12. 基本數據類型:整型(下)
1. 輸出各種整數類型的變量
輸出不同類型的整數,需要使用不用的格式限定符。輸出 unsigned int 類型的整數,要用 %u 。輸出 long ,要用 %ld;如果要以十六進制或者八進制形式輸出,那就用 %lx(或者%lX)或者 %lo。注意:雖然整數常量的後綴使用大寫或者小寫英文字母都沒關系,但是它們格式限定符必須使用小寫!如果我們要輸出 short 類型的整數,可以在 %d 中間加上前綴 h,也就是%hd;同理,%ho 和 %hx(或者 %hX )分別表示以八進制或十六進制形式輸出。前綴 h 和 l 可以和 u 組合,表示輸出無符號整數。例如:%lu 表示輸出 unsigned long 類型的整數;%hu 表示輸出unsigned short類型的整數。如果您的編譯器支持C99,可以使用 %lld 和 %llu 分別表示輸出 long long 和 unsigned long long 。下面我們來看一個輸出各種類型整數的程序:
#include <stdio.h>
int main(void)
{
unsigned int un = 3000000000; /* 我使用的編譯器 int 是 32 位的 */
short end = 200; /* 而 short 是 16 位的 */
long big = 65537;
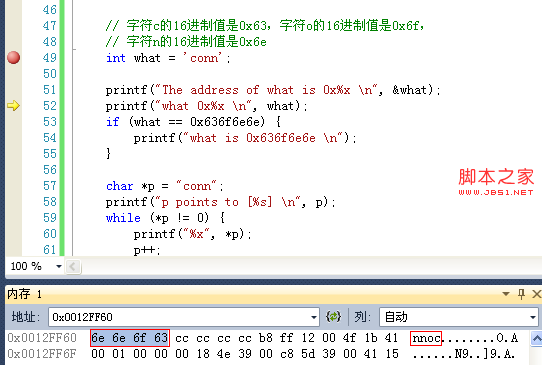
printf("un = %u and not %d\n", un, un);
printf("end = %hd and %d\n", end, end);
printf("big = %ld and not %hd\n", big, big);
printf("Press ENTER to quit...");
getchar();
return 0;
}
使用 Dev-C++ 編譯運行這個程序輸出結果如下:
un = 3000000000 and not -1294967296
end = 200 and 200
big = 65537 and not 1
Press ENTER to quit...
這個程序表明,錯誤使用格式限定符會導致意想不到的輸出。首先,錯誤使用 %d 來做無符號整型變量 un 的格式限定符,導致輸出的是負數。這是因為我的計算機使用相同的二進制形式來表示 3000000000 和 -129496296 ,而計算機只認識二進制。所以,如果我們使用 %u 告訴 printf 輸出無符號整數,輸出的就是 3000000000;如果我們誤用了 %d,那麼輸出的就是一個負數。不過,如果我們把代碼中的 3000000000 改成 96 的話,輸出就不會出現異常。因為 96 沒有超出 int 的表示范圍。
然後,對於第二個 printf,無論我們使用 %hd 還是 %d,輸出的結果都是一樣的。這是因為 C 語言標准規定,當 short 類型值傳遞給函數時,要自動轉化成 int 類型值。之所以轉化成 int,是因為 int 被設計為計算機處理效率最高的整數類型。所以,對於 short 和 int 大小不同的計算機來說,把變量 end 轉化成 int 類型再傳遞給函數,速度更快。如此說來,h 好像沒有存在意義。其實不然。我們可以用 %hd 來看看較大的整數類型被截斷成 short 類型的時候會是什麼樣的。
而第三個printf,由於誤用%hd,導致輸出是1。這是因為,如果long是32位的話,65537的二進制形式便是 0000 0000 0000 0001 0000 0000 0000 0001,而 %hd 命令 printf 輸出 short 類型的值,從而導致 printf 只對後 16 位進行處理,最終導致輸出 1。
在前面的教程裡,我們說過,保證格式限定符的數目和參數數目一致是我們的責任。同樣,保證格式限定符的類型和參數類型一致也是我們的責任!正如上面所說的那樣,錯誤使用格式限定符會導致意想不到的輸出!
2. 整數溢出
首先請看以下程序:
#include <stdio.h>
int main(void)
{
/* 32 位 int 表示范圍的上限和下限 */
int i = 2147483647, j = -2147483648;
unsigned int k = 4294967295, l = 0;
printf("%d %d %d %d\n", i, i+1, j, j-1);
printf("%u %u %u %u %u\n", k, k+1, k+2, l, l-1);
printf("Press ENTER to quit...");
getchar();
return 0;
}
使用 Dev-C++ 編譯運行這個程序輸出結果如下:
2147483647 -2147483648 -2147483648 2147483647
4294967295 0 1 0 4294967295
Press ENTER to quit...
這個程序中,i+1 是負數,j-1 是正數,k+1 是 0,l-1 是 4294967295 。這是因為加減運算過後,它們的值超出了它們對應的那種整數類型的表示范圍,我們把這種現象稱為溢出。
unsigned int 型變量的值如果超過了上限,就會返回 0,然後從 0 開始增大。如果小於 0,那麼就會到達 unsigned 型的上限,然後從上限開始減小。就好像一個人繞著跑道跑步一樣,繞了一圈,又返回出發點。int 型變量溢出的話,會變成負數,或者正數。
對於 unsigned 類型的整數,它們溢出時的情況一定和上面描述的一樣,這是標准規定的。但是標准並沒有規定有符號整數溢出時會出現什麼情況。這裡描述的有符號整數溢出時出現的情況是最常見的,但是在別的計算機,使用別的編譯器,也可能出現不同的情況。
1. 長度限制
C89 規定,編譯器至少應該能夠處理 31 個字符(包括 31)以內的內部標識符(internal identifier);而對於外部標識符(external identifier),編譯器至少應該能夠處理 6 個字符(包括 6)以內的外部標識符。所謂標識符,是指我們為變量(variable)、宏(macro),或者函數(function)等等取的名字。例如 int num; 這個語句中的 num 就是一個標識符。
最新的 C99 標准規定,編譯器至少應該能夠處理 63 個字符(包括 63)以內的內部標識符;編譯器至少應該能夠處理 31 個字符(包括 31)以內的外部標識符。
事實上,我們可以使用超出最大數目限制的字符來命名標識符,不過編譯器會忽略超出的那部分字符。也就是說,如果我們用 35 個字符來命名變量,而那個編譯器最多只能處理 31 個字符的變量名的話,那麼多出的那 4 個字符就會被編譯器忽略,只有前面的 31 個字符有效。有些古老的編譯器只能處理 8 個字符以內的標識符,對於這樣的編譯器來說,標識符 kamehameha 和 kamehameko 是等價的,因為它們前面 8 個字符相等。
2. 可用字符和組合規則
標准規定,標識符只能由大小寫英文字母,下劃線(_),以及阿拉伯數字組成。標識符的第一個字符必須是大小寫英文字母或者下劃線,而不能是數字。
合法命名 非法命名
wiggles $Z]** /* $、] 和 * 都是非法字符 */
cat2 2cat /* 不能以數字開頭 */
Hot_Tub Hot-Tub /* - 是非法字符 */
taxRate tax rate /* 不能有空格 */
_kcab don't /* ' 是非法字符 */
操作系統和 C 語言標准庫裡的標識符一般以下劃線開頭,這是約定俗成的。因此,我們應該避免使用下劃線作為我們自己定義的標識符的開頭。
C 語言是大小寫敏感的語言,也就是說,star、Star、sTar,stAr 和 STAR 等都是相互不同的標識符。
我們不能用關鍵字和保留標識符來給我們自定義的變量命名。關於關鍵字和保留標識符,請點擊 關鍵字和保留標識符