學習Java的同學注意了!!!
學習過程中遇到什麼問題或者想獲取學習資源的話,歡迎加入Java學習交流群,群號碼:279558494 我們一起學Java!
本文主要從整體上介紹Java中的多線程技術,對於一些重要的基礎概念會進行相對詳細的介紹,若有敘述不清晰或是不正確的地方,希望大家指出,謝謝大家:)
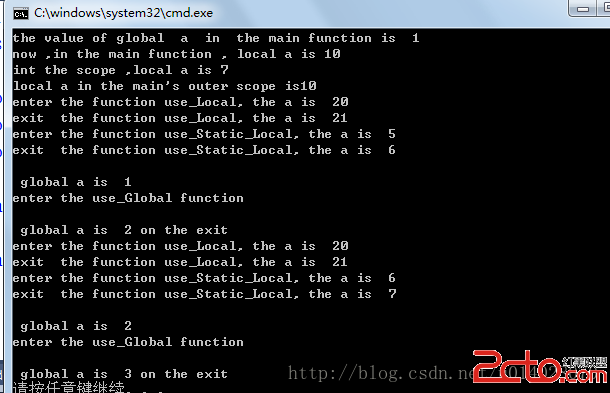
我們知道,在單核機器上,“多進程”並不是真正的多個進程在同時執行,而是通過CPU時間分片,操作系統快速在進程間切換而模擬出來的多進程。我們通常把這種情況成為並發,也就是多個進程的運行行為是“一並發生”的,但不是同時執行的,因為CPU核數的限制(PC和通用寄存器只有一套,嚴格來說在同一時刻只能存在一個進程的上下文)。
現在,我們使用的計算機基本上都搭載了多核CPU,這時,我們能真正的實現多個進程並行執行,這種情況叫做並行,因為多個進程是真正“一並執行”的(具體多少個進程可以並行執行取決於CPU核數)。綜合以上,我們知道,並發是一個比並行更加寬泛的概念。也就是說,在單核情況下,並發只是並發;而在多核的情況下,並發就變為了並行。下文中我們將統一用並發來指代這一概念。
UNIX系統內核提供了一個名為read的函數,用來讀取文件的內容:
typedef ssize_t int;typedef size_t unsigned;ssize_t read(int fd,
void *buf, size_t n);這個函數從描述符為fd的當前文件位置復制至多n個字節到內存緩沖區buf。若執行成功則返回讀取到的字節數;若失敗則返回-1。read系統調用默認會阻塞,也就是說系統會一直等待這個函數執行完畢直到它產生一個返回值。然而我們知道,磁盤通常是一種慢速I/O設備,這意味著我們用read函數讀取磁盤文件內容時,往往需要比較長的時間(相對於訪問內存來說)。那麼阻塞的時候我們當然不想讓系統傻等著,我們想在這期間做點兒別的事情,等著磁盤准備好了通知我們一下,我們再來讀取文件內容。實際上,操作系統正是這樣做的。當阻塞在read這類系統調用中的時候,操作系統通常都會讓該進程暫時休眠,調度一個別的進程來執行,以免干等著浪費時間,等到磁盤准備好了可以讓我們來進行I/O了,它會發送一個中斷信號通知操作系統,這時候操作系統重新調度原來的進程來繼續執行read函數。這就是通過多進程實現的並發。
進程就是一個執行中的程序實例,而線程可以看作一個進程的最小執行單元。線程與進程間的一個顯著區別在於每個進程都有一整套變量,而同一個進程間的多個線程共享該進程的數據。也就是說在通常情況下,多線程在數據共享上要比多進程更加便捷。
然而,有時候,多線程共享數據的便捷容易可能會成為一個讓我們頭疼的問題,我們在後文中會具體提到常見的問題及相應的解決方案。在上面的read函數的例子中,如果我們使用多線程,可以使用一個主線程去進行I/O的工作,再用一個或幾個工作線程去執行一些輕量計算任務,這樣當主線程阻塞時,線程調度程序會調度我們的工作線程來執行計算任務,從而更加充分的利用CPU時間片。而且,在多核機器上,我們的多個線程可以並行執行在多個核上,進一步提升效率。
每個進程剛被創建時都只含有一個線程,這個線程通常被稱作主線程(main thread)。而後隨著進程的執行,若遇到創建新線程的代碼,就會創建出新線程,而後隨著新線程被啟動,多個線程就會並發地運行。某時刻,主線程阻塞在一個慢速系統調用中(比如前面提到的read函數),這時線程調度程序會讓主線程暫時休眠, 調度另一個線程來作為當前運行的線程。
在Java中,有兩種方法可以創建一個新線程。第一種方法是定義一個實現Runnable接口的類並實例化,然後將這個對象傳入Thread的構造器來創建一個新線程,如以下代碼所示:
class MyRunnable implements Runnable {
...
public void run() {
//這裡是新線程需要執行的任務
}
}
Runnable r = new MyRunnable();
Thread t = new Thread(r);第二種創建一個新線程的方法是直接定義一個Thread的子類並實例化,從而創建一個新線程。比如以下代碼:
class MyThread extends Thread {
public void run() {
//這裡是線程要執行的任務
}
}創建了一個線程對象後,我們直接對其調用start方法即可啟動這個線程:
t.start();既然有兩種方式可以創建線程,那麼我們該使用哪一種呢?首先,直接繼承Thread類的方法看起來更加方便,但它存在一個局限性:由於Java中不允許多繼承,我們自定義的類繼承了Thread後便不能再繼承其他類,這在有些場景下會很不方便;實現Runnable接口的那個方法雖然稍微繁瑣些,但是它的優點在於自定義的類可以繼承其他的類。
線程在它的生命周期中可能處於以下幾種狀態之一:
後文中若不加特殊說明的話,我們會用阻塞狀態統一指代Blocked、Waiting、Time Waiting。
在Java中,每個線程都有一個優先級,默認情況下,線程會繼承它的父線程的優先級。可以用setPriority方法來改變線程的優先級。Java中定義了三個描述線程優先級的常量:MAX_PRIORITY、NORM_PRIORITY、MIN_PRIORITY。
每當線程調度器要調度一個新的線程時,它會首先選擇優先級較高的線程。然而線程優先級是高度依賴於操作系統的,在有些系統的Java虛擬機中,甚至會忽略線程的優先級。因此我們不應該將程序邏輯的正確性依賴於優先級。線程優先級相關的API如下:
void setPriority(int newPriority) //設置線程的優先級,可以使用系統提供的三個優先級常量
static void yield() //使當前線程處於讓步狀態,這樣當存在其他優先級大於等於本線程的線程時,線程調度程序會調用那個線程Thread實現了Runnable接口,關於這個類的以下實例域需要我們了解:
private volatile char name[]; //當前線程的名字,可在構造器中指定
private int priority; //當前線程優先級
private Runnable target; //當前要執行的任務
private long tid; //當前線程的IDThread類的常用方法除了我們之前提到的用於啟動線程的start外還有:
sleep方法: 這是一個靜態方法,作用是讓當前線程進入休眠狀態(但線程不會釋放已獲取的鎖),這個休眠狀態其實就是我們上面提到過的Time Waiting狀態,從休眠狀態“蘇醒”後,線程會進入到Runnable狀態。sleep方法有兩個重載版本,聲明分別如下:
//讓當前線程休眠millis指定的毫秒數
public static native void sleep(long millis) throws InterruptedException;
//在毫秒數的基礎上還指定了納秒數,控制粒度更加精細
public static native void sleep(long millis, int nanos) throws InterruptedException;join方法: 這是一個實例方法,在當前線程中對一個線程對象調用join方法會導致當前線程停止運行,等那個線程運行完畢後再接著運行當前線程。也就是說,把當前線程還沒執行的部分“接到”另一個線程後面去,另一個線程運行完畢後,當前線程再接著運行。join方法有以下重載版本:
public final synchronized void join() throws InterruptedException;
public final synchronized void join(long millis) throws InterruptedException;
public final synchronized void join(long millis, int nanos) throws InterruptedException;無參數的join表示當前線程一直等到另一個線程運行完畢,這種情況下當前線程會處於Wating狀態;帶參數的表示當前線程只等待指定的時間,這種情況下當前線程會處於Time Waiting狀態。當前線程通過調用join方法進入Time Waiting或Waiting狀態後,會釋放已經獲取的鎖。實際上,join方法內部調用了Object類的實例方法wait,關於這個方法我們下面會具體介紹。
yield方法,這是一個靜態方法,作用是讓當前線程“讓步”,目的是為了讓優先級不低於當前線程的線程有機會運行,這個方法不會釋放鎖。
interrupt方法,這是一個實例方法。每個線程都有一個中斷狀態標識,這個方法的作用就是將相應線程的中斷狀態標記為true,這樣相應的線程調用isInterrupted方法就會返回true。通過使用這個方法,能夠終止那些通過調用可中斷方法進入阻塞狀態的線程。常見的可中斷方法有sleep、wait、join,這些方法的內部實現會時不時的檢查當前線程的中斷狀態,若為true會立刻拋出一個InterruptedException異常,從而終止當前線程。
以下這幅圖很好的诠釋了隨著各種方法的調用,線程在不同的狀態之間的切換(圖片來源:http://www.cnblogs.com/dolphin0520/p/3920357.html):
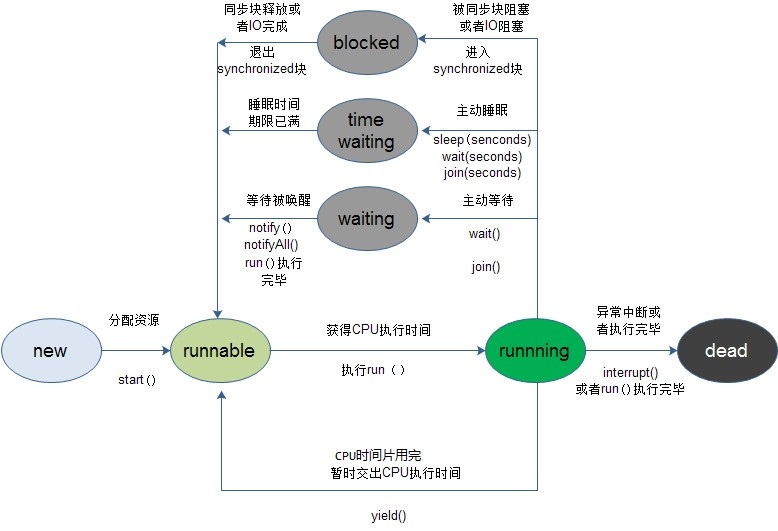
wait方法是Object類中定義的實例方法。在指定對象上調用wait方法能夠讓當前線程進入阻塞狀態(前提時當前線程持有該對象的內部鎖(monitor)),此時當前線程會釋放已經獲取的那個對象的內部鎖,這樣一來其他線程就可以獲取這個對象的內部鎖了。當其他線程獲取了這個對象的內部鎖,進行了一些操作後可以調用notify方法來喚醒正在等待該對象的線程。
notify/notifyAll方法也是Object類中定義的實例方法。它倆的作用是喚醒正在等待相應對象的線程,區別在於前者喚醒一個等待該對象的線程,而後者喚醒所有等待該對象的線程。這麼說比較抽象,下面我們來舉一個具體的例子來說明以下wait和notify/notifyAll的用法。請看以下代碼(轉自[Java並發編程:線程間協作的兩種方式]
1 public class Test {
2 private int queueSize = 10;
3 private PriorityQueue<Integer> queue = new PriorityQueue<Integer>(queueSize);
4
5 public static void main(String[] args) {
6 Test test = new Test();
7 Producer producer = test.new Producer();
8 Consumer consumer = test.new Consumer();
9
10 producer.start();
11 consumer.start();
12 }
13
14 class Consumer extends Thread{
15
16 @Override
17 public void run() {
18 consume();
19 }
20
21 private void consume() {
22 while(true){
23 synchronized (queue) {
24 while(queue.size() == 0){
25 try {
26 System.out.println("隊列空,等待數據");
27 queue.wait();
28 } catch (InterruptedException e) {
29 e.printStackTrace();
30 queue.notify();
31 }
32 }
33 queue.poll(); //每次移走隊首元素
34 queue.notify();
35 System.out.println("從隊列取走一個元素,隊列剩余"+queue.size()+"個元素");
36 }
37 }
38 }
39 }
40
41 class Producer extends Thread{
42
43 @Override
44 public void run() {
45 produce();
46 }
47
48 private void produce() {
49 while(true){
50 synchronized (queue) {
51 while(queue.size() == queueSize){
52 try {
53 System.out.println("隊列滿,等待有空余空間");
54 queue.wait();
55 } catch (InterruptedException e) {
56 e.printStackTrace();
57 queue.notify();
58 }
59 }
60 queue.offer(1); //每次插入一個元素
61 queue.notify();
62 System.out.println("向隊列取中插入一個元素,隊列剩余空間:"+(queueSize-queue.size()));
63 }
64 }
65 }
66 }
67 }以上代碼描述的是經典的“生產者-消費者”問題。Consumer類代表消費者,Producer類代表生產者。在生產者進行生產之前(對應第48行的produce方法),會獲取queue的內部鎖(monitor)。然後判斷隊列是否已滿,若滿了則無法再生產,所以在第54行調用queue.wait方法,從而等待在queue對象上。(釋放了queue的內部鎖)此時生產者能夠能夠獲取queue的monitor從而進入第21行的consume方法,這樣一來它就會通過第33行的queue.poll方法進行消費,於是隊列不再滿了,接著它在第34行調用queue.notify方法來通知正在等待的生產者,生產者就會從剛才阻塞的wait方法(第54行)中返回。
同理,當隊列空時,消費者也會等待(第27行)生產者來喚醒(第61行)。
await方法和signal/signalAll方法是wait方法和notify/notifyAll方法的升級版,在後文中會具體介紹它們與wait、notify/notifyAll之間的關系。
所謂線程安全,指的是當多個線程並發訪問數據對象時,不會造成對數據對象的“破壞”。保證線程安全的一個基本思路就是讓訪問同一個數據對象的多個線程進行“排隊”,一個接一個的來,這樣就不會對數據造成破壞,但帶來的代價是降低了並發性。
當兩個或兩個以上的線程同時修改同一數據對象時,可能會產生不正確的結果,我們稱這個時候存在一個競爭條件(race condition)。在多線程程序中,我們必須要充分考慮到多個線程同時訪問一個數據時可能出現的各種情況,確保對數據進行同步存取,以防止錯誤結果的產生。請考慮以下代碼:
public class Counter {
private long count = 0;
public void add(long value) {
this.count = this.count + value;
}
}我們注意一下改變count值的那一行,通常這個操作不是一步完成的,它大概分為以下三步:
我們可以編譯以上代碼然後用javap查看下編譯器為我們生成的字節碼:
我們可以看到,大致過程和我們以上描述的基本一樣。那麼我們考慮下面這樣一個場景:假設count的初值為0,首先線程A加載了count到寄存器中,並且加上了1,而就當它要寫回之前,線程B進入了add方法,它加載了count到寄存器中(由於此時線程A還沒有把count寫回,因此count還是0),並加上了2,然後線程B寫回了count。在線程B完成了寫回後,線程調度程序調度了線程A,線程A也寫回了count。注意,此時count的值為1而不是我們希望的三。我們不希望一個線程在執行add方法時被其他線程打斷,因為這會造成數據的破壞。我們希望的情況是這樣的:線程A完整執行完畢add方法後,待count變量的值更新為1時,線程B開始執行add方法,在線程B完整執行完畢之前, 沒有別的線程能夠打斷它,若有別的線程想調用add,也得等線程B執行完畢寫回count值後。
像add這種方法代碼所在的內存區,我們稱之為臨界區(critical area)。對於臨界區,在同一時刻我們只希望有一個線程能夠訪問它,我們希望在一個線程進入臨界區後把通往這個區的門“上鎖”,離開後把門"解鎖“,這樣當一個線程執行臨界區的代碼時其他想要進來的線程只能在門外等著,這樣可以保證了多個線程共享的數據不會被破壞。下面我們來介紹下為臨界區“上鎖”的方法。
Java類庫中為我們提供了能夠給臨界區“上鎖”的ReentrantLock類,它實現了Lock接口,在進一步介紹ReentrantLock類之前,我們先來看一下Lock接口的定義:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}我們來分別介紹下Lock接口中的方法:
tryLock方法也是用來獲取鎖的,它的無參版本在獲取不到鎖時會立刻返回false,它的計時等待版本會在等待指定時間還獲取不到鎖時返回false,計時等待的tryLock在阻塞期間也能夠被中斷。使用tryLock方法的典型代碼如下:
if (myLock.tryLock()) {
try {
…
} finally {
myLock.unlock();
}
} else {
//做其他的工作
}unlock方法用來釋放鎖;
ReentrantLock類是唯一一個Lock接口的實現類,它的意思是可重入鎖,關於“可重入”的概念我們下面會進行介紹。有了上面的介紹,理解它的使用方法就很簡單了,比如下面的代碼即完成了給add方法“上鎖”:
Lock myLock = new ReentrantLock();
public void add(long value) {
myLock.lock();
try {
this.count = this.count + value;
} finally {
myLock.unlock();
}
}從以上代碼可以看到,使用ReentrantLock對象來上鎖時只需要先獲取一個它的實例。然後通過lock方法進行上鎖,通過unlock方法進行解鎖。注意,我們使用了一個try-finally塊,以確保即使發生異常也總是會解鎖,不然其他線程會一直無法執行add方法。當一個線程執行完“myLock.lock()”時,它就獲得了一個鎖對象,這就相當於它給臨界區上了鎖,其他線程都無法進來,只有這個線程執行完“myLock.unlock()"時,釋放了鎖對象,其他線程才能再通過“myLock.lock()"獲得鎖對象,從而進入臨界區。也就是說,當一個線程獲取了鎖對象後,其他嘗試獲取鎖對象的線程都會被阻塞,進入Blocked狀態,直至獲取鎖對象的線程釋放了鎖對象。
有了鎖對象,盡管線程A在執行add方法的過程中被線程調度程序剝奪了運行權,其他的線程也進入不了臨界區,因為線程A還在持有鎖對象。這樣一來,我們就很好的保護了臨界區。
ReentrantLock鎖是可重入的,這意味著線程可以重復獲得已經持有的鎖,每個鎖對象內部都持有一個計數,每當線程獲取依次鎖對象,這個計數就加1,釋放一次就減1。只有當計數值變為0時,才意味著這個線程釋放了鎖對象,這時其他線程才可以來獲取。
有些時候,線程進入臨界區後不能立即執行,它需要等某一條件滿足後才開始執行。比如,我們希望count值大於5的時候才增加它的值,我們最先想到的是加個條件判斷:
public void add(int value) {
if (this.count > 5) {
this.count = this.count + value;
}
}然而上面的代碼存在一個問題。假設線程A執行完了條件判斷並的值count值大於5,而在此時該線程被線程調度程序中斷執行,轉而調度線程B,線程B對同一counter對象的count值進行了修改,使得它不再大於5,這時線程調度程序又來調度線程A,線程A剛才判定了條件為真,所以會執行add方法,盡管此時count值已不再大於5。顯然,這與我們所希望的情況的不符的。對於這種問題,我們想到了可以在條件判斷前後加鎖與解鎖:
public void add(int value) {
myLock.lock();
try {
while (counter.getCount() <= 5) {
//等待直到大於5
}
this.count = this.count + value;
} finally {
myLock.unlock();
}
}在以上代碼中,若線程A發現count值小於等於5,它會一直等到別的線程增加它的值直到它大於5。然而線程A此時持有鎖對象,其他線程無法進入臨界區(add方法內部)來改變count的值,所以當線程A進入臨界區時若count小於等於5,線程A會一直在循環中等待,其他的線程也無法進入臨界區。這種情況下,我們可以使用條件對象來管理那些已經獲得了一個鎖卻不能開始干活的線程。一個鎖對象可以有一個或多個相關的條件對象,在鎖對象上調用newCondition方法就可以獲得一個條件對象。比如我們可以為“count值大於5”獲得一個條件對象:
Condition enoughCount = myLock.newCondition();然後,線程A發現count值不夠時,調用“enoughCount.await()”即可,這時它便會進入Waiting狀態,放棄它持有的鎖對象,以便其他線程能夠進入臨界區。當線程B進入臨界區修改了count值後,發現了count值大於5,線程B可通過"enoughCount.signalAll()"來“喚醒所有等待這一條件滿足的線程(這裡只有線程A)。此時線程A會從Waiting狀態進入Runnable狀態。當線程A再次被調度時,它便會從await方法返回,重新獲得鎖並接著剛才繼續執行。注意,此時線程A會再次測試條件是否滿足,若滿足則執行相應操作。也就是說signalAll方法僅僅是通知線程A一聲count的值可能大於5了,應該再測試一下。還有一個signal方法,會隨機喚醒一個正在等待某條件的線程,這個方法的風險在於若隨機喚醒的線程測試條件後發現仍然不滿足,它還是會再次進入Waiting狀態,若以後不再有線程喚醒它,它便不能再運行了。
Java中的每個對象都有一個內部鎖,這個內部鎖也被稱為監視器(monitor);每個類內部也有一個鎖,用於控制多個線程對其靜態成員的並發訪問。若一個實例方法用synchronized關鍵字修飾,那麼這個對象的內部鎖會“保護”此方法,我們稱此方法為同步方法。這意味著只有獲取了該對象內部鎖的線程才能夠執行此方法。也就是說,以下的代碼:
public synchronized void add(int value) {
...
}等價於:
public void add(int value) {
this.innerLock.lock();
try {
...
} finally {
this.innerLock.unlock();
}
}這意味著,我們通過給add方法加上synchronized關鍵字即可保護它,加鎖解鎖的工作不需要我們再手動完成。對象的內部鎖在同一時刻只能由一個線程持有,其他嘗試獲取的線程都會被阻塞直至該線程釋放鎖,這種情況下被阻塞的線程無法被中斷。
內部鎖對象只有一個相關條件。wait方法添加一個線程到這個條件的等待集中;notifyAll / notify方法會喚醒等待集中的線程。也就是說wait() / notify()等價於enoughCount.await() / enoughCount.signAll()。以上add方法我們可以這麼實現:
public synchronized void add(int value) {
while (this.count <= 5) {
wait();
}
this.count += value;
notifyAll();
}這份代碼顯然比我們上面的實現要簡潔得多,實際開發中也更加常用。
我們也可以用synchronized關鍵字修飾靜態方法,這樣的話,進入該方法的線程或獲取相關類的Class對象的內部鎖。例如,若Counter中含有一個synchronized關鍵字修飾的靜態方法,那麼進入該方法的線程會獲得Bank.class的內部鎖。這意味著其他任何線程不能執行Counter類的任何同步靜態方法。
對象內部鎖存在一些局限性:
那麼我們究竟應該使用Lock/Condition還是synchronized關鍵字呢?答案是能不用盡量都不用,我們應盡可能使用java.util.concurrent包中提供給我們的相應機制(後面會介紹)。
當我們要在synchronized關鍵字與Lock間做出選擇時我們需要考慮以下幾點:
上面我們提到了一個線程調用synchronized方法可以獲得對象的內部鎖(前提是還未被其他線程獲取),獲得對象內部鎖的另一種方法就是通過同步阻塞:
synchronized (obj) {
//臨界區
}一個線程執行上面的代碼塊便可以獲取obj對象的內部鎖,直至它離開這個代碼塊才會釋放鎖。
我們經常會看到一種特殊的鎖,如下所示:
public class Counter {
private Object lock = new Object();
synchronized (lock) {
//臨界區
}
...
}那麼這種使用這種鎖有什麼好處呢?我們知道Counter對象只有一個內部鎖,這個內部鎖在同一時刻只能被一個對象持有,那麼設想Counter對象中定義了兩個synchronized方法。在某一時刻,線程A進入了其中一個synchronized方法並獲取了內部鎖,此時線程B嘗試進去另一個synchronized方法時由於對象內部鎖還沒有被線程A釋放,因此線程B只能被阻塞。然而我們的兩個synchronized方法是兩個不同的臨界區,它們不會相互影響,所以它們可以在同一時刻被不同的線程所執行。這時我們就可以使用如上面所示的顯式的鎖對象,它允許不同的方法同步在不同的鎖上。
有時候,僅僅為了同步一兩個實例域就使用synchronized關鍵字或是Lock/Condition,會造成很多不必要的開銷。這時候我們可以使用volatile關鍵字,使用volatile關鍵字修飾一個實例域會告訴編譯器和虛擬機這個域可能會被多線程並發訪問,這樣編譯器和虛擬機就能確保它的值總是我們所期望的。
volatile關鍵字的實現原理大致是這樣的:我們在訪問內存中的變量時,通常都會把它緩存在寄存器中,以後再需要讀它的值時,只需從相應寄存器中讀取,若要對該變量進行寫操作,則直接寫相應寄存器,最後寫回該變量所在的內存單元。若線程A把count變量的值緩存在寄存器中,並將count加2(將相應寄存器的值加2),這時線程B被調度,它讀取count變量加2後並寫回。然後線程A又被調度,它會接著剛才的操作,也就是會把count值寫回,此時線程A是直接把寄存器中的值寫回count所在單元,而這個值是過期的。若count被volatile關鍵字修飾,這個問題便可被圓滿解決。volatile變量有一個性質,就是任何時候讀取它的值時,都會直接去相應內存單元讀取,而不是讀取緩存在寄存器中的值。這樣一來,在上面那個場景中,線程A把count寫回時,會從內存中讀取count最新的值,從而確保了count的值總是我們所期望的。
關於volatile關鍵字更加詳細的論述請參考這裡:Java並發編程:volatile關鍵字解析 ,感謝海子同我們分享了這篇精彩博文:)
假設現在進程中只有線程A和線程B這兩個線程,考慮下面這樣一種情形:
線程A獲取了counterA對象的內部鎖,線程B獲取了counterB對象的內部鎖。而線程A只有在獲取counterB的內部鎖後才能繼續執行,線程B只有在獲取線程A的內部鎖後才能繼續執行。這樣一來,兩個線程在互相等待對方釋放鎖從而誰也沒法繼續執行,這種現象就叫做死鎖(deadlock)。
除了以上情況,還有一種類似的死鎖情況是兩個線程獲取鎖後都不滿足條件從而進入條件的等待集中,相互等待對方喚醒自己。
Java沒有為解決死鎖提供內在機制,因此我們只有在開發時格外小心,以避免死鎖的發生。關於分析定位程序中的死鎖,大家可以參考這篇文章:Java Deadlock Example and How to analyze deadlock situation
若很多線程從一個內存區域讀取數據,但其中只有極少的一部分線程會對其中的數據進行修改,此時我們希望所有Reader線程共享數據,而所有Writer線程對數據的訪問要互斥。我們可以使用讀/寫鎖來達到這一目的。
Java中的讀/寫鎖對應著ReentrantReadWriteLock類,它實現了ReadWriteLock接口,這個接口的定義如下:
public interface ReadWriteLock {
/** * Returns the lock used for reading.
* * @return the lock used for reading
*/
Lock readLock();
/** * Returns the lock used for writing.
* * @return the lock used for writing
*/
Lock writeLock();
}我們可以看到這個接口就定義了兩個方法,其中readLock方法用來獲取一個“讀鎖”,writeLock方法用來獲取一個“寫鎖”。
ReentrantReadWriteLock類的使用步驟通常如下所示:
//構造一個ReentrantReadWriteLock對象
private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
//分別從中“提取”讀鎖和寫鎖
private Lock readLock = rwl.readLock();
private Lock writeLock = rwl.writeLock();
//對所有的Reader線程加讀鎖
readLock.lock();
try {
//讀操作可並發,但寫操作會互斥
} finally {
readLock.unlock();
}
//對所有的Writer線程加寫鎖
writeLock.lock();
try {
//排斥所有其他線程的讀和寫操作
} finally {
writeLock.unlock();
}在使用ReentrantReadWriteLock類時,我們需要注意以下兩點:
以上我們所介紹的都屬於Java並發機制的底層基礎設施。在實際編程我們應該盡量避免使用以上介紹的較為底層的機制,而使用Java類庫中提供給我們封裝好的較高層次的抽象。對於許多同步問題,我們可以通過使用一個或多個隊列來解決:生產者線程向隊列中插入元素,消費者線程則取出他們。考慮一下我們最開始提到的Counter類,我們可以通過隊列來這樣解決它的同步問題:增加計數值的線程不能直接訪問Counter對象,而是把add指令對象插入到隊列中,然後由另一個可訪問Counter對象的線程從隊列中取出add指令對象並執行add操作(只有這個線程能訪問Counter對象,因此無需采取額外措施來同步)。
當試圖向滿隊列中添加元素或者向空隊列中移除元素時,阻塞隊列(blocking queue)會導致線程阻塞。通過阻塞隊列,我們可以按以下模式來工作:工作者線程可以周期性的將中間結果放入阻塞隊列中,其他線程可取出中間結果並進行進一步操作。若前者工作的比較慢(還沒來得及向隊列中插入元素),後者會等待它(試圖從空隊列中取元素從而阻塞);若前者運行的快(試圖向滿隊列中插元素),它會等待其他線程。阻塞隊列提供了以下方法:
java.util.concurrent包提供了以下幾種阻塞隊列:
下面我們來看一個使用阻塞隊列的示例:
public class BlockingQueueTest {
private int size = 20;
private ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(size);
public static void main(String[] args) {
BlockingQueueTest test = new BlockingQueueTest();
Producer producer = test.new Producer();
Consumer consumer = test.new Consumer();
producer.start();
consumer.start();
}
class Consumer extends Thread{
@Override
public void run() {
while(true){
try {
//從阻塞隊列中取出一個元素
queue.take();
System.out.println("隊列剩余" + queue.size() + "個元素");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Producer extends Thread{
@Override public void run() {
while (true) {
try {
//向阻塞隊列中插入一個元素
queue.put(1);
System.out.println("隊列剩余空間:" + (size - queue.size()));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}在以上代碼中,我們有一個生產者線程不斷地向一個阻塞隊列中插入元素,同時消費者線程從這個隊列中取出元素。若生產者生產的比較快,消費者取的比較慢導致隊列滿,此時生產者再嘗試插入時就會阻塞在put方法中,直到消費者取出一個元素;反過來,若消費者消費的比較快,生產者生產的比較慢導致隊列空,此時消費者嘗試從中取出時就會阻塞在take方法中,直到生產者插入一個元素。
創建一個新線程涉及和操作系統的交互,因此會產生一定的開銷。在有些應用場景下,我們會在程序中創建大量生命周期很短的線程,這時我們應該使用線程池(thread pool)。通常,一個線程池中包含一些准備運行的空閒線程,每次將Runnable對象交給線程池,就會有一個線程執行run方法。當run方法執行完畢時,線程不會進入Terminated狀態,而是在線程池中准備等下一個Runnable到來時提供服務。使用線程池統一管理線程可以減少並發線程的數目,線程數過多往往會在線程上下文切換上以及同步操作上浪費過多時間。
執行器類(java.util.concurrent.Executors)提供了許多靜態工廠方法來構建線程池。
在Java中,線程池通常指一個ThreadPoolExecutor對象,ThreadPoolExecutor類繼承了AbstractExecutorService類,而AbstractExecutorService抽象類實現了ExecutorService接口,ExecutorService接口又擴展了Executor接口。也就是說,Executor接口是Java中實現線程池的最基本接口。我們在使用線程池時通常不直接調用ThreadPoolExecutor類的構造方法,二回使用Executors類提供給我們的靜態工廠方法,這些靜態工廠方法內部會調用ThreadPoolExecutor的構造方法,並為我們准備好相應的構造參數。
Executors類中的以下三個方法會返回一個實現了ExecutorService接口的ThreadPoolExecutor類的對象:
//返回一個帶緩存的線程池,該池在必要的時候創建線程,在線程空閒60s後終止線程
ExecutorService newCachedThreadPool()
//返回一個線程池,線程數目由threads參數指明
ExecutorService newFixedThreadPool(int threads) ExecutorService
//返回只含一個線程的線程池,它在一個單一的線程中依次執行各個任務
ExecutorService newSingleThreadExecutor()對於newCachedThreadPool方法返回的線程池:對每個任務,若有空閒線程可用,則立即讓它執行任務;若沒有可用的空閒線程,它就會創建一個新線程並加入線程池中;
newFixedThreadPool方法返回的線程池裡的線程數目由創建時指定,並一直保持不變。若提交給它的任務多於線程池中的空閒線程數目,那麼就會把任務放到隊列中,當其他任務執行完畢後再來執行它們;
newSingleThreadExecutor會返回一個大小為1的線程池,由一個線程執行提交的任務。
以下方法可將一個Runnable對象或Callable對象提交給線程池:
Future<T> submit(Callable<T> task)
Future<T> submit(Runnable task, T result)
Future<?> submit(Runnable task)調用submit方法會返回一個Future對象,可通過這個對象查詢該任務的狀態。我們可以在這個Future對象上調用isDone、cancle、isCanceled等方法(Future接口會在下面進行介紹)。第一個submit方法提交一個Callable對象到線程池中;第二個方法提交一個Runnable對象,並且Future的get方法在完成的時候返回指定的result對象。
當我們使用完線程池時,就調用shutdown方法,該方法會啟動該線程池的關閉例程。被關閉的線程池不能再接受新的任務,當關閉前已存在的任務執行完畢後,線程池死亡。shutdownNow方法可以取消線程池中尚未開始的任務並嘗試中斷所有線程池中正在運行的線程。
在使用線程池時,我們通常應該按照以下步驟來進行:
關於線程池更加深入及詳細的分析,大家可以參考這篇博文:http://www.cnblogs.com/dolphin0520/p/3932921.html
ScheduledExecutorService接口含有為預定執行(Scheduled Execution)或重復執行的任務專門設計的方法。Executors類的newScheduledThreadPool和newSingleThreadScheduledExecutor方法會返回實現了ScheduledExecutorService接口的對象。可以使用以下方法來預定執行的任務:
//以下兩個方法預定在指定時間過後執行任務
ScheduledFuture<V> schedule(Callable<V> task, long time, TimeUnit unit)
ScheduledFuture<?> schedule(Runnable task, long time, TimeUnit unit)
//在指定的延遲(initialDelay)過後,周期性地執行給定任務
SchedukedFuture<?> scheduleAtFixedRate(Runnable task, long initialDelay, long period, TimeUnit unit)
//在指定延遲(initialDelay)過後周期性的執行任務,每兩個任務間的間隔為delay指定的時間
ScheduledFuture<?> scheduleWithFixedDelay(Runnable task, long initialDelay, long delay, TimeUnit unit)對ExecutorService對象調用invokeAny方法可以把一個Callable對象集合提交到相應的線程池中執行,並返回某個已經完成的任務的結果,該方法的定義如下:
T invokeAny(Collection<Callable<T>> tasks)
T invokeAny(Collection<Callable<T>> tasks, long timeout, TimeUnit unit)該方法可以指定一個超時參數。這個方法的不足在於我們無法知道它返回的結果是哪個任務執行的結果。如果集合中的任意Callable對象的執行結果都能滿足我們的需求的話,使用invokeAny方法是很好的。
invokeAll方法也會提交Callable對象集合到相應的線程池中,並返回一個Future對象列表,代表所有任務的解決方案。該方法的定義如下:
List<Future<T>> invokeAll(Collection<Callable<T>> tasks)
List<Future<T>> invokeAll(Collection<Callable<T>> tasks, long timeout, TimeUnit unit)我們之前提到了創建線程的兩種方式,它們有一個共同的缺點,那就是異步方法run沒有返回值,也就是說我們無法直接獲取它的執行結果,只能通過共享變量或者線程間通信等方式來獲取。好消息是通過使用Callable和Future,我們可以方便的獲得線程的執行結果。
Callable接口與Runnable接口類似,區別在於它定義的異步方法call有返回值。Callable接口的定義如下:
public interface Callable<V> {
V call() throws Exception;
}類型參數V即為異步方法call的返回值類型。
Future可以對具體的Runnable或者Callable任務的執行結果進行取消、查詢是否完成以及獲取結果。可以通過get方法獲取執行結果,該方法會阻塞直到任務返回結果。Future接口的定義如下:
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
}在Future接口中聲明了5個方法,每個方法的作用如下:
也就是說Future提供了三種功能:
Future接口的實現類是FutureTask:
public class FutureTask<V> implements RunnableFuture<V>FutureTask類實現了RunnableFuture接口,這個接口的定義如下:
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}可以看到RunnableFuture接口擴展了Runnable接口和Future接口。 FutureTask類有如下兩個構造器:
public FutureTask(Callable<V> callable)
public FutureTask(Runnable runnable, V result)FutureTask通常與線程池配合使用,通常會創建一個包裝了Callable對象的FutureTask實例,並用submit方法將它提交到一個線程池去執行,我們可以通過FutureTask的get方法獲取返回結果。
Java中的同步容器指的是線程安全的集合類,同步容器主要包含以下兩類:
通過Collections類中的相應方法把普通容器類包裝成線程安全的版本;
Vector、HashTable等系統為我們封裝好的線程安全的集合類。
相比與並發容器(下面會介紹),同步容器存在以下缺點:
關於同步容器更加詳細的介紹請參考這裡:http://www.cnblogs.com/dolphin0520/p/3933404.html
並發容器相比於同步容器,具有更強的並發訪問支持,主要體現在以下方面:
在並發容器的內部實現中盡量避免了使用synchronized關鍵字,從而增強了並發性。
Java在java.util.concurrent包中提供了主要以下並發容器類:
ConcurrentSkipSetMap用於在並發環境下替代SortedSet。
關於這些類的具體使用,大家可以參考官方文檔及相關博文。通常來說,並發容器的內部實現做到了並發讀取不用加鎖,並發寫時加鎖的粒度盡可能小。
java.util.concurrent包提供了幾個幫助我們管理相互合作的線程集的類,這些類的主要功能和適用場景如下:
//調用該方法的線程會進入阻塞狀態,直到count值為0才繼續執行
1 public void await() throws InterruptedException { };
//await方法的計時等待版本
2 public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };
//將CountDownLatch對象count值(初始化時作為參數傳入構造方法)減1
3 public void countDown() { };SynchronousQueue:允許一個線程把對象交給另一個線程。適用場景:在沒有顯式同步的情況下,當兩個線程准備好將一個對象從一個線程傳遞到另一個線程。
關於CountDownLatch、CyclicBarrier、Semaphore的具體介紹和使用示例大家可以參考這篇博文:Java並發編程:CountDownLatch、CyclicBarrier和Semaphore。
學習Java的同學注意了!!!
學習過程中遇到什麼問題或者想獲取學習資源的話,歡迎加入Java學習交流群,群號碼:279558494 我們一起學Java!