用於內存管理的malloc與free這對函數,對於使用C語言的程序員應該很熟悉。前段時間聽說有的IT公司以“實現一個簡單功能的malloc”作為面試題,正好最近在復習K&R,上面有所介紹,因此花了些時間仔細研究了一下。畢竟把題目做出來是次要的,了解實現思想、提升技術才是主要的。本文主要是對malloc與free實現思路的介紹,藍色部分文字是在個人思考中覺得比較核心的東西;另外對於代碼的說明,有一些K&R上的解釋,使用綠色加亮。
在研究K&R第八章第五節的實現之前,不妨先看看其第五章第四節的alloc/afree實現,雖然這段代碼主要目的是展示地址運算。
代碼如下:
alloc實現
#define ALLOCSIZE 10000
static char allocbuf[ALLOCSIZE]; /*storage for alloc*/
static char *allocp = allocbuf; /*next free position*/
char *alloc(int n)
{
if(allocbuf+ALLOCSIZE - allocp >= n) {
allocp += n;
return alloc - n;
} else
return 0;
}
void afree(char *p)
{
if (p >= allocbuf && p<allocbuf + ALLOCSIZE)
allocp = p;
}
這種簡單實現的缺點:
1.作為代表內存資源的allocbuf,其實是預先分配好的,可能存在浪費。
2.分配和釋放的順序類似於棧,即“後進先出”,釋放時如果不按順序會造成異常。
這個實現雖然比較簡陋,但是依然提供了一個思路。如果能把這兩個缺點消除,就能夠實現比較理想的malloc/free。
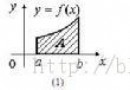
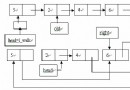
僅僅依靠地址運算來進行定位,是限制分配回收靈活性的原因,它要求已使用部分和未使用部分必須通過某個地址分開成兩個相鄰區域。為了能讓這兩個區域能夠互相交錯,甚至其中還包括一些沒有分配的地址空間,需要使用指針把同類的內存空間連接起來形成鏈表,這樣就可以處理地址不連續的一系列內存空間。但是為什麼只連接了空閒空間而不連接使用中的空間?這麼問可能出於在對圖中二者類比時的直覺而沒有經過思考,這很簡單,因為沒有必要。前者相互鏈接是為了能夠在內存分配時遍歷所有空閒空間,並且在使用free()回收已使用空間時進行重新插入。而對於使用中的空間,由於我們在分配空間時已經知道它們的地址了,回收時可以直接告訴free(),並不用像malloc()時進行遍歷。
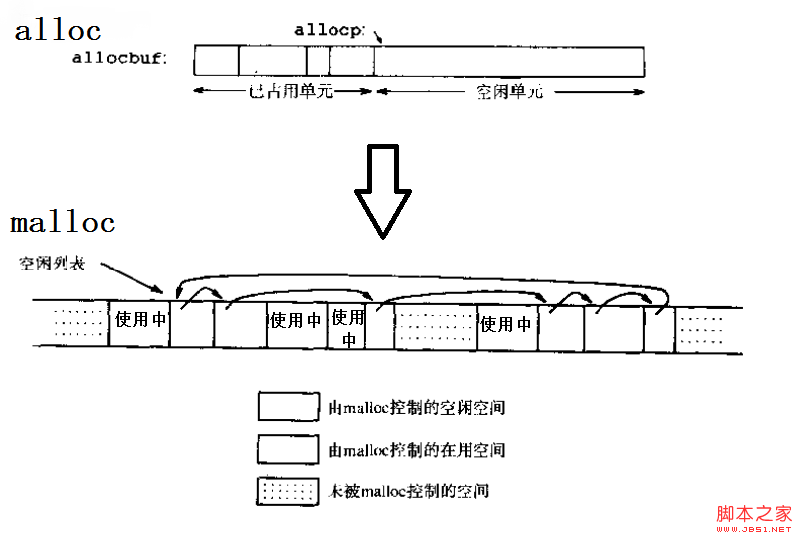
既然提到了鏈表,可能對數據結構稍有了解的人會立刻寫下一個struct來代表一個內存區域,其中包含一個指向下一個內存區域的指針,但是這個struct的其他成員該怎麼寫呢?作為待分配的內存區域,大小是不定的,如果把它聲明為struct的成員變量顯然不妥;如果聲明為一個指向某個其他的區域的指針,這似乎又和上面的直觀表示不相符合。(當然,這麼做也是可以實現的,它看上去是介於上圖的兩者之間,把管理結構和實際分配的空間相剝離,在文末我會專門的討論一下這種實現方法)因此,這裡仍然把控制結構和空閒空間相分開,但保持它們在內存地址中相鄰,形成下圖的形式,而正由這個特點,我們可以利用對控制結構指針的指針運算來定位對應的內存區域:
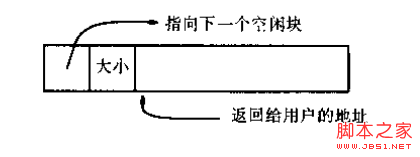
對應地,把控制信息定義為Header:
代碼如下:
typedef long Align;/*for alignment to long boundary*/
union header {
struct {
union header *ptr; /*next block if on free list*/
unsigned size; /*size of this block*/
} s;
Align x;
};
typedef union header Header;
這樣,malloc的主要工作就是對這些Header和其後的內存塊的管理。
代碼如下:
malloc()
static Header base;
static Header *freep = NULL;
void *malloc(unsigned nbytes)
{
Header *p, *prevp;
unsigned nunits;
nunits = (nbytes+sizeof(Header)-1)/sizeof(Header) + 1;
if((prevp = freep) == NULL) { /* no free list */
base.s.ptr = freep = prevp = &base;
base.s.size = 0;
}
for(p = prevp->s.ptr; ;prevp = p, p= p->s.ptr) {
if(p->s.size >= nunits) { /* big enough */
if (p->s.size == nunits) /* exactly */
prevp->s.ptr = p->s.ptr;
else {
p->s.size -= nunits;
p += p->s.size;
p->s.size = nunits;
}
freep = prevp;
return (void*)(p+1);
}
if (p== freep) /* wrapped around free list */
if ((p = morecore(nunits)) == NULL)
return NULL; /* none left */
}
}
實際分配的空間是Header大小的整數倍,並且多出一個Header大小的空間用於放置Header。但是直觀來看這並不是nunits = (nbytes+sizeof(Header)-1)/sizeof(Header) + 1啊?如果用(nbytes+sizeof(Header))/sizeof(Header)+1豈不是剛好?其實不是這樣,如果使用後者,nbytes+sizeof(Header)%sizeof(Header) == 0時,又多分配了一個Header大小的空間了,因此還要在小括號裡減去1,這時才能符合要求。
malloc()第一次調用時建立一個退化鏈表base,只有一個大小是0的空間,並指向它自己。freep用於標識空閒鏈表的某個元素,每次查找時可能發生變化;中間的查找和分配過程是基本的鏈表操作,在空閒鏈表中不存在合適大小的空閒空間時調用morecore()獲得更多內存空間;最後的返回值是空閒空間的首地址,即Header之後的地址,這個接口與庫函數一致。
代碼如下:
morecore()
#define NALLOC 1024 /* minimum #units to request */
static Header *morecore(unsigned nu)
{
char *cp;
Header *up;
if(nu < NALLOC)
nu = NALLOC;
cp = sbrk(nu * sizeof(Header));
if(cp == (char *)-1) /* no space at all*/
return NULL;
up = (Header *)cp;
up->s.size = nu;
free((void *)(up+1));
return freep;
}
morecore()從系統申請更多的可用空間,並加入。由於調用了sbrk(),系統開銷比較大,為避免morecore()本身的調用次數,設定了一個NALLOC,如果每次申請的空間小於NALLOC,就申請NALLOC大小的空間,使得後續malloc()不必每次都需要調用morecore()。對於sbrk(),在後面會有介紹。
這裡有個讓人驚訝的地方:malloc()調用了morecore(),morecore()又調用了free()!第一次看到這裡時可能會覺得不可思議,因為按照慣性思維,malloc()和free()似乎應該是相互分開的,各司其職啊?但請再思考一下,free()是把空閒鏈表進行擴充,而malloc()在空閒鏈表不足時,從系統申請到更多內存空間後,也要先把它們轉化成空閒鏈表的一部分,再進行利用。這樣,malloc()調用free()完成後面的工作也是順理成章了。根據這個思想,後面是free()的實現。在此之前,還有幾個morecore()自身的細節:
1.如果系統也沒有空間可以分配,sbrk()返回-1。cp是char *類型,在有的機器上char無符號,這裡需要一次強制類型轉換。
2.morecore()調用的返回值看上去比較奇怪,別擔心,freep會在free()中修改的。使用這個返回值也是為了在malloc()裡的判斷、p = freep的再次賦值的語句能夠緊湊。
代碼如下:
free()
void free(void *ap)
{
Header *bp,*p;
bp = (Header *)ap -1; /* point to block header */
for(p=freep;!(bp>p && bp< p->s.ptr);p=p->s.ptr)
if(p>=p->s.ptr && (bp>p || bp<p->s.ptr))
break; /* freed block at start or end of arena*/
if (bp+bp->s.size==p->s.ptr) { /* join to upper nbr */
bp->s.size += p->s.ptr->s.size;
bp->s.ptr = p->s.ptr->s.ptr;
} else
bp->s.ptr = p->s.ptr;
if (p+p->s.size == bp) { /* join to lower nbr */
p->s.size += bp->s.size;
p->s.ptr = bp->s.ptr;
} else
p->s.ptr = bp;
freep = p;
}
free()首先定位要釋放的ap對應的bp與空閒鏈表的相對位置,找到它的的最近的上一個和下一個空閒空間,或是當它在整個空閒空間的前面或後面時找到空閒鏈表的首尾元素。注意,由於malloc()的分配方式和free()的回收時的合並方式(下文馬上要提到),可以保證整個空閒空間的鏈表總是從低地址逐個升高,在最高地址的空閒空間回指向低地址第一個空閒空間。
定位後,根據要釋放的空間與附近空間的相鄰性,進行合並,也即修改對應空間的Header。兩個if並列可以使得bp可以同時與高地址和低地址空閒空間結合(如果都相鄰),或者進行二者之一的合並,或者不合並。
完成了這三部分代碼後(注意放到同一源文件中,sbrk()需要#include <unistd.h>),就可以使用了。當然要注意,命名和stdlib.h中的同名函數是沖突的,可以自行改名。
第一次審視源碼,會發現很多實現可能原先並沒有想到:Header的結構和對齊填充、空間的取整、鏈表的操作和初始化(邊界情況)、malloc()對free()的調用、由malloc()和free()暗中保證的鏈表地址有序等等,確實很值得玩味。另外再附上前文中提到的兩個問題還有一些補充問題的簡單思考:
1.Header與空閒空間相剝離,Header中包含一個指向其空閒空間的指針
這樣做未必不可,相應地算法需要改動。同時,由於Header和空閒空間不再相鄰,sbrk()獲得的空間也應該包含Header的部分,內存的分布可能會更加瑣碎。當然,這也可能帶來好處,即用其他數據結構對鏈表進行管理,比如按大小進行hash,這樣查找起來更快。
2.關於sbrk()
sbrk()也是庫函數,它能使堆往棧的方向增長,具體可以參考:brk(), sbrk() 用法詳解。
3.可以改進的方
空閒空間的尋找是線性的,查找過程在內存分配中可以看作是循環首次適應算法,在某些情況下可能很慢;如果再建立一個數據結構,如hash表,對不同大小的空間進行索引,肯定可以加快查找本身,並且能實現一些算法,比如最佳匹配。但查找加快的代價是,修改這個索引會占用額外的時間,這是需要權衡的。
morecore()中的最小分配空間是宏定義,在實際使用中完全可以作為參數傳遞,根據需要設定最小分配下限。