C語言中堆、棧和隊列:
1.堆和棧
(1)數據結構的堆和棧
堆棧是兩種數據結構。
棧(棧像裝數據的桶或箱子):是一種具有後進先出性質的數據結構,也就是說後存放的先取,先存放的後取。這就如同要取出放在箱子裡面底下的東西(放入的比較早的物體),首先要移開壓在它上面的物體(放入的比較晚的物體)。
堆(堆像一棵倒過來的樹):是一種經過排序的樹形數據結構,每個結點都有一個值。通常所說的堆的數據結構,是指二叉堆。堆的特點是根結點的值最小(或最大),且根結點的兩個子樹也是一個堆。由於堆的這個特性,常用來實現優先隊列,堆的存取是隨意,這就如同在圖書館的書架上取書,雖然書的擺放是有順序的,但是想取任意一本時不必像棧一樣,先取出前面所有的書,書架這種機制不同於箱子,我們可以直接取出我們想要的書。
(2)內存分配中的堆和棧
C語言程序內存分配中的堆和棧。C語言程序經過編譯連接後形成編譯、連接後形成的二進制映像文件由棧,堆,數據段(由三部分部分組成:只讀數據段,已經初始化讀寫數據段,未初始化數據段即BBS)和代碼段組成,如下圖所示:
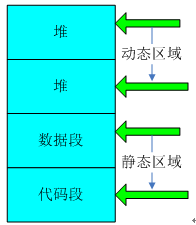
棧區:處於相對較高的地址,以地址的增長方向為上的話,棧地址是向下增長的;
堆區:是向上增長的用於分配程序員申請的內存空間。
一個例子:
main.cpp
int a = 0; 全局初始化區
char *p1; 全局未初始化區
main()
{
int b; 棧
char s[] = "abc"; 棧
char *p2; 棧
char *p3 = "123456"; //123456\0在常量區,p3在棧上。
static int c =0; 全局(靜態)初始化區
p1 = (char *)malloc(10); 堆
p2 = (char *)malloc(20); 堆
}
堆和棧的區別:
(a)申請方式和回收方式不同
1)棧(satck):由系統自動分配。例如,聲明在函數中一個局部變量int b;系統自動在棧中為b開辟空間。
2)堆(heap):需程序員自己申請(調用malloc,realloc,calloc),並指明大小,並由程序員進行釋放。容易產生memory leak.
例如:char *p;
p = (char *)malloc(sizeof(char));
但是,p本身是在棧中。
由於棧上的空間是自動分配自動回收的,所以棧上的數據的生存周期只是在函數的運行過程中,運行後就釋放掉,不可以再訪問。而堆上的數據只要程序員不釋放空間,就一直可以訪問到,不過缺點是一旦忘記釋放會造成內存洩露。
(b)申請後系統的響應
1)棧:只要棧的空間大於所申請空間,系統將為程序提供內存,否則將報異常提示棧溢出。
2)堆:首先應該知道操作系統有一個記錄空閒內存地址的鏈表,但系統收到程序的申請時,會遍歷該鏈表,尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閒鏈表中刪除,並將該結點的空間分配給程序,另外,對於大多數系統,會在這塊內存空間中的首地址處記錄本次分配的大小,這樣,代碼中的free語句才能正確的釋放本內存空間。另外,找到的堆結點的大小不一定正好等於申請的大小,系統會自動的將多余的那部分重新放入空閒鏈表中。
說明:對於堆來講,頻繁的new/delete勢必會造成內存空間的不連續,從而造成大量的碎片,使程序效率降低。對於棧來講,則不會存在這個問題。
堆會在申請後還要做一些後續的工作這就會引出申請效率的問題。
(c)申請效率
1)棧由系統自動分配,速度快。但程序員是無法控制。
2)堆是由malloc分配的內存,一般速度比較慢,而且容易產生碎片,不過用起來最方便。
(d)申請大小的限制
1)棧:在Windows下,棧是向低地址擴展的數據結構,是一塊連續的內存的區域。這句話的意思是棧頂的地址和棧的最大容量是系統預先規定好的,在 Windows下,棧的大小是2M(也有的說是1M,總之是一個編譯時就確定的常數),如果申請的空間超過棧的剩余空間時,將提示overflow。因此,能從棧獲得的空間較小。
2)堆:堆是向高地址擴展的數據結構,是不連續的內存區域。這是由於系統是用鏈表來存儲的空閒內存地址的,自然是不連續的,而鏈表的遍歷方向是由低地址向高地址。堆的大小受限於計算機系統中有效的虛擬內存。由此可見,堆獲得的空間比較靈活,也比較大。
(e)堆和棧中的存儲內容
1)棧: 在函數調用時,第一個進棧的是主函數中函數調用後的下一條指令(函數調用語句的下一條可執行語句)的地址,然後是函數的各個參數,在大多數的C編譯器中,參數是由右往左入棧的,然後是函數中的局部變量。注意靜態變量是不入棧的。
當本次函數調用結束後,局部變量先出棧,然後是參數,最後棧頂指針指向最開始存的地址,也就是主函數中的下一條指令,程序由該點繼續運行。
2)堆:一般是在堆的頭部用一個字節存放堆的大小。堆中的具體內容有程序員安排。
(f)存取效率
1)堆:char *s1=”hellow tigerjibo”;是在編譯是就確定的;
2)棧:char s1[]=”hellow tigerjibo”;是在運行時賦值的;用數組比用指針速度更快一些,指針在底層匯編中需要用edx寄存器中轉一下,而數組在棧上讀取。
補充:
棧是機器系統提供的數據結構,計算機會在底層對棧提供支持:分配專門的寄存器存放棧的地址,壓棧出棧都有專門的指令執行,這就決定了棧的效率比較高。堆則是C/C++函數庫提供的,它的機制是很復雜的,例如為了分配一塊內存,庫函數會按照一定的算法(具體的算法可以參考數據結構/操作系統)在堆內存中搜索可用的足夠大小的空間,如果沒有足夠大小的空間(可能是由於內存碎片太多),就有可能調用系統功能去增加程序數據段的內存空間,這樣就有機會分到足夠大小的內存,然後進行返回。顯然,堆的效率比棧要低得多。
(g)分配方式:
1)堆都是動態分配的,沒有靜態分配的堆。
2)棧有兩種分配方式:靜態分配和動態分配。靜態分配是編譯器完成的,比如局部變量的分配。動態分配由alloca函數進行分配,但是棧的動態分配和堆是不同的。它的動態分配是由編譯器進行釋放,無需手工實現。
最後,關於棧和堆一個形象的比喻:
使用棧就象我們去飯館裡吃飯,只管點菜(發出申請)、付錢、和吃(使用),吃飽了就走,不必理會切菜、洗菜等准備工作和洗碗、刷鍋等掃尾工作,好處是快捷,但是自由度小。
使用堆就象是自己動手做喜歡吃的菜肴,比較麻煩,但是比較符合自己的口味,而且自由度大。
2.堆棧和隊列(數據結構)
(1)堆棧
基本概念
(a)定義:限定只能在固定一端進行插入和刪除操作的線性表。
特點:後進先出。
(b)允許進行插入和刪除操作的一端稱為棧頂,另一端稱為棧底。
作用:可以完成從輸入數據序列到某些輸出數據序列的轉換。
堆棧抽象數據類型
數據集合:
{a0,a1,…,an-1} ,ai的數據類型為DataType。
操作集合:
(a) StackInitiate(S) :初始化堆棧S
(b) StackNotEmpty(S):堆棧S非空否
(c)StackPush(S, x) :入棧
(d)StackPop(S, d):出棧
(e)StackTop(S, d):取棧頂數據元素
堆棧類型
(a)順序堆棧
順序堆棧:順序存儲結構的堆棧。
順序棧的存儲結構:利用一組地址連續的存儲單元依次存放自棧底到棧頂的數據元素。

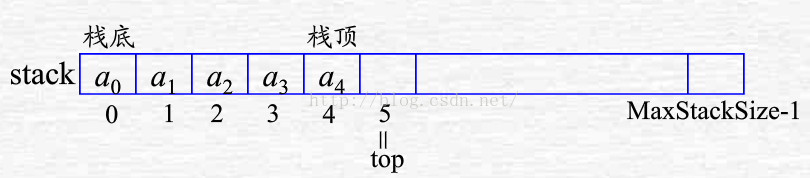
數據結構:
typedef struct
{
DataTypestack[MaxStackSize];
int top;
}SeqStack;
(b)鏈式堆棧
鏈式堆棧:鏈式存儲結構的堆棧。
鏈式棧的存儲結構:它是以頭指針為棧頂,在頭指針處插入或刪除,帶頭結點的鏈式堆棧結構:

鏈棧中每個結點由兩個域構成:data域和next域。
結點結構體定義如下
typedef struct snode
{
DataType data;
struct snode *next;
} LSNode;
采用鏈棧存儲方式的優點是:當棧中元素個數變化較大,准確數字難以確定時,鏈棧較順序堆棧方便。
(2)隊列
基本概念
定義:只能在表的一端進行插入操作(隊尾),在表的另一端進行刪除操作的線性表(隊頭)。一個隊列的示意圖如下:

隊列抽象數據類型
數據集合:{a0,a1,…,an-1},ai的數據類型為DataType。
操作集合:
(a)初始化QueueInitiate(Q)
(b)非空否QueueNotEmpty(Q)
(c)入隊列QueueAppend(Q,x)
(d)出隊列QueueDelete(Q,d)
(e)取隊頭數據元素QueueGet(Q, d)
隊列類型:
(a)順序隊列
順序隊列:順序存儲結構的隊列。
順序隊列的存儲結構:有6個存儲空間的順序隊列動態示意圖如下。
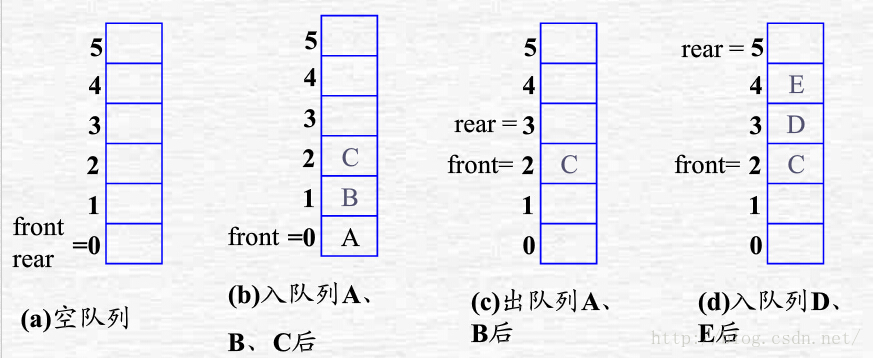
順序隊列的“假溢出”問題:因多次入隊列和出隊列操作後出現的雖有存儲空間但不能進行入隊列操作的情況。
可采取四種方法解決:
1)采用順序循環隊列;
2)按最大可能的進隊操作次數設置順序隊列的最大元素個數(最差的方法);
3)修改出隊算法,使每次出隊列後都把隊列中剩余數據元素向隊頭方向移動一個位置;
4)修改入隊算法,增加判斷條件,當假溢出時,把隊列中的數據元素向對頭移動,然後方完成入隊操作。
(b)順序循環隊列
基本原理:把順序隊列所使用的存儲空間構造成一個邏輯上首尾相連的循環隊列。當rear和front達到MaxQueueSize-1後,再前進一個位置就自動到0。
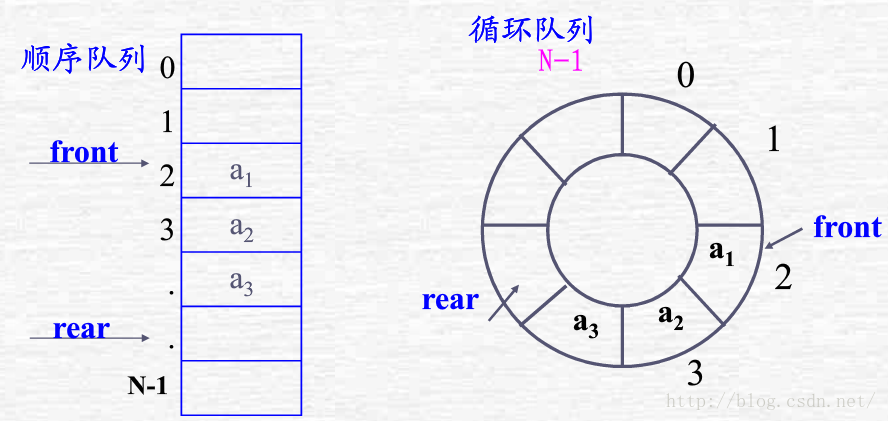
順序循環隊列的隊空和隊滿判斷問題:
在順序循環隊列中,隊空特征是front=rear,隊滿時也會是front=rear,判決條件將出現二義性,解決方案有三:
1)使用一個計數器記錄隊列中元素個數(即隊列長度);
判隊滿:count>0 && rear==front
判隊空:count==0
2)設標志位:出隊時置0,入隊時置1,則可識別當前front=rear 屬於何種情況;
判隊滿:tag==1 && rear==front
判隊空:tag==0 && rear==front
3)少用一個存儲單元
判隊滿:front=(rear+1)%MaxQueueSize
判隊空:rear==front
順序循環隊列的結構體定義如下:
typedef struct
{
DataType queue[MaxQueueSize];
int rear;
int front;
int count;
} SeqCQueue;
(c)鏈式隊列
鏈式隊列:鏈式存儲結構的隊列。
鏈式隊列的存儲結構:鏈式隊列的隊頭指針指向隊列的當前隊頭結點;隊尾指針指在隊列的當前隊尾結點。一個不帶頭結點的鏈式隊列的結構。

結點的結構體可定義如下:
typedef struct qnode
{
DataTypedata;
struct qnode*next;
}LQNode;
隊頭指針front和隊尾指針rear的結構體類型:
typedef struct
{
LQNode *front;
LQNode *rear;
}LQueue;
(d)優先級隊列
優先級隊列:帶有優先級的隊列。
順序優先級隊列:用順序存儲結構存儲的優先級隊列。
優先級隊列和一般隊列的主要區別:優先級隊列的出隊列操作不是把隊頭元素出隊列,而是把隊列中優先級最高的元素出隊列。
它的數據元素定義為如下結構體:
struct DataType
{
ElemType elem;//數據元素
int priority; //優先級
};
注:順序優先級隊列除出隊列操作外的其他操作的實現方法與前邊討論的順序隊列操作的實現方法相同。