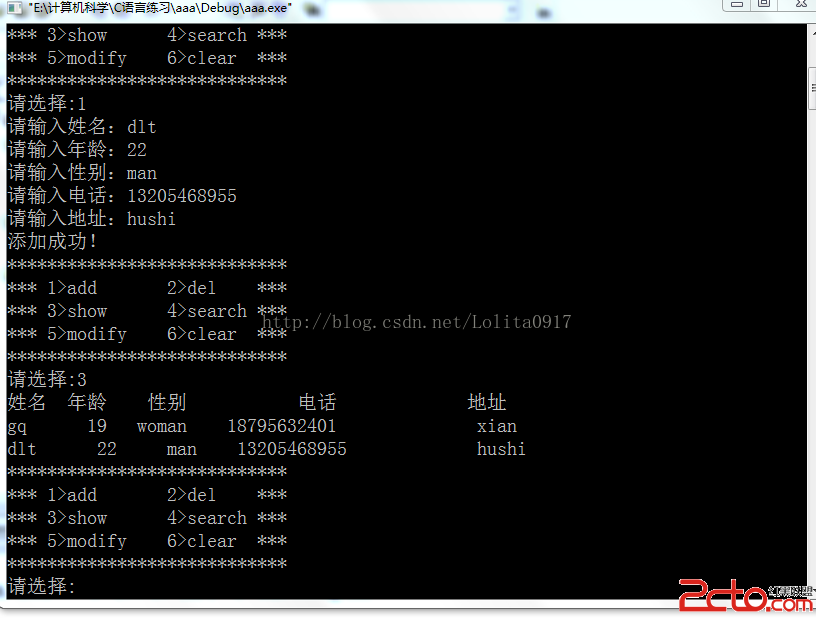
int ch
while( (ch = getchar()) != EOF && ch != ‘\n’);
這個地方首先要注意的是賦值運算符的優先級比比較運算符的優先給低,所以ch = getchar()需要用括號括起來,另外這裡的ch被定義為int型,因為getchar()的返回值為整型,另外,EOF為一個整型常量(在stdio.h中定義)
上面中的那個語句也可以按如下寫:
ch = getchar();
While(ch != EOF && ch != ‘\n’)
ch = getchar();
char input[50];
while ( gets(input) != NULL);
上面這句話實際上是有問題的,因為gets()不會對input數組的溢出做檢查,所以當輸入一行的字符特別多時,就會出錯.
三字母詞,
下面例出的是一些三字母詞,及其所代表的字符:
??( [ ??< { ??= #
??) ] ??> } ??/ \
??! | ??’ ^ ??- ~
如printf(“??(”);輸出的結果為: [
字符在本質上是小整型值,缺省的char要麼是signed char,要麼是unsigned,這取決於編譯器.這個事實意味著不同的機器上的char可能擁有不同范圍的值,所以,只有當程序所使用的char型變量的值位於singned char和unsigned char的交集中,這個程序才是可移植的.例如ASCII字符集中的字符都是位於這個范圍之內的.
在一個把字符當作小整型值的程序中,如果顯式地把這類變量聲明為signed或unsigned,可以提高這類程序的可移植性.另外,許多處理字符的庫函數把它們摻數聲明為char,如果你把參數顯示聲明為unsigned char 或signed char,可能會帶來兼容性問題.
聲明指針
int *a;
上面這條語句表示表達式*a產生的結果類型是int.知道了*操作符執行的是間接訪問操作後,我們可以推斷a肯定是一個指向int的指針.
Int* a;這個聲明與前面一個聲明具有相同的意思,而且看上去更為清楚,a被聲明為類型為int*的指針,但是,這並不是一個好的技巧,原因如下:
int* b, c, d;
上式中,*號實際上是表達式*b的一部分,只對這個標識符有用,b是一個指針,但其余兩個變量只是普通的整型.
char * message = “Hello World!”;
這種類型的聲明所面臨的一個危險是你容易誤解它的意思,在這個聲明中,看上去初始值似乎賦給表達式*message,事實上,它是賦給message本身的.換句話說,前面一個聲明相當於:
Char *message;
message = “Hello World!”;
常量:
Int const a;
Const int a;
上面兩條語句意思相同,都把a聲明為一個整數,且它的值不能修改.
int *pi;
pi是一個普通的指向整型的指針.
int const *pci;
pci是一個指向整型常量的指針.你可以修改指針的值,但你不能修改它所指向的值.
int * const cpi;
cpi是一個指向整型的常量指針.此時,指針是常量,它的值無法修改,但你可以修改它所指向的整型值.
int const * const cpci;
在cpci這個例子裡,無論是指針本身還是它所指向的值都是常量,不允許修改.
表達式語句
在C中,賦值就是一種操作,就像加減法一樣,所以賦值就在表達式內進行.你只要在表達式後面加上一個分號,就可以把表達式轉變為語句.所以下面這兩個表達式實際上是表達式語句,而不是賦值語句.
x = y + 3;
ch = getchar();
理解這一點非常重要,因為像下面這樣的語句也是完全合法的.
y + 3;
getchar();
當這些語句被執行時,表達式被求值,但它們的結果並不保存於任何地方,因為它並未使用賦值操作符.因此,第一條語句並不具備任何效果,而第二條語句則讀取輸入中的下一個字符,但接著便丟棄了.
Printf(“Hello World!\n”);
Printf()是一個函數,函數將會返回一個值(它實際所打印的字符數),但我們並不關心這個值,所以棄之不理也很正常.所謂語句”沒有效果”只是表達式的值被忽略.printf()函數所執行的是有用工作,這類作用稱為”副作用”.
還有一個例子:
a++;
這條語句並沒有賦值操作符,但它卻是一條非常合理的表達式語句.++操作符將增加變量a的值,這就是它的副作用.另外有一些具有副作用的操作符.
在switch語句中,continue語句沒有任何效果.只有當switch語句位於某個循環內部時,你才可以把continue語句放在switch語句內.在這種情況下,與其說continue語句作用於switch語句,還不如說它作用於循環.
在switch…case語句中,如果特意不要break語句,那最好是在break那裡加上一條注釋,便於以後維護!
關於移位操作:
標准說明無符號值執行的所有移位操作都是邏輯移位,但對於有符號值,到底是采用邏輯移位還是算術移位取決於編譯器.你可以編寫一個簡單的測試程序,看看你的編譯器使用哪種移位方式.但你的測試並不能保證其它編譯器也會使用同樣的方式.因此,一程序如果使用了有符號數的右移位操作,它就是不可移植的.
注意類似這種形式的移位:
a << -5;
左移-5位表示什麼呢?是表示右移5位嗎?還是根本就不移位?在某台機器上,這個表達式實際執行左移27位的操作-----你怎麼也想不出來吧!如果移位的位數比操作數的位數還要多,會發生什麼情況呢?
標准說明這類移位的行為是未定義的,所以字是由編譯器來決定的.然而,很少有編譯器設計者會清楚的說明如果發生這種情況會是怎樣,所以它的旨查很可能是沒有意義的.因此,你應該避免使用這種類型的移位,因為它們的效果是不可預測的,使用這類移位的程序是不可移植的.
賦值:
賦值也是一個表達式,是表達式就具有一個值.賦值表達式的值就是左操作數據的新值,它可以作為其他賦值操作符的操作數.如:
r = s + ( t = u – v ) /3;
再來看以前例出的一個列子:
char ch;
While ( (ch = getchar() ) != EOF)……
EOF為一個整型常量值,它需要的位數比字符值所能提供的位數要多,這也是getchar()返回一個整型值而不是字符值的原因.然而,這裡把getchar()的返回值首先存於字符型ch中將導致它被截短.然後這個被截短的值被提升為整型並與EOF比較.當這段存在錯誤的代碼在使用有符號字符集的機器上運行時,如果讀取了一個值為\377的字節時,循環將會終止,國為這個值截短再提升之後與EOF相等.當這段代碼在使用無符號的字符集的機器上運行是,這個循環將永遠不會終止!
復合賦值操作符
a += expression;
它的功能相當於下面的表達式:
a = a + (expression);
唯一的不同之處是+=操作符的左操作數(此例為a)只求值一次.注意括號:它們確保表達式在執行加運算之前已被完整求值,即使它內部包含有優先級低於加法運算操作符.
下面兩條語句,如果函數f沒有副作用,那麼它們是等價的:
a[2 * (y – 6*f(x) )] = a[2 * (y – 6*f(x) )] + 1;
a[2 * (y – 6*f(x) )] += 1;
在第一種形式中,用於選擇增值位置的表達式必須書寫兩次,一次在賦值號的左邊,另一次在賦值號的右邊.由於編譯器無從知道函數f是否具有副作用,所以它必須兩次計算下標表達式的值.第二種形式效率更高,因為下標只計算一次.
sizeof操作符
sizeof不是函數而是一個操作符,可以按如下使用:
sizeof(int); sizeof x; //後面可以有括號,也可以沒有.
Sizeof(a = b + 1);這裡是求表達式的長度,但並沒有對表達式進行求值,所以這裡並沒有對a進行賦值.
++\--操作符:
以++為例,前綴形式的++操作符出現在操作數的前面:操作數的值被增加,而表達式的值就是操作數增加後的值. 後綴形式的++操作符出現在操作數的後面:操作數的值仍被增加,但表達式的值是操作數增加前的值.
int a, b, c, d;
a = b = 10; // a和b得到值10
c = ++a; //a增加至11,c得到的值為11
d = b++; //b增加至11, d得到的值為10
上面的注釋描述了這些操作符的結果,但並不說明這些結果是如何獲得的.抽像的說,前綴和後綴形式的增值操作符都復制一份變量的拷貝.用於周圍表達式的值正是這份拷貝(在上面的例子中,”周圍表達式”是指賦值操作). 前綴操作符在進行復制之前增加變量的值,後綴操作符在進行復制之後才增加變理的值.這些操作符的結果不是被它們所修改的變量,而是變量值的一份拷貝,認識這一點非常重要.它之所以重要是因為它解釋了你為什麼不能像下面這樣使用這些操作符:
++a = 10;
++a這個表達式的結果是a值的一份拷貝,並不是變量本身,你無法對一個值進行賦值.
優先級和求值順序
兩個相鄰操作符的執行順序郵它們的優先級決定,如果它們的優先級相同,它們的執行順序郵它們的結合性決定.除此之外,編譯器可以自由決定使用任何順序表達式進行求值,只要它不違背逗號,&&,||和?:操作符所施加的限制.
換句話說,表達式中操作符的優先級只決定表達式的各個組成部分在求值過程中如何進行聚組.這裡有一個例子:
a + b*c
在這個表達式中,乘法和加法操作符是兩個相鄰的操作符.由於*操作符的優先級比+操作符高,所以乘法運算先於加法運算執行.編譯器在這裡別無選擇,它必須先執行乘法運算.
下面是一個更有趣的表達式:
a*b + c*d + e*f
如果僅由優先級決定這個表達式的求值順序,那麼所有3個乘法運算將在所有加法運算之前進行.事實上,這個順序並不是必需的.實際上,只要保證每個乘法運算在它相鄰的加法運算之前執行即可.例如,這個表達式可以會以下面的順序進行,其中粗體的操作符表示在每個步驟中進行操作的操作符:
a * b //乘號
c * d //乘號
(a*b) + (c*d) //加號
e * f //乘號
(a*b) + (c*d) + (e*f) //第二個加號
注意第一個加法運算在最後一個乘法運算之前執行.如果這個表達式按以下的順序執行,其結果是一樣的:
a * b //乘號
c * d //乘號
e * f //乘號
(a*b) + (c*d) //加號
(a*b) + (c*d) + (e*f) //第二個加號
加法運算的結合性要求兩個加法運算按照先左後右的順序執行,但它對表達式剩余的部分的執行順序號並未加以限制.尤其是,這裡並沒有任何規則要求所有的乘法運算首先執行,也沒有規則規定這幾個乘法運算之間誰先執行.優先級規則在這裡起不到作用,優先級只對相鄰操作符的執行順序起作用.
由於表達式的求值順序並非完全由操作符的優先級決定,所以像下面這樣的語句是很危險的:
c + --c
操作符的優先級規則要求自減運算在加法運算這前進行,但我們並沒有辦法得知加法操作符的左操作數是在右操作數之前還是在這後進行求值,它在這個表達式中將存在區別,因數自減操作符具有副作用.—c在c之前或這後執行,表達式的結果在兩種情況下將會不同.
標准說明類似這種表達式的值是未定義的.盡管每種編譯器都會為這個表達式產生某個值,但到底哪個是正確的並無標准答案.因此,像這樣的表達式是不可移植的,應予以避免.
下面這個表達式:
f() + g() + h()
盡管左邊那個加未能運算必須在右邊那個加法運算之前執行,但對於各個函數調用的順序,並沒有規則加以限制.如果它們的執行具有副作用,比如執行一些I/O任務或修改全劇變量,那麼函數調用順序的不同可能會產生不同的結果.因此,如果順序會導致結果產生區別,你最好使用臨時變量,讓每個函數調用都在單獨的語句中執行:
temp = f();
temp += g();
temp += h();
*cp++的執行步聚如下:
(1)++操作符產生cp的一份拷貝
(2)然後++操作符增加cp的值
(3)最後,在cp的拷貝上執行間接訪問操作
(注意這裡++的優先級比*的高)
指針運算:
int *p, *p1;
p+2 實際上為: p + sizeof(*p)*2
p-2 實際上為: p –sezeof(*p)*2
p2 –p1 實際上為: (p1 –p)/(sizeof(*p1)), 兩個指針相減時會執行除法操作,影響效率.
標准允許指向數組元素的指針與指向數組最後一個元素後面的那個內存位置的指針進行比較,但不允許與指向數組第1個元素之前的那個內存位置的位指針進行比較.
如:
#define N_VALUES 5
float values[N_VALUES];
float *vp;
for(vp = &values[0]; vp < &values[N_VALUES];)
*vp++ = 0;
for(vp= &values[N_VALUES-1]; vp>=&values[0]; vp--)
*vp = 0;
由標准可以,第二個for語句是有問題的.但實際上,在絕大多數C編譯器中,這個循環將順利完成任務.然而,你還是應該避免使用它,因為標准並不保語它可行.你遲早可能遇到一台這個循環失敗的機器.對於負責可移植代碼的程序員而言,這類問題簡直就是個惡夢.
數組:
int a;
int b[10];
b[4]的類型是整型,但b的類型又是什麼呢?它所表示的又是什麼呢?一個合乎邏輯的答案是它表示整個數組,但事實並非如此.在C中,在幾乎所有使用數組名的表達式中,數組名的值是一個指針常量,也就是數組第1個元素的地址.它的類型取決於數組元素的類型:如果它們是int類型,那麼數組名的類型就是”指向int的常量指針”;如果它們是其它類型,那麼數組名就是”指向其它類型的常量指針”.
只有在兩種場合下,數組名並不用指針常量來表示------就是當數組名作為sizeof操作符或單目操作符的操作數時.sizeof返回整個數組的長度,而不是指向數組的指針的長度,取一個數組名的地址所產生的是一個指向數組的指針!
數組和指針
指針和數組並不是相等的,為了說明這個概念,請考慮下面這兩個聲明:
int a[5];
int b;
a和b能夠互換使用嗎?它們都具有指針值,它們都可以進行間接訪問和下標引用操作.但是它們還是存在相當大的區別.
聲明一個數組時,編譯器將根據聲明所指定的元素數量為數組保留內存空間,然後再創建數組名,它的值是一個常量,指向這段空間的起始位置.聲明一個指針變量時,編譯器只為指針本身保留內存空間,它並不為任何整型值分配內存空間.而且,指針變量並未被初始化為指向任何現有的內存空間,如果它是一個自動變量,它甚至根本不會被初始化.因此,上述聲明之後,表達式*a是完全合法的,但表達式*b卻是非法的.*b將訪問內存中某個不確定的位置,或者導致程序終止.另一方面,表達式b++可以通過編譯,但a++卻不行,因為a的值是一個常量.
字符數組的初始化
char message[] = { ‘H’, ‘e’, ‘l’, ‘l’, ‘o’, 0};
這個方法當然可行.但除了非常短的字符串,這種方法確實很笨拙.因此,語言標准提供了一種快遞方法用於初始化字符數組:
char message[] = “Hello”;
盡管它看上去像是一個字符串常量,實際上並不是.它只是前例的初始化例表的另一種寫法.
如果它們看上去完全相同,你如何分辨字符串常量和這種初始化例快遞記法呢?它們是根據它們所處的上下文環境進行區分的.當用於初始化一個字符數組時,它已經一個初始化例表.在其他任何地方,它都表示一個字符串常量.
這裡有一個例子:
char message[] = “Hello”;
char *message = “Hello”;
這兩個初始化看上去很像,但它們具有不同的含義.前者初始化一個字符數組的元素,而後者則是一個真正的字符串常量.這個指針變量被初始化為指向這個字符串常量的存儲位置.
多維數組:
考慮下列這些維數不斷增加的聲明:
int a;
int b[10];
int c[6][10];
int d[3][6][10];
a是個簡單的整數.接下來的那個聲明增加了一個維數,所以b就是一個向量,它包含10個整型元素.
c只是在b的基礎上再增加了一維,所以我們可以把c看作是一個包含6個元素的向量,只不過它的每個元素本身是一個包含10個整型元素的向量.換句話說,c是一個一維數組的一維數組.d也是一如此:它是包含3個元素的數組.簡潔的說,d是一個3排6行10列的整型三維數組.
數組名
一維數組名的值是一個指針常量,它的類型是”指向元素類型的指針”,它指向數組的第1個元素.多維數組也差不多簡單.唯一的區別是多維數組第1維元素實際上是另一個數組.例如,下面這個聲明:
int matrix[3][10];
matrix這個名字的值是一個指向它第1個元素的指針,所以matrix是一個指向一個包含10個整型元素的數組的指針.
指向數組的指針:
下面這些聲明合法嗎?
int vector[10], *vp = vector;
int matrix[3][10], *mp = matrix;
第一個聲明是合法的.它為一個整型數組分配內存,並把vp聲明為一個指向整型的指針,並把它初始化為指向vector數組的第1個元素.vector和vp具有相同的類型:指向整型的指針.但是第二個聲明是非法的.它正確地創建了matrix數組,並把mp聲明為一個指向整型的指針.但是mp的初始化是不正確的,因為matrix並不是一個指向整型的指針,而是一個指向整型數組的指針.我們應該怎樣聲明一個指向整型數組的指針的呢?
int (*p)[10];
這個聲明比我們以前見過的所有聲明更為復雜,但它事實上並不是很難.你只要假定它是一個表達式並對它進行求值.下標引用的優先級高於間接訪問,但由於括號的存在,首先執行的還是間接訪問,所以,p是一個指針,但它指向什麼呢?接下來掃行的是下標的引用,所以p指向某種類型的數組.這個聲明表達式中並沒有更多的操作符,所以數組的每個元素都是整數.
聲明並沒有直接告訴你p是什麼,但推斷它的類型並不困難-----當我們對它執行間接訪問操作時,我們得到的是個數組,對該數組進行下標引用操作得到的是一個整型值.所以p是一個指向整型數組的指針.
在聲明中加上初始化後是下面這個樣子:
int (*p)[10] = matrix;
它使p指向matrix的和1行.
p是一個指向擁有10個整型元素的數組的指針.當你把p與一個整數相加時,該整數值首先根據10個整型值的長度進行調整,然後再執行加法.所以我們可以使用這個指針一行一行地在matrix中移動.
如果你需要一個指針逐個訪問整型元素而不是逐行在數組中移動,你應該怎麼辦呢?下面兩個聲明都創建了一個簡單的整型指針,並以兩種不同的方式進行初始化,指向matrix的第1個整型元素.
int *pi = &matrix[0][0];
int *pi = matrix[0];
增加這個指針的值使它指向下一個整型元素.
指針數組
int *api[10];
為了弄清楚這個復雜的聲明,我們假定它是一個表達式,並對它進行求值.
下標引用的優先級高於間接訪問,所以在這個表達式中,首先執行下標引用.因此,api是某種類型的數組(噢! 順便說一下,它包含的元素個數為10).在取得一個數組元素之後,隨即執行的是間接訪問操作.這個表達式不再有其它操作符,所以它的結果是一個整型值.對數組的某個元素執行間接訪問操作後,我們得到一個整型值,所以api肯定是個數組,它的元素類型是指向整型的指針.
高級指針話題
int *f();
要想推斷出它的含義,你必須確定表達式*f()是如何進行求值的.首先執行的是函數調用操作符(),因為它的優先級高於間接訪問操作符.因此,f是一個函數,它的返回值類型是一個指向整型的指針.
接下來的一個聲明更為有趣:
int (*f)();
確定括號的含義是分析這個聲明的一個重要步驟.這個聲明有兩對括號,每對的含義各不相同.第2對括號是函數調用操作符,但第1對括號只起到聚組的作用.它迫使間接訪問在函數調用之前進行,使f成為一個函數指針,它所指向的函數返回一個整型值.
現在下面這個聲明應該是比較容易弄懂了:
int *(*f)();
它和前一個聲明基本相同,f也是一個函數指針,只是的所指向的函數的返回值是一個整型指針,必須對其進行間接訪問操作才能得到一個整型值.
int (*f[])();
對於這個聲明,首先你必須找到所有的操作符,然後按照正確的次序執行它們.同樣,這裡有兩對括號,它們分別具有不同的含義.括號內的表達式*f[]首先進行求值,所以f是一個元素為某種類型的指針的數組.表達式末尾的()是函數調用操作符,所以f肯定是一個數組,數組元素的類型是函數指針,它所指向的函數的返回值是一個整型值.
如果搞清楚了上面最後一個聲明,下面這個應該是比較容易的了:
int *(*f[])();
它和上面那個聲明的唯一區別就是多了一個間接訪問操作符,所以這個聲明創建了一個指針數組,指針所指向的類型是返回值為整型指針的函數.
字符串常量:
當一個字符串常量出現於表達式中時,它的值是個指針常量.編譯器把這些指定字符的一份拷貝存儲在內存的某個位置,並存儲一個指向第一個字符的指針.但是,當數組名用於表達式中時,它們的值也是指針常量.
下面這個表達式是什麼意思呢?
“xyz” + 1;
對於絕大多數程序員而言,它看上去像堆垃圾.它好像是試圖在一個字符串上面執行某種類型的加法運算.但是,當你記得字符串常量實際上是指針時,它的意義就變得清楚了.這個表達式計算”指針值加上1”的值.它的結果是個指針,指向字符串中的第2個字符:y.
那麼這個表達式又是什麼呢?
*”xyz”;
對一個指針執行間接訪問操作時,其結果是指針所指向的內空.字符串常量的類型是”指向字符的指針”,所以這個間接訪問的結果就是它所指向的字符:x,注意表達式的結果並不是整個字符串,而只是它的第1個字符.
下一個例子看上去也是有點奇怪,不過現在你應該對夠推斷出這個表達式的值就是字符z.
“xyz”[2];
下面這個語句是把二進制轉換為字符:
putchar(“0123456789ABCDEF”[value%16]);
字符串,字符,字節
庫函數strlen的原型:
size_t strlen(char const *string);
注意strlen返回一個類型為size_t(無符號整型),下面兩個表達式看上去是相等的:
if(strlen(x) >= strlen(y))…..
if(strlen(x) – strlen(y) >= 0)….
但事實上它們是不相等的.第1條語句將接照你預想的那樣工作,但第2條語句的結果將永遠是真的.
字符串查找基礎
在一個字符串中查找一個特定的字符最容易的方法是使用strchr和strrchr函數,它們的原型如下所示:
char *strchr(char const *str, int ch);
char *strchr(char const *str, int ch);
注意它們的第2個參數是一個整型值,但是它包括了一個字符值.strchr在字符串str中查找字符ch第1次出現的位置,找到後函數返回一個指向該位置的指針.如果該字符並不存在於字符串中,函數就返回一個NULL指針.strrchr的功能和strchr基本一致,只是它所返回的是一個指向字符串中該字符最後一次出現的位置(最右邊那個).
查找任何幾個字符
strpbrk是個更為常見的函數.它並不是查找某個特定的字符,而是查找任何一組字符第1次在字符串中出現的位置.它原型如下:
char *strpbrk(char const *str, char const *group);
這個函數返回一個指向str中第1個匹配group中任何一個字符的字符位置.如果未找到匹配,函數返回一個NULL指針.
在下面的代碼段中:
char string[20] = “hello there, honey.”
char *ans;
ans = strpbrk(string, “aeiou”);
ans所指向的位置是string+1,因為這個位置是第2個參數中的字符e第一次出現的位置.這個函數是區分大小寫的.
高級字符串查找
查找一個字符串前綴:
strspn和strcspn函數用於在字符串的起始位置對字符計數.它們的原型如下所示:
size_t strspn(char const *str, char const *group);
size_t strcspn(char const *str, char const *group);
group字符串指定一個或多個字符串.strspn返回str起始部分(從第一個字符開始)匹配group中任意字符的字符數.例如,如果group包含了空格,制表符等空白符,那麼,這個函數將返回str起始部分空白字符的數目.str的下一個字符就是它的第一個非空白字符.
考慮下面這個例子:
int len1, len2;
char buffer[]=”25,142,330,Smith,J,239-4123”;
len1 = strspn(buffer, “0123456789”);
len2 = strspn(buffer, “,123456789”);
len1的值為2,從第一個字符開始,只有25可以匹配,再遇到”,”號時就結束匹配了.
len2的值為11,從第一個字符開始,匹配的內容為:”25,142,330,”當遇到字符S時匹配結束,因為字符S並不是第二個參數中的字符.
strcspn函數和strspn函數的功能正好相反,它對str字符串起始部分中不與group中任何字符匹配的字符進行計數.strcspn這個名字中字母c來源於對一組字符求補這個概念,也就是把這些字符換成原先並不存在的字符.如果你使用”\n\r\f\t\v”作為group參數,這個函數將返回第一個參數字符串起始部分所有非空白字符的值.
分隔字符串
一個字符串常常包含幾個單獨的部分,它們彼此被分隔開來.每次為了處理這些部分,你首先必須把它們從字符中抽取出來.
這個任務正是strtok函數所實現的功能.它從字符串中分離出被分隔符(由第二個參數字義)隔離的部分,並丟棄分隔符.它的原型如下:
char *strtok(char *str, char const *sep);
sep參數是個字符串,定義了用作分隔符的字符集合.第1個參數指定一個字符串,它包含零個或多個由sep字符串中一個或多個分隔符分離隔的子串.strok找到str的下一個子串,並將其它NULL結尾,然後返回一個指向這個子串的指針.
警告:
當strtok函數執行任務時,它將會修改它所處理的字符串.如果源字符串不能被修改,那就復制一份,將這份拷貝傳遞給strtok函數.
如果strtok函數的第一個參數不是NULL,函數將找到字符串的第一個字串(由分隔符分隔出來的子串).strtok同時將保存它在字符串中的位置.如果strtok函數的第一個參數是NULL,函數就在同一個字符串中從這個被保存的位置開始像前面一樣查找下一個子串,如果字符串內不存在更多的子串,strtok函數就返回一個NULL指針.在典型情況下,在第一次調用相等的strtok時,向它傳遞一個指向字符串的指針.然後這個函數被重復調用(第一個參數置為NULL),直到它返回NULL為止.
下面是一個簡短的例子.這個函數從第一個參數字符串中分離出由空白符分隔的子串,並把它們打印出來.
#include<stdio.h>
#include<string.h>
void print_tok(char *line)
{
static char whitespace[] = “\t\f\r\v\n”
char *token;
for(token = strtok(line, whitespace); token != NULL; token = strtok(NULL, whitespace) )
printf(“Next token is %s\n”, token);
}
如果你願意,你可以在每次調用strtok函數時使用不同的分隔符集合,當一個字符串的不同部分由不同的字符集合分隔的時候,這個技巧很管用.
提示: 由於strtok函數保存它所處理的函數的局部狀態信息,所以你不能用它同時解析兩個字符串.因此,如果for循環的循環體內調用了一個在內部調用strtok函數的函數,則上面的例子將會失敗.
位段
位段的聲明和任何普通的結構體成員的聲明相同,但有兩處例外,首先,位段成員必須聲明為int,signed int,unsigned int類型.其次,在成員名的後面是一個冒號和一個整數,這個整數指定該位段所占用的位數目.
用signed或unsigned整數顯式地聲明位段是個好注意.如果把位段聲明為int類型,它究竟被解釋為有符號數還是無符號數是由編譯器決定的.
注重可移植性的程序應該避免使用位段.由於下面這些與實現有關的依賴性,位段在不同的系統中可能有不同的結果.
1. int位段被當作有符號還是無符號數.
2. 位段中位的最大數目.許多編譯器把位段成員的長度限制在一個整型值的長度之內,所以一個能夠運行於32位整數的機器上的位段聲明可能在16位整數的機器上無法運行.
3. 位段中的成員在內存中是從左向右分配還是從右向左分配的.
4. 當一個聲明指定了兩個位段,第2個位段比較大,無法容納於第1個位段剩余的位時,編譯器有可能把第2個位段放在內存的下一個字,也可能直接放在第1個位段後面,從而在兩個內存位置的邊界上形成重疊.
下面是一個位段聲明的例子:
struct CHAR {
unsigned ch : 7;
unsigned font : 6;
unsigned size : 19;
};
struct CHAR ch1;
動態內存分配
下面這些函數在stdlib.h中聲明
viod *malloc(size_t size);
void *calloc(size_t num_elements, size_t element_size);
void realloc(void *ptr, size_t new_size);
void free(void *pointer);
malloc的參數就是需要分配的內存字節數,malloc分配的是一塊連續的內存,如果內存池中的可用內存可以滿足這個需求,malloc就返回一個指向被分配的內存塊起始位置的指針.如果操作系統無法向malloc提供更多的內存,malloc就返回一個NULL指針.因此,對每個從malloc返回的指針都進行檢查,確保它並非NULL是非常重要的.
對於要求邊界對齊的機器,malloc所返回的內存的起始位置將始終能夠滿足對邊界對齊要求最嚴格的類型的要求.
mllloc和calloc之間的主要區別是後者在返回指向內存的指針之前把它初始化為0.這個初始化常常能帶來方便,但如果你的程序只是想把一些值存儲到數組中,那麼這個初始化過程純屬浪費時間.
realloc函數用於修改一個原先已經分配的內存塊的大小.使用這個函數,你可以使一塊內存擴大或縮小.如果它用於擴大一個內存,那麼這塊內原先的內容依然保留,新增加的內存添加到原先內存塊的後面,新內存並未以任何方法進行初始化.如果它用於縮小一個內存塊,該內存塊尾部的部分內存便被拿掉,剩余部分內存的原先內容依然保留.如果原先的內存塊無法改變大小,realloc將分配另一塊正確大小的內存,並把原先那塊內存的內容復制到新的塊上.因此,在使用realloc之後,你就不能再使用指向舊內存的指針,而是應該改用realloc所返回的新指針.如果realloc函數的第一個參數是NULL,那麼它的行為就和malloc一模一樣.
free的參數是一個先前從malloc,calloc,realloc返回的指針.向free傳遞一個NULL參數不會產生任何效果
摘自 DLUTXIE