計算機中所有的數據都必須放在內存中,不同類型的數據占用的字節數不一樣,例如 int 占用4個字節,char 占用1個字節。為了正確地訪問這些數據,必須為每個字節都編上號碼,就像門牌號、身份證號一樣,每個字節的編號是唯一的,根據編號可以准確地找到某個字節。
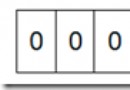
下圖是 4G 內存中每個字節的編號(以十六進制表示):
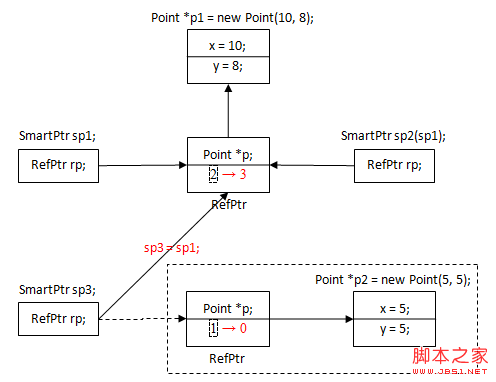
我們將內存中字節的編號稱為地址(Address)或指針(Pointer)。地址從 0 開始依次增加,對於 32 位環境,程序能夠使用的內存為 4GB,最小的地址為 0,最大的地址為 0XFFFFFFFF。
下面的代碼演示了如何輸出一個地址:
#include <stdio.h>
int main(){
int a = 100;
char str[20] = "c.biancheng.net";
printf("%#X, %#X\n", &a, str);
return 0;
}
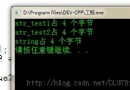
運行結果:
0X28FF3C, 0X28FF10
%#X表示以十六進制形式輸出,並附帶前綴
0X。a 是一個變量,用來存放整數,需要在前面加
&來獲得它的地址;str 本身就表示字符串的首地址,不需要加
&。
一切都是地址
C語言用變量來存儲數據,用函數來定義一段可以重復使用的代碼,它們最終都要放到內存中才能供 CPU 使用。
數據和代碼都以二進制的形式存儲在內存中,計算機無法從格式上區分某塊內存到底存儲的是數據還是代碼。當程序被加載到內存後,操作系統會給不同的內存塊指定不同的權限,擁有讀取和執行權限的內存塊就是代碼,而擁有讀取和寫入權限(也可能只有讀取權限)的內存塊就是數據。
CPU 只能通過地址來取得內存中的代碼和數據,程序在執行過程中會告知 CPU 要執行的代碼以及要讀寫的數據的地址。如果程序不小心出錯,或者開發者有意為之,在 CPU 要寫入數據時給它一個代碼區域的地址,就會發生內存訪問錯誤。這種內存訪問錯誤會被硬件和操作系統攔截,強制程序崩潰,程序員沒有挽救的機會。
CPU 訪問內存時需要的是地址,而不是變量名和函數名!變量名和函數名只是地址的一種助記符,當源文件被編譯和鏈接成可執行程序後,它們都會被替換成地址。編譯和鏈接過程的一項重要任務就是找到這些名稱所對應的地址。
假設變量 a、b、c 在內存中的地址分別是 0X1000、0X2000、0X3000,那麼加法運算
c = a + b;將會被轉換成類似下面的形式:
0X3000 = (0X1000) + (0X2000);
( )表示取值操作,整個表達式的意思是,取出地址 0X1000 和 0X2000 上的值,將它們相加,把相加的結果賦值給地址為 0X3000 的內存
變量名和函數名為我們提供了方便,讓我們在編寫代碼的過程中可以使用易於閱讀和理解的英文字符串,不用直接面對二進制地址,那場景簡直讓人崩潰。
需要注意的是,雖然變量名、函數名、字符串名和數組名在本質上是一樣的,它們都是地址的助記符,但在編寫代碼的過程中,我們認為變量名表示的是數據本身,而函數名、字符串名和數組名表示的是代碼塊或數據塊的首地址。
關於程序內存、編譯鏈接、可執行文件的結構以及如何找到名稱對應的地址,我們將在《C語言內存》和《C語言模塊化開發》專題中深入探討。