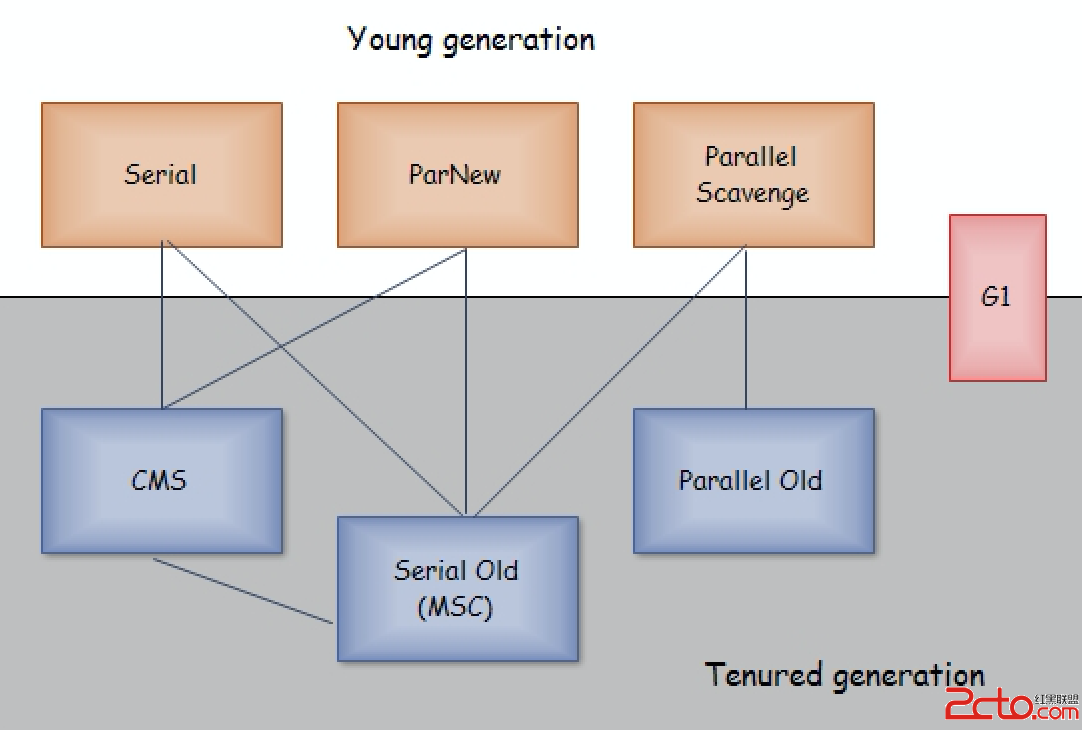
下面這些收集器在新生代中使用:
-XX:+UseSerialGC
-XX:+UseParallelGC
-XX:+UseParNewGC
下面這些收集器在老年代中使用:
-XX:+UseParallelOldGC
-XX:+UseConcMarkSweepGC
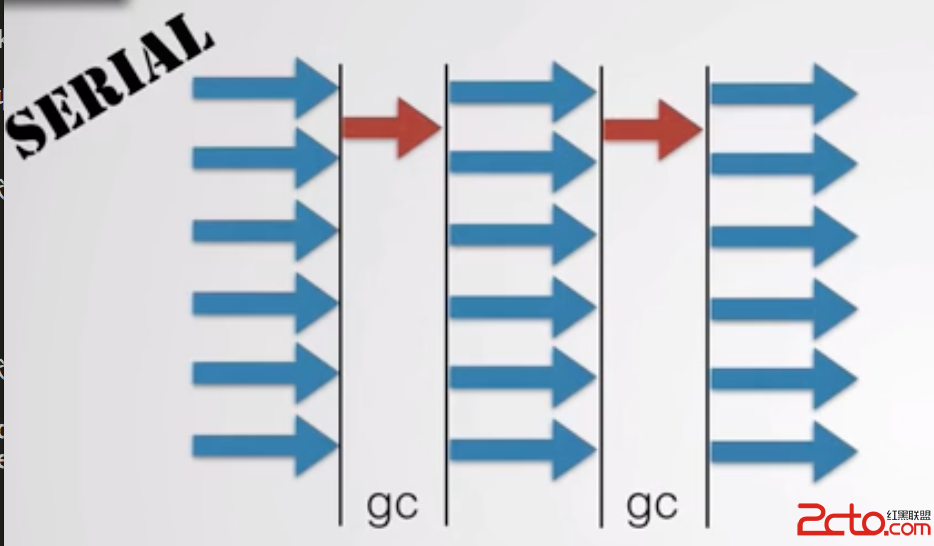
Serial收集器
1、使用在新生代,使用復制算法
2、它是一個單線程收集器,也就是它只會使用一個CPU或一個收集線程去完成垃圾收集工作。
3、它進行垃圾收集時,必須暫停其他所有工作線程,直到它收集結束
ParNew收集器
1、使用在新生代,使用復制算法
2、它就是Serial收集器的多線程版本
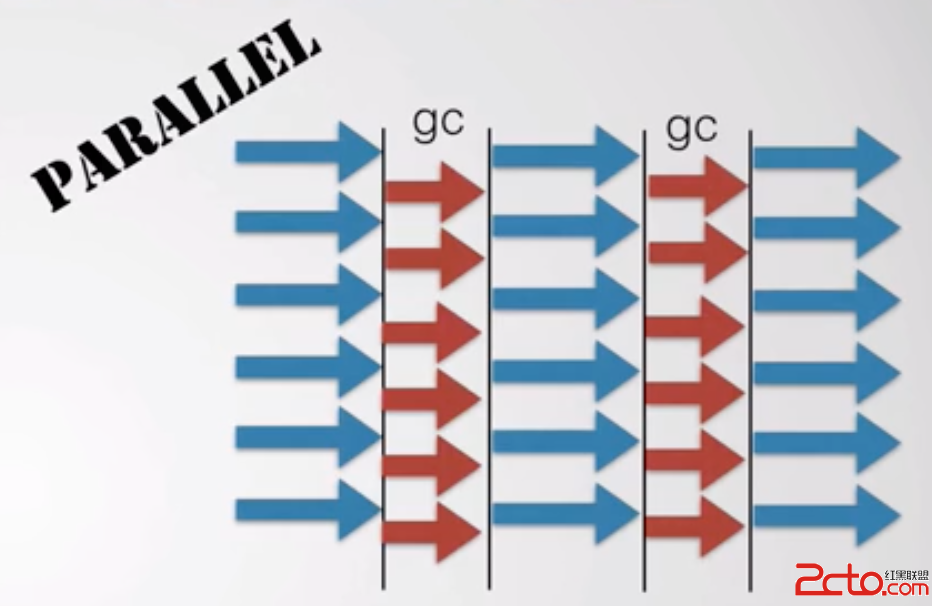
Parallel收集器
1、新生代垃圾收集器,同樣使用復制算法
2、並行多線程收集,這個跟ParNew收集器基本一致
3、特點(與ParNew收集器的不同點):其他收集器像CMS都是為了盡可能縮短垃圾收集時用戶線程的停頓時間,Parallel收集器的目標是為了達到一個可控的吞吐量,吞吐量 = 運行用戶代碼時間 / (運行用戶代碼時間 + 垃圾收集時間)
4、無法與CMS收集器配合使用
Serial Old收集器
1、使用在老年代,使用標記-整理算法
2、單線程收集器
3、它進行垃圾收集時,必須暫停其他所有工作線程,直到它收集結束
Parallel Old收集器
1、使用在老年代,使用標記-整理算法
2、並行多線程收集器
3、特點跟Parallel收集器相同
4、在注重吞吐量的場合,可以考慮使用Parallel收集器+Parallel Old收集器的組合,一個在新生代,一個在老年代。
CMS(Concurrent Mark-Sweep Collector, 並發標記-清除)收集器
1、是一種以獲取最短回收停頓時間為目標的收集器
2、使用在老年代,使用標記-清除算法
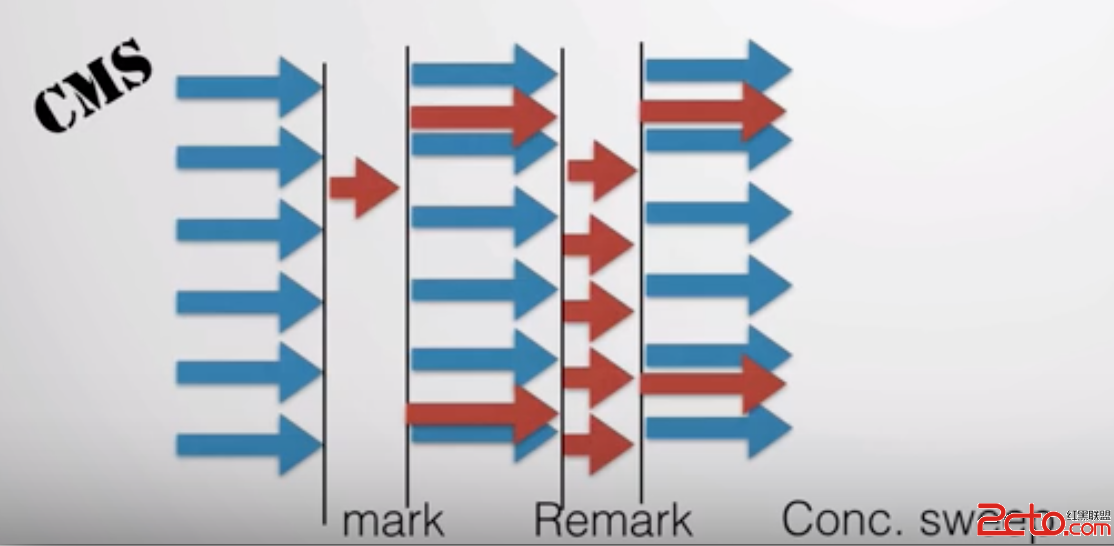
整個過程分為4個步驟:
初始標記
並發標記
重新標記
並發清除
其中,初始標記、重新標記仍然需要Stop The World,初始標記僅僅只是標記了GC Root能直接關聯的對象,速度很快,並發標記就是進行GC Roots Tracing的過程。而重新標記是為了修正並發標記期間因用戶程序繼續運作而導致標記產生變動的那一部分對象的標記記錄,這個階段的停頓時間一般比初始標記階段稍微長一些,但是遠比並發標記的時間短。由於整個過程中耗時最長的並發標記和清除標記過程都可以與用戶線程一起工作,所以總體來看,CMS收集器的內存回收過程是跟用戶線程一起並發執行的。
缺點:
1、CMS對CPU資源非常敏感,這個其實毋庸置疑,在並發操作中,雖然不會導致用戶線程停頓,但是會因為占用了一部分CPU資源而導致應用程序變慢。
2、無法處理浮動垃圾,因為CMS清理階段與用戶線程是並行的,所以在清理的過程中也會新的垃圾產生,這部分垃圾出現在標記之後,所以只能下一次GC時進行處理,這部分垃圾就是"浮動垃圾"。
3、因為CMS采用的是標記-清除算法,所以容易產生內存碎片。
Serial和Parallel收集器的區別?
它們在GC的過程中都會導致stop-the-world
serial收集器只有一個GC線程,默認使用復制算法進行收集。
parallel收集器使用多線程進行GC操作。
Parallel和CMS收集器的區別?
1、parallel使用多線程進行GC操作,但是CMS只有一個GC線程
2、parallel是一個stop-the-world收集器,CMS只有在初始標記和重新標記階段是stop-the-world,在並發標記和並發清除階段都是伴隨著用戶線程的執行。
如果希望在GC中結合並行和並發,可以使用-XX:UserParNewGC和-XX:+UseConcMarkSweepGC結合。
G1 (Garbage-First)收集器
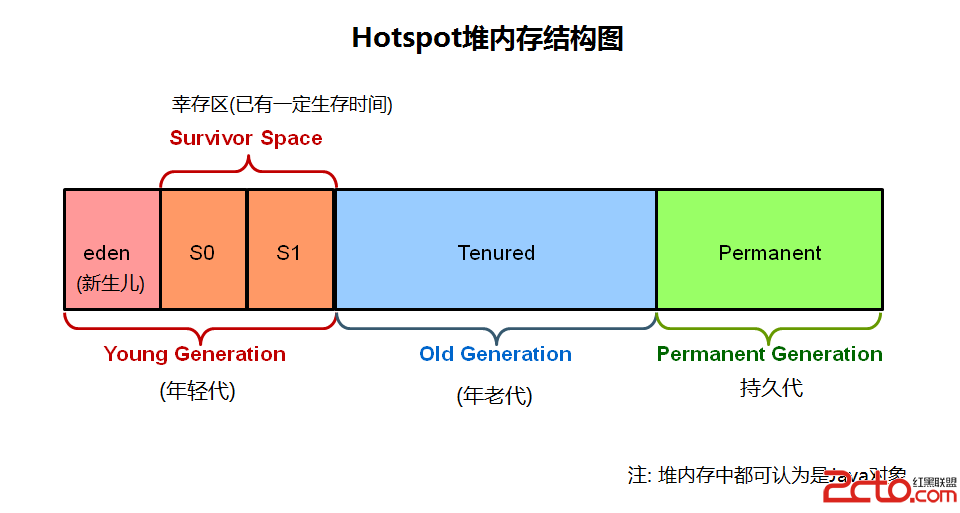
上一代的垃圾收集器(串行serial, 並行parallel, 以及CMS)都把堆內存劃分為固定大小的三個部分: 年輕代(young generation), 年老代(old generation), 以及持久代(permanent generation).
而 G1 收集器采用一種不同的方式來管理堆內存.
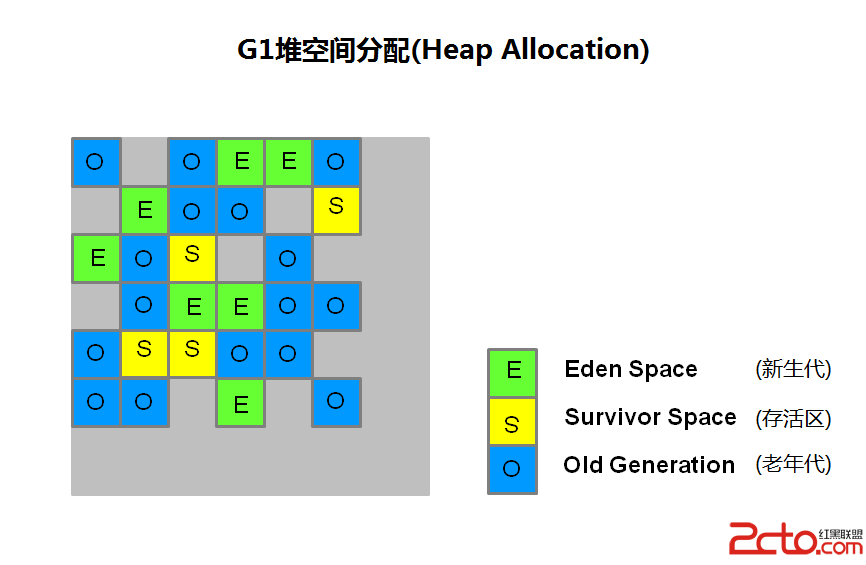
在G1中,堆被劃分成 許多個連續的區域(region)。每個區域大小相等,在1M~32M之間。JVM最多支持2000個區域,可推算G1能支持的最大內存為2000*32M=62.5G。區域(region)的大小在JVM初始化的時候決定,也可以用-XX:G1HeapReginSize設置。實際上,這些區域(regions)被映射為邏輯上的 Eden, Survivor, 和 old generation(老年代)空間.
圖中的顏色標識了每一個區域屬於哪個角色. 當進行GC時,存活的對象從一塊區域復制到另一塊區域。設計成這種區域的目的是為了並行地進行垃圾回收。
G1中每個區域都有一個與之對應的Remembered Set,它用來存放對應區域內的對象引用,能夠使區域之間並行的進行垃圾收集。
收集過程:
初始標記
並發標記
最終標記
篩選回收
跟CMS有很多相似之處,標記階段僅僅只是標記一下GC Roots能直接關聯到的對象,這個階段需要停頓線程,但是耗時較短。
並發標記階段是從GC Root開始對堆中對象進行可達性分析,找到存活的對象,這階段耗時較長,但是可與用戶程序並發執行。而最終標記則是為了修正在並發標記期間因用戶程序繼續運作而導致標記產生變動的那一部分標記記錄,這個階段需要停頓線程,可以多線程並行執行。最後篩選回收階段首先對各個區域的回收價值和回收成本進行排序,進行用戶所期待的GC停頓時間來制定回收計劃。