sscanf() - 從一個字符串中讀進與指定格式相符的數據。
swscanf()- 用於處理寬字符字符串,和sscanf功能相同
通過學習和使用個人認為,在字符串格式不是很復雜,但是也並不簡單的時候用這個函數比較合適,這個尺度就要靠自己把握了,字符串不是很復雜,但自己寫個處理的函數比較麻煩,效率也不高,就用這個函數,如果字符串很復雜,那就用正則表達式吧。
不多說了,看看下面這些介紹和列子吧!
名稱:sscanf() - 從一個字符串中讀進與指定格式相符的數據.
函數原型:
Int sscanf( string str, string format, mixed var1, mixed var2 ... );
int scanf( const char *format [,argument]... );
說明:
sscanf與scanf類似,都是用於輸入的,只是後者以屏幕(stdin)為輸入源,前者以固定字符串為輸入源。
其中的format可以是一個或多個
{ % [*] [width] [{h | l | I64 | L}]type | ' ' | '\t' | '\n' | 非%符號}
支持集合操作:
%[a-z] 表示匹配a到z中任意字符,貪婪性(盡可能多的匹配)
%[aB'] 匹配a、B、'中一員,貪婪性
%[^a] 匹配非a的任意字符,貪婪性
例子:
1. 常見用法。
char buf[512] = {0};
sscanf("123456 ", "%s", buf);
printf("%s\n", buf);
結果為:123456
2.取指定長度的字符串。如在下例中,取最大長度為4字節的字符串。
sscanf("123456 ", "%4s", buf);
printf("%s\n", buf);
結果為:1234
3.取到指定字符為止的字符串。如在下例中,取遇到空格為止字符串。
sscanf("123456 abcdedf", "%[^ ]", buf);
printf("%s\n", buf);
結果為:123456
4. 取僅包含指定字符集的字符串。如在下例中,取僅包含1到9和小寫字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", buf);
printf("%s\n", buf);
結果為:123456abcdedf
5. 取到指定字符集為止的字符串。如在下例中,取遇到大寫字母為止的字符串。
sscanf("123456abcdedfBCDEF", "%[^A-Z]", buf);
printf("%s\n", buf);
結果為:123456abcdedf
6、給定一個字符串iios/12DDWDFF@122,獲取
/ 和 @ 之間的字符串,先將 "iios/"過濾掉,再將非'@'的一串內容送到buf中
sscanf("iios/12DDWDFF@122",
"%*[^/]/%[^@]", buf);
printf("%s\n", buf);
結果為:12DDWDFF
7、給定一個字符串““hello, world”,僅保留world。(注意:“,”之後有一空格)
sscanf(“hello, world”, "%*s%s", buf);
printf("%s\n", buf);
結果為:world
%*s表示第一個匹配到的%s被過濾掉,即hello被過濾了
如果沒有空格則結果為NULL。
8、 char *s="1try234delete5"
則: sscanf(s, "1%[^2]234%[^5]", s1, s2);
scanf的format中出現的非轉換字符(%之前或轉換字符之後的字符),即此例中的1234用來跳過輸入中的相應字符;
‘[]’的含義與正則表達式中相同,表示匹配其中出現的字符序列;^表示相反。使用[ ]時接收輸入的變量必須是有足夠存儲空間的char、signed char、unsigned char數組。記住[也是轉換字符,所以沒有s了。
8、分割以某字符標記的字符串。
char test[]="222,333,444,,,555,666";
char s1[4],s2[4],s3[4],s4[4],s5[4],s6[4],s7[4];
sscanf(test,"%[^,],%[^,],%[^,],%[^,],%[^,],%[^,],%[^,]",s1,s2,s3,s4,s5,s6,s7);
printf("sssa1=%s",s1);
printf("sssa2=%s",s2);
printf("sssa3=%s",s3);
printf("sssa4=%s",s4);
printf("sssa5=%s",s5);
printf("sssa6=%s",s6);
printf("sssa7=%s",s7);
9、一個提取用戶個人資料中郵件地址的例子
#include
#include
using namespace std;
int main()
{
char a[20]={0};
char b[20]={0};
//假設email地址信息以';'結束
sscanf("email:[email protected];","%*[^:]:%[^;]",a);
//假設email地址信息沒有特定的結束標志
sscanf("email:[email protected]","%*[^:]:%s",b);
printf("%s\n",a);
printf("%s\n",b);
system("pause");
return 0;
}
關鍵是"%*[^:]:%[^;]"和"%*[^:]:%s"這兩個參數的問題
%*[^:] 表示滿足"[]"裡的條件將被過濾掉,不會向目標參數中寫入值。這裡的意思是在
第一個':'之前的字符會在寫入時過濾掉,'^'是表示否定的意思,整個參數翻譯
成白話就是:將在遇到第一個':'之前的(不為':'的)字符全部過濾掉。
: 自然就是跳過':'的意思。
%[^;] 拷貝字符直到遇到';'。
一下摘自:http://blog.csdn.net/lbird/archive/2007/08/03/1724429.aspx
%[ ] 的用法:%[ ]表示要讀入一個字符集合, 如果[ 後面第一個字符是”^”,則表示反意思。
[ ]內的字符串可以是1或更多字符組成。空字符集(%[])是違反規定的,可
導致不可預知的結果。%[^]也是違反規定的。
%[a-z] 讀取在 a-z 之間的字符串,如果不在此之前則停止,如
char s[]="hello, my friend” ; // 注意: ,逗號在不 a-z之間
sscanf( s, “%[a-z]”, string ) ; // string=hello
%[^a-z] 讀取不在 a-z 之間的字符串,如果碰到a-z之間的字符則停止,如
char s[]="HELLOkitty” ; // 注意: ,逗號在不 a-z之間
sscanf( s, “%[^a-z]”, string ) ; // string=HELLO
%*[^=] 前面帶 * 號表示不保存變量。跳過符合條件的字符串。
char s[]="notepad=1.0.0.1001" ;
char szfilename [32] = "" ;
int i = sscanf( s, "%*[^=]", szfilename ) ; // szfilename=NULL,因為沒保存
int i = sscanf( s, "%*[^=]=%s", szfilename ) ; // szfilename=1.0.0.1001
%40c 讀取40個字符
%[^=] 讀取字符串直到碰到’=’號,’^’後面可以帶更多字符,如:
char s[]="notepad=1.0.0.1001" ;
char szfilename [32] = "" ;
int i = sscanf( s, "%[^=]", szfilename ) ; // szfilename=notepad
如果參數格式是:%[^=:] ,那麼也可以從 notepad:1.0.0.1001讀取notepad
使用例子:
char s[]="notepad=1.0.0.1001" ;
char szname [32] = "" ;
char szver [32] = “” ;
sscanf( s, "%[^=]=%s", szname , szver ) ; // szname=notepad, szver=1.0.0.1001
總結:%[]有很大的功能,但是並不是很常用到,主要因為:
1、許多系統的 scanf 函數都有漏洞. (典型的就是 TC 在輸入浮點型時有時會出錯).
2、用法復雜, 容易出錯.
3、編譯器作語法分析時會很困難, 從而影響目標代碼的質量和執行效率.
個人覺得第3點最致命,越復雜的功能往往執行效率越低下。而一些簡單的字符串分析我們可以自已處理。
Sprintf()字符串格式化命令
主要功能是把格式化的數據寫入某個字符串中。sprintf 是個變參函數
Sprintf
函數聲明:int sprintf(char *buffer, const char *format [, argument1, argument2, …])
用途:將一段數據寫入以地址buffer開始的字符串緩沖區
所屬庫文件:
參數:(1)buffer,將要寫入數據的起始地址;(2)format,寫入數據的格式;(3)argument:要寫的數據,可以是任何格式的。
返回值:實際寫入的字符串長度
說明:此函數需要注意緩沖區buffer溢出,要為寫入的argument留足長度,可以用來代替itoa,即把整數轉化為字符串。
Snprintf
函數聲明:int snprintf(char *str, size_t size, const char *format, …)
用途:sprintf的安全模式,比sprintf多一個參數size。將一段數據寫入以地址str開始的字符串緩沖區。字符串長度最大不超過長度size。如果超過或等於,則只寫入size-1個,後面補個'\0'。
所屬庫文件:
參數:(1)str,將要寫入數據的起始地址;(2)size,寫入數據的最大長度(實際寫入肯定小於等於此值,包括'\0');(3)format,寫入數據的格式;(4)argument(省略號),要寫的數據
例如:
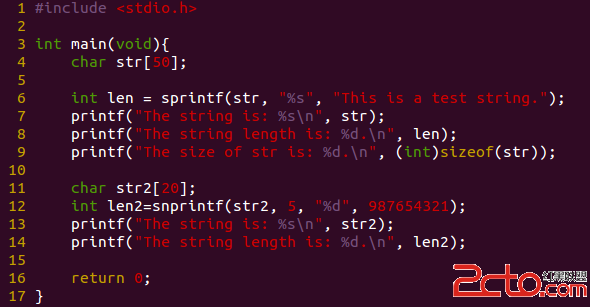
運行後結果為
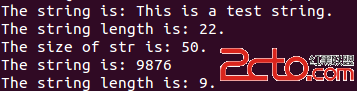
需要注意的是,snprintf返回值是format過後字符串的長度,並不是實際拷進字符串緩沖區的長度。
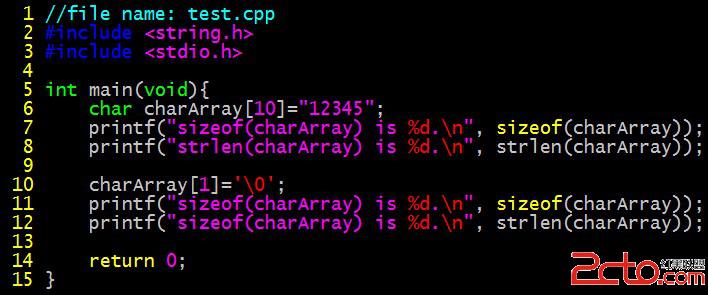
C語言常用函數strlen的使用方法
函數聲明:extern unsigned int strlen(char *s);
所屬函數庫:<�喎?/kf/ware/vc/" target="_blank" class="keylink">vcD4KPHA+CrmmxNyjure1u9hzy/nWuLXE19a3+7SutcSzpLbIo6zG5NbQ19a3+7SusdjQ69LUoa9cMKGvveHOsjwvcD4KPHA+CrLOyv2junPOqtfWt/u0rrXEs/XKvLXY1rc8L3A+CjxwPgrKudPDvtnA/aO6PC9wPgo8cD4KtPrC68jnz8I8L3A+CjxwIGFsaWduPQ=="left">
編譯運行結果
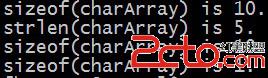
說明:
函數strlen比較容易理解,其功能和sizeof很容易混淆。其中sizeof指的是字符串聲明後占用的內存長度,它就是一個操作符,不是函數;而strlen則是一個函數,它從第一個字節開始往後數,直到遇見了’\0’,則停止。
C語言常用函數memset的使用方法
函數聲明:void *memset(void *s, int ch, size_t n);
用途:為一段內存的每一個字節都賦予ch所代表的值,該值采用ASCII編碼。
所屬函數庫: 或者
參數:(1)s,開始內存的地址;(2)ch和n,從地址s開始,在之後的n字節長度內,把每一個字節的值都賦值為n。
使用舉例:
代碼如下
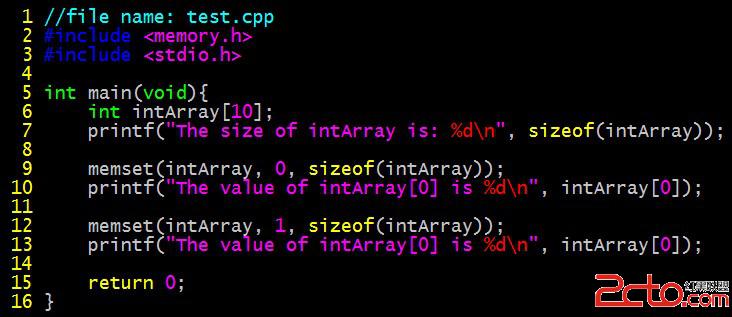
編譯運行結果

說明:
該函數最常用的用途就是將一段新分配的內存初始化為0。例如我們代碼的第9-10行。
需要注意的是,函數第二個參數的值代表的是即將設置的每個字節的值,因此對於第二個參數不是0的情況要格外小心。例如我們代碼的第12-13行。intArray[0]本來是一個四字節的整數,它的每一個字節都將變成1。第12行運行完畢,intArray[0]的內容如下
(二進制)00000001 00000001 00000001 00000001 = (十進制)16843009
這也是為什麼第13行輸出的結果是16843009。