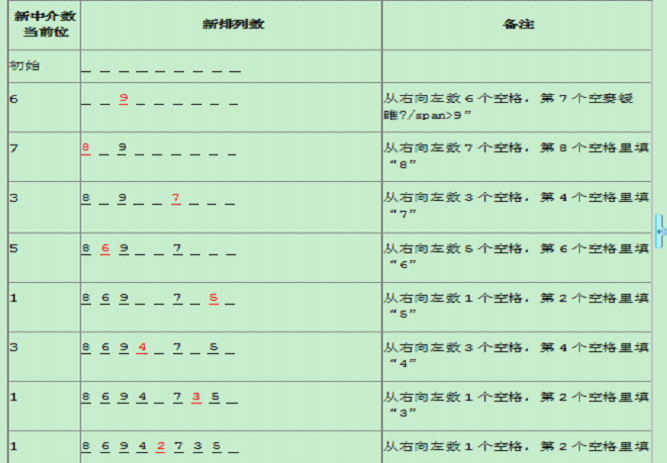
前面我們已經講到,計算機是以二進制的形式來存儲數據的,它只認識0和1兩個數字,我們在屏幕上看到的文字,在存儲到內存之前也都被轉換成了二進制(0和1序列)。
可想而知,特定的文字必然對應著固定的二進制,否則將無法轉換。那麼,怎樣將文字與二進制對應呢?這就需要有一套規范,計算機公司和軟件開發者都必須遵守。
ASCII碼
我們知道,一個二進制位(Bit)有0、1兩種狀態,一個字節(Byte)有8個二進制位,有256種狀態,每種狀態對應一個符號,就是256個符號,從00000000到11111111。
計算機誕生於美國,早期的計算機使用者大多使用英文,上世紀60年代,美國制定了一套英文字符與二進制位的對應關系,稱為ASCII碼,沿用至今。
ASCII碼規定了128個英文字符與二進制的對應關系,占用一個字節(實際上只占用了一個字節的後面7位,最前面1位統一規定為0)。例如,字母 a 的的ASCII碼為 01100001,那麼你暫時可以理解為字母 a 存儲到內存之前會被轉換為 01100001,讀取時遇到 01100001 也會轉換為 a。
完整的ASCII碼表請查看:http://www.asciima.com/
Unicode編碼
隨著計算機的流行,使用計算機的人越來越多,不僅限於美國,整個世界都在使用,這個時候ASCII編碼的問題就凸現出來了。
ASCII編碼只占用1個字節,最多只能表示256個字符,我大中華區10萬漢字怎麼表示,日語韓語拉丁語怎麼表示?所以90年代又制定了一套新的規范,將全世界范圍內的字符統一使用一種方式在計算機中表示,這就是Unicode編碼(Unique Code),也稱統一碼、萬國碼。
Unicode 是一個很大的集合,現在的規模可以容納100多萬個符號,每個符號的對應的二進制都不一樣。Unicode 規定可以使用多個字節表示一個字符,例如 a 的編碼為 01100001,一個字節就夠了,”好“的編碼為 01011001 01111101,需要兩個字節。
為了兼容ASCII,Unicode 規定前0~127個字符與ASCII是一樣的,不一樣的只是128~255的這一段。
如果你希望將字符轉換為Unicode編碼,請查看:http://tool.chinaz.com/Tools/Unicode.aspx
完整的Unicode編碼請查看:unicode.org