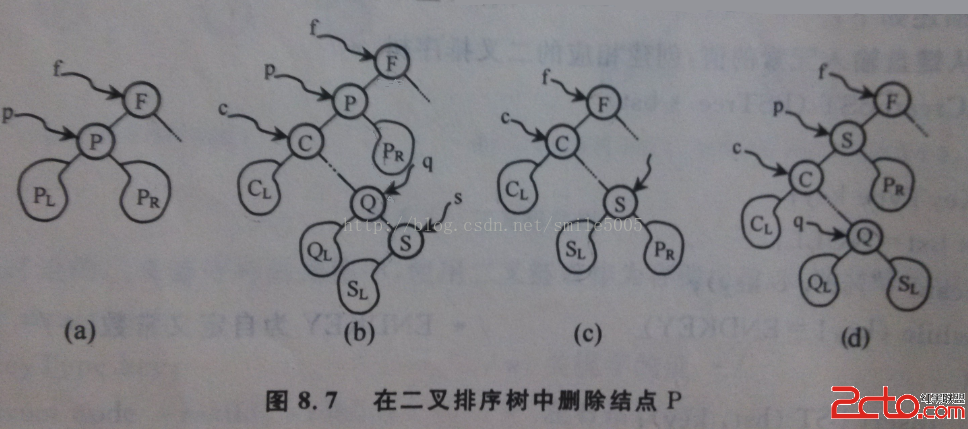
對於絕大多數實時程序來說,實時處理相關程序中的循環問題所帶來的對機器的損耗和自身的處理速度的平衡,以及與其他程序的交互以及對其他功能的影響難免會成為程序設計中最大的障礙同時也是最大的突破點。
在所有這類問題面前,我們統一的解決方案幾乎都是多線程操作,一點點將機器的性能發揮到我們可以控制的最大,並將我們處理速度提升到我們可以控制的最高高度。
然而,對於很多人來說,多線程所帶來的不穩定性無疑就是噩夢。
譬如:
起初我們在寫單線程程序時,我們塑造了一條流水線,流水線上有幾個環節,我們安排了一個工人,按部就班地將一個產品的一個個環節走完,然後再進行下一個產品的工作,慢慢地,隨著對處理速度的要求和機器性能的提升,這種方案越來越out,我們開始借助多線程,我們指派多個工人甚至幾十個工人同時作業,但是隨著速度的幾何倍的提升,真正的問題接踵而來。
我們開始拆分流水線上的環節,將工人們開始按照每個流水線上的環節的工作強度開始分配人數。然而隨著程序的不斷的累加代碼和功能,有兩個問題在我們的開發環節中越來越明顯,會極大的造成後期維護的精力和難度,最嚴重時甚至能毀掉整個程序---那就是內存和CPU的問題。
內存問題及解決方案:
在流水線中我們使用類將一個個我們的邏輯功能進行封裝,隨著處理要求的提升,我們不斷地完善我們底層的內存塊和內存池,不過隨著代碼的冗雜,裡面必然會出現無法釋放的內存塊或超出使用的內存塊,這樣輕則會造成程序占用內存越來越高,重則導致指針亂調導致程序崩潰甚至數據莫名其妙的混亂。
解決的思路我們可以密切的監視每塊的內存的創建和銷毀階段,如我們在內存申請時向裡面加點料,再在內存銷毀時檢測一下我們加的料。
CPU高及解決方案:
隨著任務環節的越來越多,我們將我們程序分層,中間以各種方式鏈接,但是盡管多麼合格的數據結構去協調各個環節,總有環節對接失誤的時候,緊接著隨之到來便是循環執行次數過多甚至會導致死循環,更嚴重的會出現死鎖的情況。
我們面對這種情況,如果我們在設計程序就想到了,我們可以仔細分析各個環節然後對整個結構提出最具有包容性。然而我們再後期擴展之時遇到只能不斷地優化,邏輯清晰化。