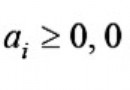假如你正在寫從文件或網絡讀寫數據的跨平台C/C++代碼,那麼你必須明白有些問題是因語言,編譯器,平台而不同的。 主要的問題是數據對齊,填充,類型大小,字節順序和默認狀態char是否有符號。
對齊
特定機器上,特定的數據被對齊於特定的邊界。假如數據沒有正確對齊,結果可能是效率降低甚至崩潰。 當你從I/O源讀取數據的時候,確保對齊是正確的。
填充
"填充" 是數據集合中不同元素之間的間隔, 一般是為了對齊而存在。不同編譯器和平台下,填充的數量可能會不同。?不要假設結構的大小和成員的位置在任何編譯器和平台下都是相同的。 不要一次性讀取或者寫入一整個結構體,因為寫入的程序可能會使用和讀取的程序不同的填充方式。對於域也同樣適用。
類型大小
不同數據類型的大小隨編譯器和平台而不同。 在C/C++中, 內置類型的大小完全取決於編譯器(在特定范圍內). 不要讀寫大小不明確的數據類型。也就是說,不要讀寫bool, enum, long, int, short, float, 或者double類型.(譯者注:事實似乎不是這樣,我記得C/C++標准規定了一些數據類型的長度,例如short 2字節,long 4字節等等,在符合標准規定的編譯器上,使用這些類型可以保證跨平台的正確性)

字節順序
字節順序,就是字節在內存中存儲的順序。 不同的處理器存儲多字節數據的順序是不同的。 小端處理器由低到高存儲(換句話說,和書寫的順序相反).。大端處理器由高到低存儲(和書寫順序相同)。假如數值的字節順序和讀寫它的處理器不同,它必須被事先轉化。同時,為了標准化網絡傳輸的字節順序,定義了網絡字節順序。
char - 有符號還是無符號?
一個鮮為人知的事實,char默認可以是有符號的也可以是無符號的-完全取決於編譯器。結果導致你從char轉化為其他類型的時候(比如int),結果會因編譯器而不同。 例如:
char x;
int y;
read( fd, &x, 1 ); // 讀取一個byte值為0xff
y = x; // y 是 255 或者 -1, 依靠編譯器
不要把數據讀入一般的char。明確指定是有符號或者無符號的。