的socket很多,這其實對整個機器的性能也是一個消耗。
2、epoll的實現epoll的實現代碼在 fs/EventPoll.c下,
由於epoll涉及到幾個系統調用,這裡不逐個分析了,僅僅分析幾個關鍵點,
第一個關鍵點在
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
這是在我們調用sys_epoll_ctl 添加一個被管理socket的時候調用的函數,關鍵的幾行如下:
代碼如下:
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = tfile->f_op->poll(tfile, &epq.pt);
這裡也是調用文件系統的poll函數,不過這次初始化了一個結構,這個結構會帶有一個poll函數的callback函數:ep_ptable_queue_proc,
在調用poll函數的時候,會執行這個callback,這個callback的功能就是將當前進程添加到 socket的等待進程上。
代碼如下:
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
注意到參數 whead 實際上是 sk->sleep,其實就是將當前進程添加到sk的等待隊列裡,當該socket收到數據或者其他事件觸發時,會調用
sock_def_readable 或者sock_def_write_space 通知函數來喚醒等待進程,這2個函數都是在socket創建的時候填充在sk結構裡的。
從前面的分析來看,epoll確實是比select聰明的多、輕松的多,不用再苦哈哈的去輪詢了。