在C語言中,可以使用結構體(Struct)來存放一組不同類型的數據。結構體的定義形式為:
struct 結構體名{
結構體所包含的變量或數組
};
結構體是一種集合,它裡面包含了多個變量或數組,它們的類型可以相同,也可以不同,每個這樣的變量或數組都稱為結構體的成員(Member)。請看下面的一個栗子:
struct stu{
char *name; //姓名
int num; //學號
int age; //年齡
char group; //所在學習小組
float score; //成績
};
stu 為結構體名,它包含了 5 個成員,分別是 name、num、age、group、score。結構體成員的定義方式與變量和數組的定義方式相同,只是不能初始化。
注意大括號後面的分號“;”不能少哦~
結構體也是一種數據類型,它由我們自己來定義,可以包含多個其他類型的數據。
像int、float、char 等是由C語言本身提供的數據類型,不能再進行分拆,我們稱之為基本數據類型;而結構體可以包含多個基本類型的數據,也可以包含其他的結構體。
既然結構體是一種數據類型,那麼就可以用它來定義變量。例如:
struct stu stu1, stu2;
定義了兩個變量 stu1 和 stu2,它們都是 stu 類型,都由 5 個成員組成。注意關鍵字struct不能少。
還可以在定義結構體的同時定義結構體變量:
struct stu{
char *name; //姓名
int num; //學號
int age; //年齡
char group; //所在學習小組
float score; //成績
} stu1, stu2;
如果只需要 stu1、stu2 兩個變量,後面不需要再使用結構體名定義其他變量,那麼在定義時也可以不給出結構體名,如下所示:
struct{ //沒有寫 stu
char *name; //姓名
int num; //學號
int age; //年齡
char group; //所在學習小組
float score; //成績
} stu1, stu2;
這樣的寫法很簡單,但是因為沒有結構體名,後面就沒法用該結構體定義新的變量了。
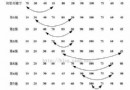
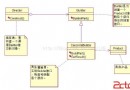
理論上講結構體的各個成員在內存中是連續存儲的,和數組非常類似,例如上面的結構體變量 stu1、stu2 的內存分布如下圖所示,共占用 4+4+4+1+4 = 17 個字節。但是在編譯器的具體實現中,各個成員之間可能會存在空隙,C語言中,結構體大小的內存分配
這裡我在做下總結:
運算符sizeof可以計算出給定類型的大小,對於32位系統來說,sizeof(char) = 1; sizeof(int) = 4。基本數據類型的大小很好計算,我們來看一下如何計算構造數據類型的大小。
C語言中的構造數據類型有三種:數組、結構體和共用體。
數組是相同類型的元素的集合,只要會計算單個元素的大小,整個數組所占空間等於基礎元素大小乘上元素的個數。
結構體中的成員可以是不同的數據類型,成員按照定義時的順序依次存儲在連續的內存空間。和數組不一樣的是,結構體的大小不是所有成員大小簡單的相加,需要考慮到系統在存儲結構體變量時的地址對齊問題。看下面這樣的一個結構體:
struct stu1
{
int i;
char c;
int j;
};
先介紹一個相關的概念——偏移量。偏移量指的是結構體變量中成員的地址和結構體變量地址 的差。結構體大小等於最後一個成員的偏移量加上最後一個成員的大小。顯然,結構體變量中第一個成員的地址就是結構體變量的首地址。因此,第一個成員i的偏 移量為0。第二個成員c的偏移量是第一個成員的偏移量加上第一個成員的大小(0+4),其值為4;第三個成員j的偏移量是第二個成員的偏移量加上第二個成 員的大小(4+1),其值為5。
實際上,由於存儲變量時地址對齊的要求,編譯器在編譯程序時會遵循兩條原則:一、結構體變量中成員的偏移量必須是成員大小的整數倍(0被認為是任何數的整數倍) 二、結構體大小必須是所有成員大小的整數倍。
對照第一條,上面的例子中前兩個成員的偏移量都滿足要求,但第三個成員的偏移量為5,並不是自身(int)大小的整數倍。編譯器在處理時會在第二個成員後面補上3個空字節,使得第三個成員的偏移量變成8。
對照第二條,結構體大小等於最後一個成員的偏移量加上其大小,上面的例子中計算出來的大小為12,滿足要求。
再看一個滿足第一條,不滿足第二條的情況:
struct stu2
{
int k;
short t;
};
成員k的偏移量為0;成員t的偏移量為4,都不需要調整。但計算出來的大小為6,顯然不 是成員k大小的整數倍。因此,編譯器會在成員t後面補上2個字節,使得結構體的大小變成8從而滿足第二個要求。由此可見,大家在定義結構體類型時需要考慮 到字節對齊的情況,不同的順序會影響到結構體的大小。對比下面兩種定義順序
struct stu3
{
char c1;
int i;
char c2;
}
struct stu4
{
char c1;
char c2;
int i;
}
雖然結構體stu3和stu4中成員都一樣,但sizeof(struct stu3)的值為12而sizeof(struct stu4)的值為8。
如果結構體中的成員又是另外一種結構體類型時應該怎麼計算呢?只需把其展開即可。但有一點需要注意,展開後的結構體的第一個成員的偏移量應當是被展開的結構體中最大的成員的整數倍。看下面的例子:
struct stu5
{
short i;
struct{
char c;
int j;
} ss;
int k;
}
結構體stu5的成員ss.c的偏移量應該是4,而不是2。整個結構體大小應該是16。
如何給結構體變量分配空間由編譯器決定,以上情況針對的是Linux下的GCC。其他平台的C編譯器可能會有不同的處理,看到這裡估計還是有些同學不太明白,多看幾遍,領悟領悟,就好啦!
結構體和數組類似,也是一組數據的集合,整體使用沒有太大的意義。數組使用下標[ ]獲取單個元素,結構體使用點號.獲取單個成員。獲取結構體成員的一般格式為:
結構體變量名.成員名;
通過上面的格式就可以獲取成員的值,和給成員賦值,看下面的栗子:
#includeint main(){ struct{ char *name; //姓名 int num; //學號 int age; //年齡 char group; //所在小組 float score; //成績 } stu1; //給結構體成員賦值 stu1.name = "haozi"; stu1.num = 12; stu1.age = 18; stu1.group = 'A'; stu1.score = 136.5; //讀取結構體成員的值 printf("%s的學號是%d,年齡是%d,在%c組,今年的成績是%.1f!\n", stu1.name, stu1.num, stu1.age, stu1.group, stu1.score); return 0; }
運行結果:
haozi的學號是12,年齡是18,在A組,今年的成績是136.5!
除了這種方式賦值外,還可以在定義的時候賦值:
struct{
char *name; //姓名
int num; //學號
int age; //年齡
char group; //所在小組
float score; //成績
} stu1, stu2 = { "haozi", 12, 18, 'A', 136.5 };
不過整體賦值僅限於定義結構體變量的時候,在使用過程中只能對成員逐一賦值,這和數組的賦值非常類似。
指針也可以指向一個結構體,定義的形式一般為:
struct 結構體名 *變量名;
看例子:
struct Man{
char name[20];
int age;
};
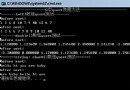
void main(){
struct Man m1 = {"Jack",30};
//結構體指針
struct Man *p = &m1;
printf("%s,%d\n", m1.name, m1.age);
printf("%s,%d\n",(*p).name,(*p).age);
//“->”(箭頭)是“(*p).”簡寫形式
printf("%s,%d\n", p->name, p->age);
//(*env)->
system("pause");
}
編譯出的結果是:
Jack,30 Jack,30 Jack,30 請按任意鍵繼續. . .
上面代碼:printf(“%s,%d\n”, m1.name, m1.age);還可以換成: printf(“%s,%d\n”, (*p).name, m1.age);或者 printf(“%s,%d\n”, p->name, m1.age);
其運行結果還是一樣的。
獲取結構體成員通過結構體指針可以獲取結構體成員,一般形式為:
(*pointer).memberName
或者:
pointer->memberName
結構體(Struct)是一種構造類型或復雜類型,它可以包含多個類型不同的成員。在C語言中,還有另外一種和結構體非常類似的語法,叫做共用體(Union),它的定義格式為:
union 共用體名{
成員列表
};
共用體有時也被成為聯合體;
結構體和共用體的區別在於:結構體的各個成員會占用不同的內存,互相之間沒有影響;而共用體的所有成員占用同一段內存,修改一個成員會影響其余所有成員。
結構體占用的內存大於等於所有成員占用的內存的總和(成員之間可能會存在縫隙),共用體占用的內存等於最長的成員占用的內存。共用體使用了內存覆蓋技術,同一時刻只能保存一個成員的值,如果對新的成員賦值,就會把原來成員的值覆蓋掉。
共用體也是一種自定義類型,可以通過它來創建變量,例如:
union data{
int n;
char ch;
double f;
};
union data a, b, c;
上面是先定義共用體,再創建變量,也可以在定義共用體的同時創建變量:
union data{
int n;
char ch;
double f;
} a, b, c;
共用體 data 中,成員 f 占用的內存最多,為 8 個字節,所以 data 類型的變量(也就是 a、b、c)也占用 8 個字節的內存,請看下面的栗子:
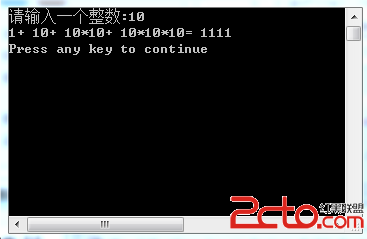
#includeunion var{ long j; int i; }; main(){ union var v; v.j = 5; printf("v.j is %d\n",v.i); v.i = 6; //最後一次賦值有效 printf("now v.j is %ld! the address is %p\n",v.j,&v.j); printf("now v.i is %d! the address is %p\n",v.i,&v.i); system("pause"); }
編譯並運行結果:
v.j is 5 now v.j is 6! the address is 0xbfad1e2c now v.i is 6! the address is 0xbfad1e2c
這段代碼不但驗證了共用體的長度,還說明共用體成員之間會相互影響,修改一個成員的值會影響其他成員。