C語言是編譯型的語言,必須經過編譯器的編譯才能在內存中加載被處理器執行,從C語言的源文件到最終的處理器能夠執行機器碼,是我們通常所說的”編譯“,這是個模糊的概念,實際上需要預處理、編譯、匯編、鏈接四個處理流程,那麼編譯器在這四個過程中都做了哪些事情呢?實際上,從C語言源碼到機器碼涉及到C語言、匯編語言、機器語言,即是從從“人可識別”閱讀性好的高級語言到機器可識別的低級語言,還好編譯器幫助我們做好了這些事情。
本文以gcc編譯器為例來詳解這四個過程,全文以最簡單的 “helloworld” 程序為例裡說明"編譯"流程,由於涉及到晦澀難懂的匯編語言和只有機器才能識別的機器語言,所以大家不要深究匯編語言中的匯編指令的具體含義的,機器碼如何和匯編指令對應的,只要能夠理解這四個“編譯”流程即可,對於如何產生機器碼,怎樣檢查語法錯誤等都是由編譯器自動來完成的,這裡面涉及到的是編譯原理,況且編譯器對應與不同CPU體系架構,例如生成x86架構的機器碼和生成arm架構的機器碼對應的編譯器是不一樣的。了解了C語言的編譯流程對於程序設計有很大幫助,有助於我們理解最底層的東西,應對一些未知的編譯或運行錯誤,如段錯誤等。
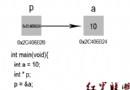
以下是我們要實驗的測試代碼(C語言入門的helloworld程序,當然那個數組a對於程序執行來說毫無意義只是用於說明問題):
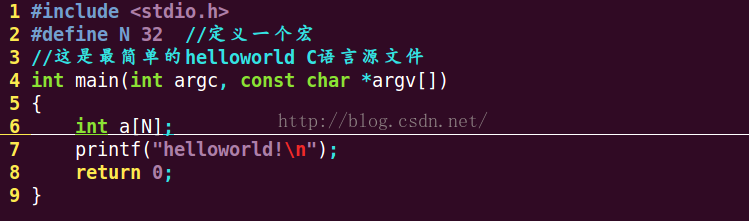
首先我們先使用最常用的gcc編譯選項:gcc hello.c -o hello來編譯,這時生成的只有最終的可執行文件 hello。

查下文件類型:file hello 發現其是ELF格式(這個是Linux系統所使用的二進制可執行文件的格式),且是能在x86架構上運行的可執行文件。

當然是可以執行的:./hello 執行 (hello前加 './' 的原因是代表當前目錄下,如果不加會被當作shell命令來執行,產生報錯信息)

可以看得到按照這種編譯選項是直接執行了預處理、編譯、匯編、鏈接四步,生成最終的可執行文件,沒有中間文件的生成,接下來我們使用gcc的其他編譯選項來詳解gcc的四個“編譯”流程。
一、預處理
預處理的含義就是在編譯開始之前對源程序做一些初步的轉換,這些都是有預處理器的預處理程序來完成轉化的,主要完成三個主要任務:文件包含、宏替換、去注釋。檢查包含預處理指令的語句和宏定義,並對源代碼進行相應的轉化,預處理指令都是以#開頭的代碼行(如:#include #define等),關於預處理的一些內容將在以後的一些內容中有所涉及。
命令行輸入:gcc -E hello.c -o hello.i 之後生成了hello.i的文件,這個文件就是預處理之後的文件。

打開hello.i 文件我們發現:都是一些文件路徑的描述 ,變量的定義,結構體的定義,函數的聲明等。
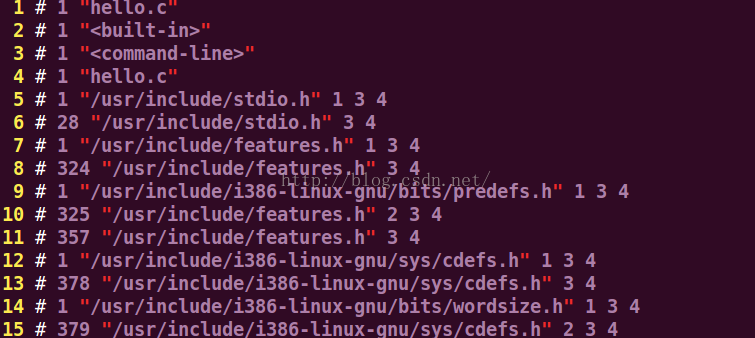
以上是一些文件路徑的說明:
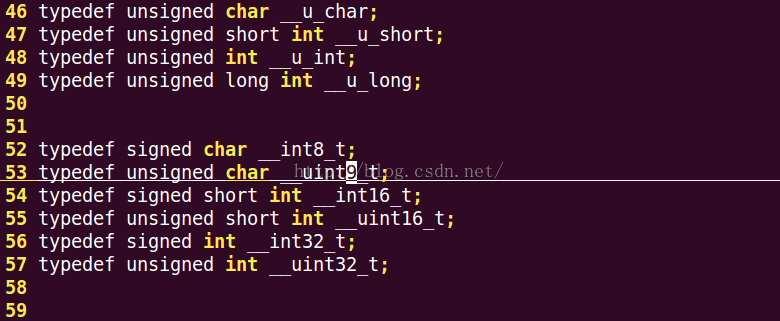
以上是變量類型的定義:
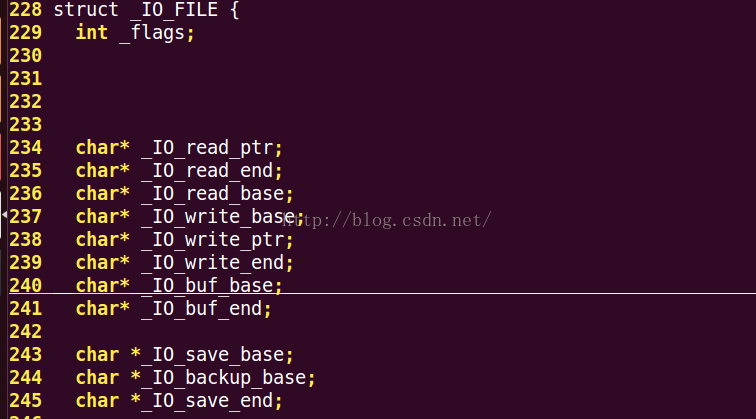
以上是結構體的定義(這裡是標准IO的FILE結構體的定義):
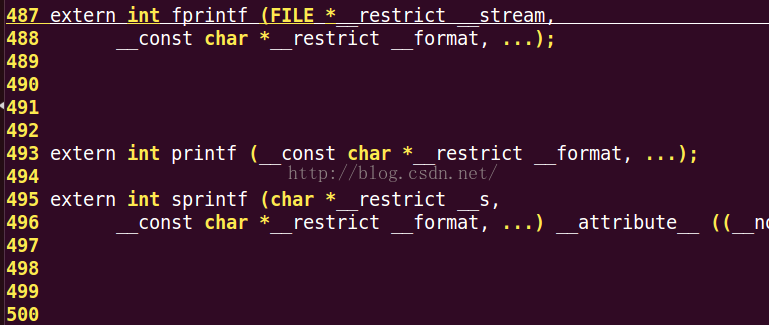
以上是函數的聲明(這裡是標准io的庫函數接口的聲明,可以看到我們使用的printf函數的聲明),當然這裡沒有函數的定義,函數的定義實現是在libc庫中實現,在鏈接的階段會鏈接要使用的庫函數:
上面都是文件包含(#include
二、編譯
在這個階段,編譯器會把預處理之後的源文件 hello.i 編譯成匯編語言 ,此時會對源文件進行語法檢查,如果源文件中有語法錯誤,編譯器會停止編譯,並打印出錯誤信息供程序員檢查修改。
命令行輸入:gcc -S hello.i -o hello.s 會生成hello.s文件這個文件就是匯編文件。

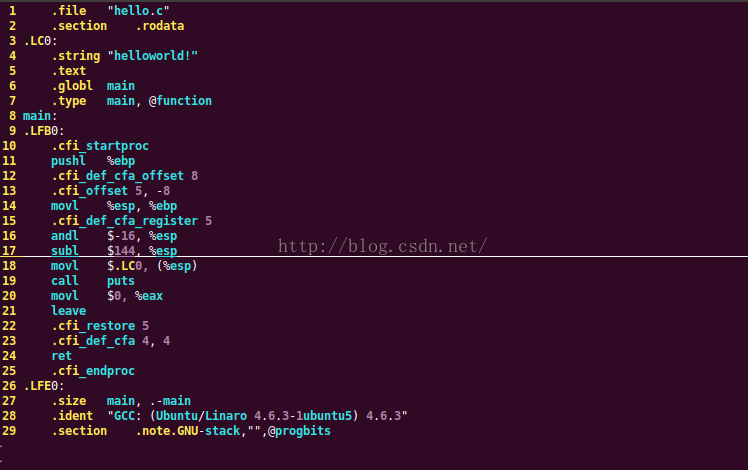
打開hello.s如下:可見比原來的C文件多了不少行,雖然也不是太多,但是我們可能無法讀的明白每條指令的含義。我們可以大致看到: .rodata這是個只讀的數據段(其中第四行就是只讀的“helloworld”),還會看到.text 這是個代碼段就是可執行的二進制代碼所在的位置等等。如果想搞明白每條指令的含義,不僅需要我們懂得底層的cpu架構的知識,還要懂得匯編語言的語法規則,其次要了解每條指令所對應的x86指令集。當然,每種架構所對應的匯編指令集是不同的,編譯生成的匯編文件也是不一樣的,幸運的是這些東西都不需要我們去轉化,編譯器會給我們做好這些轉化工作。
三、匯編
經過編譯器編譯後生成的hello.s文件還是不能被執行的,因為不能被機器識別(只識別二進制文件),所以需要第三步的匯編階段,匯編器會把hello.s文件匯編成目標機器指令(*.o文件)。因為每條匯編指令都對應與相應的二進制機器碼,所以這樣的轉化對於匯編器來說是很簡單的,一般目標代碼都會有代碼段和數據段。
命令行輸入:gcc -c hello.s -o hello.o 就得到了目標文件hello.o文件

打開hello.o文件(如下):發現都是對我們來說的亂碼,不過不用擔心這是給機器讀的,知道這些就可以了。
unix環境下主要有三種類型的目標文件:
(1)可重定位文件
其中包含了適合於其他目標文件鏈接來創建一個可執行的或共享的目標文件的代碼和數據。
(2)共享的目標文件
這種文件存放了適合於在兩種上下文裡鏈接的代碼和數據。第一種是鏈接程序可把它與其它可重定位文件及共享的目標文件一起處理來創建另一個 目標文件;第二種是動態鏈接程序將它與另一個可執行文件及其它的共享目標文件結合到一起,創建一個進程映象。
(3)可執行文件
它包含了一個可以被操作系統創建一個進程來執行之的文件。匯編程序生成的實際上是第一種類型的目標文件。對於後兩種還需要其他的一些處理方能得到,這個就是鏈接程序的工作了。
四、鏈接
由於匯編之後生成的目標文件不能立即被執行,其中可能還有尚未解決的問題,例如:某個源文件可能引用另一個源文件中的某些符號(變量或者函數調用等),程序中也有可能調用了某個庫函數中的函數等等。這裡就是調用了標准io庫的printf函數。鏈接程序的主要工作就是將有關的目標文件彼此相連接,也即將在一個文件中引用的符號同該符號在另外一個文件中的定義連接起來,使得所有的這些目標文件成為一個能夠被操作系統裝入執行的統一整體。
命令行輸入:gcc hello.o -o hello

打開hello文件(如下):還是我們不能識別的亂碼,比目標文件“體積”大些,這是鏈接的結果,但是這是可以被操作系統加載執行的。

根據開發人員指定的同庫函數的鏈接方式不通,鏈接處理可分為兩種:
(1)靜態鏈接
在這種鏈接方式下,函數的代碼將從其所在地靜態鏈接庫中被拷貝到最終的可執行程序中。這樣該程序在被執行時這些代碼將被裝入到該進程的虛擬地址空間中。靜態鏈接庫實際上是一個目標文件的集合,其中的每個文件含有庫中的一個或者一組相關函數的代碼。
(2)動態鏈接
在此種方式下,函數的代碼被放到稱作是動態鏈接庫或共享對象的某個目標文件中。鏈接程序此時所作的只是在最終的可執行程序中記錄下共享對象的名字以及其它少量的登記信息。在此可執行文件被執行時,動態鏈接庫的全部內容將被映射到運行時相應進程的虛地址空間。動態鏈接程序將根據可執行程序中記錄的信息找到相應的函數代碼。
對於可執行文件中的函數調用,可分別采用動態鏈接或靜態鏈接的方法。使用動態鏈接能夠使最終的可執行文件比較短小,並且當共享對象被多個進程使用時能節約一些內存,因為在內存中只需要保存一份此共享對象的代碼。但並不是使用動態鏈接就一定比使用靜態鏈接要優越。在某些情況下動態鏈接可能帶來一些性能上損害。
至此我們就完成了從一個C源文件到可執行文件的過程,所寫的代碼歸結到底層都會被轉化為特定機器能夠識別並執行的二進制機器碼,當然大家還會有一些疑問:靜態庫、動態庫如何鏈接和創建,預處理指令如何在代碼中使用等等,將會在其他的博文中涉及到。最後需要說明的是:其中的案例代碼都是本人實踐和查閱權威資料得出,如有出入望提出寶貴意見。