1、如何區分宏定義中的“宏名稱”和“宏字符串”?對於帶參數的宏又該注意什麼?
在宏定義中,“宏名稱”和“宏字符串”是通過“空格”來區分的。編譯器在處理時宏定義時,首先從“#define”後第一個空格開始讀取字符串,直到遇見下一個空格為止,兩個空格之間的字符串為“宏名稱”,確定好“宏名稱”之後,本行的所有其他字符串都為“宏字符串”。圖示:#define + N個空格(1 < N) + 宏名稱(中間沒有空格) + N個空格(1 < N) + 宏字符串(直到本行結束)。這裡講到的都是一行之內的宏定義,如果跨越多行則用“\”字符進行“續行”,本質上可以當做一行來對待。
對於“帶參數宏”,宏名稱和“( )”之間不能有空格,否則就變成了“無參數宏”(根據上面的原則)。而且當“無參數宏”和“帶參數宏”的名字相同時,“無參數宏”會屏蔽掉“帶參數宏”,即使以“帶參數宏”的方式調用,也行不通。
試驗內容及結果:
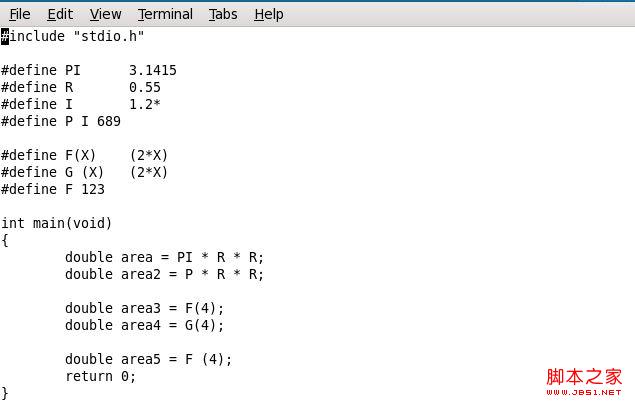

實驗分析:
可以看到“#define PI 3.1415”和“#define P I 689”分別是兩個不同的宏定義“PI”和“P”;"G(4)"被“(X) (2*X) (4)”替換掉;當調用“F(4)”時,系統並沒有替換成“2*4”,而是替換成了“123(4)”,說明“#define F 123”完全屏蔽掉了“#define F(X) (2*X)”,當注釋掉“#define F 123”後"#define F(X) (2*X)"可以正常工作。因此,在進行宏定義時,要密切關注空格的影響,並且“帶參數宏”和“無參數宏”的名稱一定不能相同,否則會出現混亂。但是,在宏調用時空格並不影響效果,例如F(3)和F (3)效果相同(F(X)是帶參數宏)。
2、宏和函數在使用方式和效果上有何異同?
在宏定義時,要善於利用括號對變量進行封裝,把每個參數都括起來,預防出現與優先級有關的問題;同時整個結果表達式也應該括起來,以防止當宏用於一個更復雜的表達式時可能出現問題。盡量提高宏的可靠性,。例如:“#define ABS(x) (((x) > 0) ? (x) : (-x))”的可靠性要遠遠優於“#define ABS(x) x > 0 ? x : -x”,可以以ABS(a-b)來進行試驗。
在宏調用時,如果有自增(++)或自減(--)操作符,一定要注意很可能會產生副作用。因為宏在替換時,如果變量出現了多次,就相當於自增或自減操作進了多次,這個跟函數調用是完全不同的,函數調用中形參會復制實參的數值,並對形參進行操作並不會影響實參,而宏調用就是直接多次修改實參。例如:a = 5; "ABS(a++) “展開後就變成“(((a++) > 0) ? (a++) : (-a++))”,操作完成後”a = 7“而不是”a = 6“;當寫成函數就完全不用擔心這個問題。
如果在宏調用時,進行了了多層嵌套調用,則宏展開後會產生非常龐大的表達式,而且相當復雜;函數調用則不會出現這種情況。
3、宏和類型定義typedef的區別
由於宏的本質就是替換,所以可以對變量類型進行一層封裝,利用該封裝做變量定義,這樣做的好處是增加可移植性,當修改時只需要改動宏定義即可。例如:
代碼如下:
MY_TYPE a;
MY_TYPE b,c,d;
但是最好不要這麼用,因為我們有typedef,它是專門進行類型定義的。而且,使用類型定義會使代碼更加通用一些,避免一些深層的問題。例如:
代碼如下:
typedef uint_8 * MY_TYPE2
MY_TYPE1 a,b;
MY_TYPE2 c,d;
分析:
從概念上看,MY_TYPE1 和 MY_TYPE2 完全相同,都是指向uint_8的指針,但是當我們聲明多個變量時,就出現問題了。它們分別被擴展成了:
代碼如下:
uint_8 *a,b;
MY_TYPE2 c,d; //因為MY_TYPE2已經是一種類型了
可以看到,本來想定義兩個指針變量a,b;現在卻變成了一個指針變量a和一個整型變量b,這不是我們想要的。而MY_TYPE2本身就是一種類型(自定義)了,故c,d都是指針類型,符合預期。所以,如果想自定義類型,果斷選擇 ”typedef“ 放棄宏定義,否則吃虧的是自己。