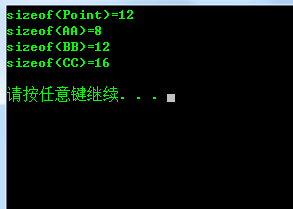
printf的格式控制的完整格式:
% - 0 m.n l或h 格式字符
下面對組成格式說明的各項加以說明:
①%:表示格式說明的起始符號,不可缺少。
②-:有-表示左對齊輸出,如省略表示右對齊輸出。
③0:有0表示指定空位填0,如省略表示指定空位不填。
④m.n:m指域寬,即對應的輸出項在輸出設備上所占的字符數。N指精度。用於說明輸出的實型數的小數位數。為指定n時,隱含的精度為n=6位。
⑤l或h:l對整型指long型,對實型指double型。h用於將整型的格式字符修正為short型。
---------------------------------------
格式字符
格式字符用以指定輸出項的數據類型和輸出格式。
①d格式:用來輸出十進制整數。有以下幾種用法:
%d:按整型數據的實際長度輸出。
%md:m為指定的輸出字段的寬度。如果數據的位數小於m,則左端補以空格,若大於m,則按實際位數輸出。
%ld:輸出長整型數據。
②o格式:以無符號八進制形式輸出整數。對長整型可以用"%lo"格式輸出。同樣也可以指定字段寬度用“%mo”格式輸出。
例:
代碼如下:
main()
{
int a = -1;
printf("%d, %o", a, a);
}
運行結果:-1,177777
程序解析:-1在內存單元中(以補碼形式存放)為(1111111111111111)2,轉換為八進制數為(177777)8。
③x格式:以無符號十六進制形式輸出整數。對長整型可以用"%lx"格式輸出。同樣也可以指定字段寬度用"%mx"格式輸出。
④u格式:以無符號十進制形式輸出整數。對長整型可以用"%lu"格式輸出。同樣也可以指定字段寬度用“%mu”格式輸出。
⑤c格式:輸出一個字符。
⑥s格式:用來輸出一個串。有幾中用法
%s:例如:printf("%s", "CHINA")輸出"CHINA"字符串(不包括雙引號)。
%ms:輸出的字符串占m列,如字符串本身長度大於m,則突破獲m的限制,將字符串全部輸出。若串長小於m,則左補空格。
%-ms:如果串長小於m,則在m列范圍內,字符串向左靠,右補空格。
%m.ns:輸出占m列,但只取字符串中左端n個字符。這n個字符輸出在m列的右側,左補空格。
%-m.ns:其中m、n含義同上,n個字符輸出在m列范圍的左側,右補空格。如果n>m,則自動取n值,即保證n個字符正常輸出。
⑦f格式:用來輸出實數(包括單、雙精度),以小數形式輸出。有以下幾種用法:
%f:不指定寬度,整數部分全部輸出並輸出6位小數。
%m.nf:輸出共占m列,其中有n位小數,如數值寬度小於m左端補空格。
%-m.nf:輸出共占n列,其中有n位小數,如數值寬度小於m右端補空格。
⑧e格式:以指數形式輸出實數。可用以下形式:
%e:數字部分(又稱尾數)輸出6位小數,指數部分占5位或4位。
%m.ne和%-m.ne:m、n和”-”字符含義與前相同。此處n指數據的數字部分的小數位數,m表示整個輸出數據所占的寬度。
⑨g格式:自動選f格式或e格式中較短的一種輸出,且不輸出無意義的零。
---------------------------------------
關於printf函數的進一步說明:
如果想輸出字符"%",則應該在“格式控制”字符串中用連續兩個%表示,如:
printf("%f%%", 1.0/3);
輸出0.333333%。
---------------------------------------
對於單精度數,使用%f格式符輸出時,僅前7位是有效數字,小數6位.
對於雙精度數,使用%lf格式符輸出時,前16位是有效數字,小數6位.
######################################拾遺########################################
由高手指點
對於m.n的格式還可以用如下方法表示(例)
char ch[20];
printf("%*.*s\n",m,n,ch);
前邊的*定義的是總的寬度,後邊的定義的是輸出的個數。分別對應外面的參數m和n 。我想這種方法的好處是可以在語句之外對參數m和n賦值,從而控制輸出格式。
%n 可以將所輸出字符串的長度值賦绐一個變量, 見下例:
int slen;
printf("hello world%n", &slen);
執行後變量被賦值為11。
又查了一下, 看到一篇文章(查看)說這種格式輸出已經確認為一個安全隱患,並且已禁用。再搜搜果然這種用法都被用來搞什麼溢出、漏洞之類的,隨便找了一個:格式化字符串攻擊筆記。
------------------------------------------
%p格式用來以十六進制整數形式輸出內存地址
代碼如下:
#include <stdio.h>
extern int etext, edata, end;
int main(void)
{
printf("etext: \t%p\n", &etext);
printf("edata: \t%p\n", &edata);
printf("end: \t%p\n", &end);
return(0);
}
在鏈接過程中,鏈接器ld和ld86會使用變量記錄下執行程序中每個段的邏輯地址。因此在程序中可以通過訪問這幾個外部變量來獲得程序中段的位置。鏈接器預定義的外部變量通常至少有etext、_etext、edata、_edata、end和_end。
變量名_etext和etext的地址是程序正文段結束後的第1個地址;_edata和edata的地址是初始化數據區後面的第1個地址;_end和 end的地址是未初始化數據區(bss)後的第1個地址位置。帶下劃線'_'前綴的名稱等同於不帶下劃線的對應名稱,它們之間的唯一區別在於ANSI、 POSIX等標准中沒有定義符號etext、edata和end。
當程序剛開始執行時,其brk所指位置與_end處於相同位置。但是系統調用sys_brk()、內存分配函數malloc()以及標准輸入/輸出等 操作會改變這個位置。因此程序當前的brk位置需要使用sbrk()來取得。注意,這些變量名必須看作是地址。因此在訪問它們時需要使用取地址前綴 '&',例如&end等。例如:
extern int _etext;
int et;
(int *) et = &_etext; // 此時et含有正文段結束處後面的地址。
下面程序predef.c可用於顯示出這幾個變量的地址。可以看出帶與不帶下劃線'_'符號的地址值是相同的。
代碼如下:
/*
Print the symbols predefined by linker.
*/
extern int end, etext, edata;
extern int _etext, _edata, _end;
int main(void)
{
printf("&etext=%p, &edata=%p, &end=%p\n", &etext, &edata, &end);
printf("&_etext=%p, &_edata=%p, &_end=%p\n", &_etext, &_edata, &_end);
return 0;
}
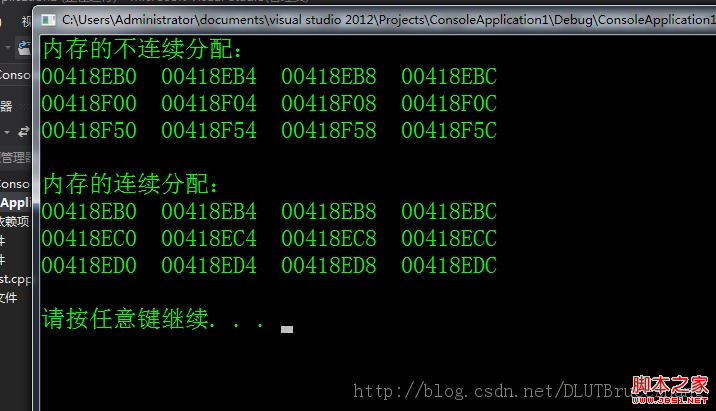
在Linux 0.1X系統下運行該程序可以得到以下結果。請注意,這些地址都是程序地址空間中的邏輯地址,即從執行程序被加載到內存位置開始算起的地址。
[/usr/root]# gcc -o predef predef.c
[/usr/root]# ./predef
&etext=4000, &edata=44c0, &end=48d8
&_etext=4000, &_edata=44c0, &_end=48d8
[/usr/root]#
如果在現在的Linux系統(例如RedHat 9)中運行這個程序,就可得到以下結果。我們知道現在Linux系統中程序代碼從其邏輯地址0x08048000處開始存放,因此可知這個程序的代碼段長度是0x41b字節。
[root@plinux]# ./predef
&etext=0x804841b, &edata=0x80495a8, &end=0x80495ac
&_etext=0x804841b, &_edata=0x80495a8, &_end=0x80495ac
[root@plinux]#
Linux 0.1x內核在初始化塊設備高速緩沖區時(fs/buffer.c),就使用了變量名_end來獲取內核映像文件Image在內存中的末端後的位置,並從這個位置起開始設置高速緩沖區。
附:
C51 printf函數
The optional characters l or L may immediately precede the type character to respectively specify long types for d, i, u, o, x, and X.
The optional characters b or B may immediately precede the type character to respectively specify char types for d, i, u, o, x, and X.
printf("%bx",(char)i);
如果是
int a; 可以sprintf(buf,"%d",a),結果正確
char a,就必須sprintf(buf,"bd",a)
如果在浮點數中,則可以sprintf(buf,"%1.3f",a)
printf("%02BX%02BX\n", adch, adcl)怎麼解釋呢?是應該是C51上的表達方式