線程(thread)技術早在60年代就被提出,但真正應用多線程到操作系統中去,是在80年代中期,solaris是這方面的佼佼者。傳統的Unix也支持線程的概念,但是在一個進程(process)中只允許有一個線程,這樣多線程就意味著多進程。現在,多線程技術已經被許多操作系統所支持,包括Windows/NT,當然,也包括Linux。
為什麼有了進程的概念後,還要再引入線程呢?使用多線程到底有哪些好處?什麼的系統應該選用多線程?我們首先必須回答這些問題。
使用多線程的理由之一是和進程相比,它是一種非常"節儉"的多任務操作方式。我們知道,在Linux系統下,啟動一個新的進程必須分配給它獨立的地址空間,建立眾多的數據表來維護它的代碼段、堆棧段和數據段,這是一種"昂貴"的多任務工作方式。而運行於一個進程中的多個線程,它們彼此之間使用相同的地址空間,共享大部分數據,啟動一個線程所花費的空間遠遠小於啟動一個進程所花費的空間,而且,線程間彼此切換所需的時間也遠遠小於進程間切換所需要的時間。據統計,總的說來,一個進程的開銷大約是一個線程開銷的30倍左右,當然,在具體的系統上,這個數據可能會有較大的區別。
使用多線程的理由之二是線程間方便的通信機制。對不同進程來說,它們具有獨立的數據空間,要進行數據的傳遞只能通過通信的方式進行,這種方式不僅費時,而且很不方便。線程則不然,由於同一進程下的線程之間共享數據空間,所以一個線程的數據可以直接為其它線程所用,這不僅快捷,而且方便。當然,數據的共享也帶來其他一些問題,有的變量不能同時被兩個線程所修改,有的子程序中聲明為static的數據更有可能給多線程程序帶來災難性的打擊,這些正是編寫多線程程序時最需要注意的地方。
除了以上所說的優點外,不和進程比較,多線程程序作為一種多任務、並發的工作方式,當然有以下的優點:
1) 提高應用程序響應。這對圖形界面的程序尤其有意義,當一個操作耗時很長時,整個系統都會等待這個操作,此時程序不會響應鍵盤、鼠標、菜單的操作,而使用多線程技術,將耗時長的操作(time consuming)置於一個新的線程,可以避免這種尴尬的情況。
2) 使多CPU系統更加有效。操作系統會保證當線程數不大於CPU數目時,不同的線程運行於不同的CPU上。
3) 改善程序結構。一個既長又復雜的進程可以考慮分為多個線程,成為幾個獨立或半獨立的運行部分,這樣的程序會利於理解和修改。
下面我們先來嘗試編寫一個簡單的多線程程序。
Linux系統下的多線程遵循POSIX線程接口,稱為pthread。編寫Linux下的多線程程序,需要使用頭文件pthread.h,連接時需要使用庫libpthread.a。順便說一下,Linux下pthread的實現是通過系統調用clone()來實現的。clone()是Linux所特有的系統調用,它的使用方式類似fork,關於clone()的詳細情況,有興趣的讀者可以去查看有關文檔說明。下面我們展示一個最簡單的多線程程序threads.cpp。

//Threads.cpp
#include <iostream>
#include <unistd.h>
#include <pthread.h>
using namespace std;
void *thread(void *ptr)
{
for(int i = 0;i < 3;i++) {
sleep(1);
cout << "This is a pthread." << endl;
}
return 0;
}
int main() {
pthread_t id;
int ret = pthread_create(&id, NULL, thread, NULL);
if(ret) {
cout << "Create pthread error!" << endl;
return 1;
}
for(int i = 0;i < 3;i++) {
cout << "This is the main process." << endl;
sleep(1);
}
pthread_join(id, NULL);
return 0;
}
我們編譯並運行此程序,可以得到如下結果:
This is the main process.
This is a pthread.
This is the main process.
This is the main process.
This is a pthread.
This is a pthread.
再次運行,我們可能得到如下結果:
This is a pthread.
This is the main process.
This is a pthread.
This is the main process.
This is a pthread.
This is the main process.
前後兩次結果不一樣,這是兩個線程爭奪CPU資源的結果。上面的示例中,我們使用到了兩個函數,pthread_create和pthread_join,並聲明了一個pthread_t型的變量。
pthread_t在頭文件/usr/include/bits/pthreadtypes.h中定義:
typedef unsigned long int pthread_t;
它是一個線程的標識符。函數pthread_create用來創建一個線程,它的原型為:
extern int pthread_create __P ((pthread_t *__thread, __const pthread_attr_t *__attr, void *(*__start_routine) (void *), void *__arg));
第一個參數為指向線程標識符的指針,第二個參數用來設置線程屬性,第三個參數是線程運行函數的起始地址,最後一個參數是運行函數的參數。這裡,我們的函數thread不需要參數,所以最後一個參數設為空指針。第二個參數我們也設為空指針,這樣將生成默認屬性的線程。對線程屬性的設定和修改我們將在下一節闡述。當創建線程成功時,函數返回0,若不為0則說明創建線程失敗,常見的錯誤返回代碼為EAGAIN和EINVAL。前者表示系統限制創建新的線程,例如線程數目過多了;後者表示第二個參數代表的線程屬性值非法。創建線程成功後,新創建的線程則運行參數三和參數四確定的函數,原來的線程則繼續運行下一行代碼。
函數pthread_join用來等待一個線程的結束。函數原型為:
extern int pthread_join __P ((pthread_t __th, void **__thread_return));
第一個參數為被等待的線程標識符,第二個參數為一個用戶定義的指針,它可以用來存儲被等待線程的返回值。這個函數是一個線程阻塞的函數,調用它的函數將一直等待到被等待的線程結束為止,當函數返回時,被等待線程的資源被收回。一個線程的結束有兩種途徑,一種是象我們上面的例子一樣,函數結束了,調用它的線程也就結束了;另一種方式是通過函數pthread_exit來實現。它的函數原型為:
extern void pthread_exit __P ((void *__retval)) __attribute__ ((__noreturn__));
唯一的參數是函數的返回代碼,只要pthread_join中的第二個參數thread_return不是NULL,這個值將被傳遞給thread_return。最後要說明的是,一個線程不能被多個線程等待,否則第一個接收到信號的線程成功返回,其余調用pthread_join的線程則返回錯誤代碼ESRCH。
在這一節裡,我們編寫了一個最簡單的線程,並掌握了最常用的三個函數pthread_create,pthread_join和pthread_exit。下面,我們來了解線程的一些常用屬性以及如何設置這些屬性。
在上一節的例子裡,我們用pthread_create函數創建了一個線程,在這個線程中,我們使用了默認參數,即將該函數的第二個參數設為NULL。的確,對大多數程序來說,使用默認屬性就夠了,但我們還是有必要來了解一下線程的有關屬性。
屬性結構為pthread_attr_t,它同樣在頭文件/usr/include/pthread.h中定義,喜歡追根問底的人可以自己去查看。屬性值不能直接設置,須使用相關函數進行操作,初始化的函數為pthread_attr_init,這個函數必須在pthread_create函數之前調用。屬性對象主要包括是否綁定、是否分離、堆棧地址、堆棧大小、優先級。默認的屬性為非綁定、非分離、缺省1M的堆棧、與父進程同樣級別的優先級。
關於線程的綁定,牽涉到另外一個概念:輕進程(LWP:Light Weight Process)。輕進程可以理解為內核線程,它位於用戶層和系統層之間。系統對線程資源的分配、對線程的控制是通過輕進程來實現的,一個輕進程可以控制一個或多個線程。默認狀況下,啟動多少輕進程、哪些輕進程來控制哪些線程是由系統來控制的,這種狀況即稱為非綁定的。綁定狀況下,則顧名思義,即某個線程固定的"綁"在一個輕進程之上。被綁定的線程具有較高的響應速度,這是因為CPU時間片的調度是面向輕進程的,綁定的線程可以保證在需要的時候它總有一個輕進程可用。通過設置被綁定的輕進程的優先級和調度級可以使得綁定的線程滿足諸如實時反應之類的要求。
設置線程綁定狀態的函數為pthread_attr_setscope,它有兩個參數,第一個是指向屬性結構的指針,第二個是綁定類型,它有兩個取值:PTHREAD_SCOPE_SYSTEM(綁定的)和PTHREAD_SCOPE_PROCESS(非綁定的)。下面的代碼即創建了一個綁定的線程。
#include <pthread.h> pthread_attr_t attr; pthread_t tid; /*初始化屬性值,均設為默認值*/ pthread_attr_init(&attr); pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM); pthread_create(&tid, &attr, (void *) my_function, NULL);
線程的分離狀態決定一個線程以什麼樣的方式來終止自己。在上面的例子中,我們采用了線程的默認屬性,即為非分離狀態,這種情況下,原有的線程等待創建的線程結束。只有當pthread_join()函數返回時,創建的線程才算終止,才能釋放自己占用的系統資源。而分離線程不是這樣子的,它沒有被其他的線程所等待,自己運行結束了,線程也就終止了,馬上釋放系統資源。程序員應該根據自己的需要,選擇適當的分離狀態。設置線程分離狀態的函數為pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate)。第二個參數可選為PTHREAD_CREATE_DETACHED(分離線程)和 PTHREAD _CREATE_JOINABLE(非分離線程)。這裡要注意的一點是,如果設置一個線程為分離線程,而這個線程運行又非常快,它很可能在pthread_create函數返回之前就終止了,它終止以後就可能將線程號和系統資源移交給其他的線程使用,這樣調用pthread_create的線程就得到了錯誤的線程號。要避免這種情況可以采取一定的同步措施,最簡單的方法之一是可以在被創建的線程裡調用pthread_cond_timewait函數,讓這個線程等待一會兒,留出足夠的時間讓函數pthread_create返回。設置一段等待時間,是在多線程編程裡常用的方法。但是注意不要使用諸如wait()之類的函數,它們是使整個進程睡眠,並不能解決線程同步的問題。
另外一個可能常用的屬性是線程的優先級,它存放在結構sched_param中。用函數pthread_attr_getschedparam和函數pthread_attr_setschedparam進行存放,一般說來,我們總是先取優先級,對取得的值修改後再存放回去。下面即是一段簡單的例子。
#include <pthread.h> #include <sched.h> pthread_attr_t attr; pthread_t tid; sched_param param; int newprio=20; pthread_attr_init(&attr); pthread_attr_getschedparam(&attr, ¶m); param.sched_priority=newprio; pthread_attr_setschedparam(&attr, ¶m); pthread_create(&tid, &attr, (void *)myfunction, myarg);
4. 線程的數據處理
和進程相比,線程的最大優點之一是數據的共享性,各個進程共享父進程處沿襲的數據段,可以方便的獲得、修改數據。但這也給多線程編程帶來了許多問題。我們必須當心有多個不同的進程訪問相同的變量。許多函數是不可重入的,即同時不能運行一個函數的多個拷貝(除非使用不同的數據段)。在函數中聲明的靜態變量常常帶來問題,函數的返回值也會有問題。因為如果返回的是函數內部靜態聲明的空間的地址,則在一個線程調用該函數得到地址後使用該地址指向的數據時,別的線程可能調用此函數並修改了這一段數據。在進程中共享的變量必須用關鍵字volatile來定義,這是為了防止編譯器在優化時(如gcc中使用-OX參數)改變它們的使用方式。為了保護變量,我們必須使用信號量、互斥等方法來保證我們對變量的正確使用。下面,我們就逐步介紹處理線程數據時的有關知識。
4.1 線程數據
在單線程的程序裡,有兩種基本的數據:全局變量和局部變量。但在多線程程序裡,還有第三種數據類型:線程數據(TSD: Thread-Specific Data)。它和全局變量很象,在線程內部,各個函數可以象使用全局變量一樣調用它,但它對線程外部的其它線程是不可見的。這種數據的必要性是顯而易見的。例如我們常見的變量errno,它返回標准的出錯信息。它顯然不能是一個局部變量,幾乎每個函數都應該可以調用它;但它又不能是一個全局變量,否則在A線程裡輸出的很可能是B線程的出錯信息。要實現諸如此類的變量,我們就必須使用線程數據。我們為每個線程數據創建一個鍵,它和這個鍵相關聯,在各個線程裡,都使用這個鍵來指代線程數據,但在不同的線程裡,這個鍵代表的數據是不同的,在同一個線程裡,它代表同樣的數據內容。
和線程數據相關的函數主要有4個:創建一個鍵;為一個鍵指定線程數據;從一個鍵讀取線程數據;刪除鍵。
創建鍵的函數原型為:
extern int pthread_key_create __P ((pthread_key_t *__key,void (*__destr_function) (void *)));
第一個參數為指向一個鍵值的指針,第二個參數指明了一個destructor函數,如果這個參數不為空,那麼當每個線程結束時,系統將調用這個函數來釋放綁定在這個鍵上的內存塊。這個函數常和函數pthread_once ((pthread_once_t*once_control, void (*initroutine) (void)))一起使用,為了讓這個鍵只被創建一次。函數pthread_once聲明一個初始化函數,第一次調用pthread_once時它執行這個函數,以後的調用將被它忽略。
在下面的例子中,我們創建一個鍵,並將它和某個數據相關聯。我們要定義一個函數createWindow,這個函數定義一個圖形窗口(數據類型為Fl_Window *,這是圖形界面開發工具FLTK中的數據類型)。由於各個線程都會調用這個函數,所以我們使用線程數據。
/* 聲明一個鍵*/
pthread_key_t myWinKey;
/* 函數 createWindow */
void createWindow ( void ) {
Fl_Window * win;
static pthread_once_t once= PTHREAD_ONCE_INIT;
/* 調用函數createMyKey,創建鍵*/
pthread_once ( & once, createMyKey) ;
/*win指向一個新建立的窗口*/
win=new Fl_Window( 0, 0, 100, 100, "MyWindow");
/* 對此窗口作一些可能的設置工作,如大小、位置、名稱等*/
setWindow(win);
/* 將窗口指針值綁定在鍵myWinKey上*/
pthread_setpecific ( myWinKey, win);
}
/* 函數 createMyKey,創建一個鍵,並指定了destructor */
void createMyKey ( void ) {
pthread_keycreate(&myWinKey, freeWinKey);
}
/* 函數 freeWinKey,釋放空間*/
void freeWinKey ( Fl_Window * win){
delete win;
}
這樣,在不同的線程中調用函數createMyWin,都可以得到在線程內部均可見的窗口變量,這個變量通過函數pthread_getspecific得到。在上面的例子中,我們已經使用了函數pthread_setspecific來將線程數據和一個鍵綁定在一起。這兩個函數的原型如下:
extern int pthread_setspecific __P ((pthread_key_t __key,__const void *__pointer)); extern void *pthread_getspecific __P ((pthread_key_t __key));
這兩個函數的參數意義和使用方法是顯而易見的。要注意的是,用pthread_setspecific為一個鍵指定新的線程數據時,必須自己釋放原有的線程數據以回收空間。這個過程函數pthread_key_delete用來刪除一個鍵,這個鍵占用的內存將被釋放,但同樣要注意的是,它只釋放鍵占用的內存,並不釋放該鍵關聯的線程數據所占用的內存資源,而且它也不會觸發函數pthread_key_create中定義的destructor函數。線程數據的釋放必須在釋放鍵之前完成。
4.2 互斥鎖
互斥鎖用來保證一段時間內只有一個線程在執行一段代碼。必要性顯而易見:假設各個線程向同一個文件順序寫入數據,最後得到的結果一定是災難性的。
我們先看下面一段代碼。這是一個讀/寫程序,它們公用一個緩沖區,並且我們假定一個緩沖區只能保存一條信息。即緩沖區只有兩個狀態:有信息或沒有信息。
void reader_function ( void );
void writer_function ( void );
char buffer;
int buffer_has_item=0;
pthread_mutex_t mutex;
struct timespec delay;
void main ( void ){
pthread_t reader;
/* 定義延遲時間*/
delay.tv_sec = 2;
delay.tv_nec = 0;
/* 用默認屬性初始化一個互斥鎖對象*/
pthread_mutex_init (&mutex,NULL);
pthread_create(&reader, pthread_attr_default, (void *)&reader_function), NULL);
writer_function( );
}
void writer_function (void){
while(1){
/* 鎖定互斥鎖*/
pthread_mutex_lock (&mutex);
if (buffer_has_item==0){
buffer=make_new_item( );
buffer_has_item=1;
}
/* 打開互斥鎖*/
pthread_mutex_unlock(&mutex);
pthread_delay_np(&delay);
}
}
void reader_function(void){
while(1){
pthread_mutex_lock(&mutex);
if(buffer_has_item==1){
consume_item(buffer);
buffer_has_item=0;
}
pthread_mutex_unlock(&mutex);
pthread_delay_np(&delay);
}
}
這裡聲明了互斥鎖變量mutex,結構pthread_mutex_t為不公開的數據類型,其中包含一個系統分配的屬性對象。函數pthread_mutex_init用來生成一個互斥鎖。NULL參數表明使用默認屬性。如果需要聲明特定屬性的互斥鎖,須調用函數pthread_mutexattr_init。函數pthread_mutexattr_setpshared和函數pthread_mutexattr_settype用來設置互斥鎖屬性。前一個函數設置屬性pshared,它有兩個取值,PTHREAD_PROCESS_PRIVATE和PTHREAD_PROCESS_SHARED。前者用來不同進程中的線程同步,後者用於同步本進程的不同線程。在上面的例子中,我們使用的是默認屬性PTHREAD_PROCESS_ PRIVATE。後者用來設置互斥鎖類型,可選的類型有PTHREAD_MUTEX_NORMAL、PTHREAD_MUTEX_ERRORCHECK、PTHREAD_MUTEX_RECURSIVE和PTHREAD _MUTEX_DEFAULT。它們分別定義了不同的上鎖、解鎖機制,一般情況下,選用最後一個默認屬性。
pthread_mutex_lock聲明開始用互斥鎖上鎖,此後的代碼直至調用pthread_mutex_unlock為止,均被上鎖,即同一時間只能被一個線程調用執行。當一個線程執行到pthread_mutex_lock處時,如果該鎖此時被另一個線程使用,那此線程被阻塞,即程序將等待到另一個線程釋放此互斥鎖。在上面的例子中,我們使用了pthread_delay_np函數,讓線程睡眠一段時間,就是為了防止一個線程始終占據此函數。
上面的例子非常簡單,就不再介紹了,需要提出的是在使用互斥鎖的過程中很有可能會出現死鎖:兩個線程試圖同時占用兩個資源,並按不同的次序鎖定相應的互斥鎖,例如兩個線程都需要鎖定互斥鎖1和互斥鎖2,a線程先鎖定互斥鎖1,b線程先鎖定互斥鎖2,這時就出現了死鎖。此時我們可以使用函數pthread_mutex_trylock,它是函數pthread_mutex_lock的非阻塞版本,當它發現死鎖不可避免時,它會返回相應的信息,程序員可以針對死鎖做出相應的處理。另外不同的互斥鎖類型對死鎖的處理不一樣,但最主要的還是要程序員自己在程序設計注意這一點。
4.3 條件變量
前一節中我們講述了如何使用互斥鎖來實現線程間數據的共享和通信,互斥鎖一個明顯的缺點是它只有兩種狀態:鎖定和非鎖定。而條件變量通過允許線程阻塞和等待另一個線程發送信號的方法彌補了互斥鎖的不足,它常和互斥鎖一起使用。使用時,條件變量被用來阻塞一個線程,當條件不滿足時,線程往往解開相應的互斥鎖並等待條件發生變化。一旦其它的某個線程改變了條件變量,它將通知相應的條件變量喚醒一個或多個正被此條件變量阻塞的線程。這些線程將重新鎖定互斥鎖並重新測試條件是否滿足。一般說來,條件變量被用來進行線承間的同步。
條件變量的結構為pthread_cond_t,函數pthread_cond_init()被用來初始化一個條件變量。它的原型為:
extern int pthread_cond_init __P ((pthread_cond_t *__cond,__const pthread_condattr_t *__cond_attr));
其中cond是一個指向結構pthread_cond_t的指針,cond_attr是一個指向結構pthread_condattr_t的指針。結構pthread_condattr_t是條件變量的屬性結構,和互斥鎖一樣我們可以用它來設置條件變量是進程內可用還是進程間可用,默認值是PTHREAD_ PROCESS_PRIVATE,即此條件變量被同一進程內的各個線程使用。注意初始化條件變量只有未被使用時才能重新初始化或被釋放。釋放一個條件變量的函數為pthread_cond_ destroy(pthread_cond_t cond)。
函數pthread_cond_wait()使線程阻塞在一個條件變量上。
它的函數原型為:
extern int pthread_cond_wait __P ((pthread_cond_t *__cond, pthread_mutex_t *__mutex));
線程解開mutex指向的鎖並被條件變量cond阻塞。線程可以被函數pthread_cond_signal和函數pthread_cond_broadcast喚醒,但是要注意的是,條件變量只是起阻塞和喚醒線程的作用,具體的判斷條件還需用戶給出,例如一個變量是否為0等等,這一點我們從後面的例子中可以看到。線程被喚醒後,它將重新檢查判斷條件是否滿足,如果還不滿足,一般說來線程應該仍阻塞在這裡,被等待被下一次喚醒。這個過程一般用while語句實現。
另一個用來阻塞線程的函數是pthread_cond_timedwait(),它的原型為:
extern int pthread_cond_timedwait __P ((pthread_cond_t *__cond, pthread_mutex_t *__mutex, __const struct timespec *__abstime));
它比函數pthread_cond_wait()多了一個時間參數,經歷abstime段時間後,即使條件變量不滿足,阻塞也被解除。
函數pthread_cond_signal()的原型為:
extern int pthread_cond_signal __P ((pthread_cond_t *__cond));
它用來釋放被阻塞在條件變量cond上的一個線程。多個線程阻塞在此條件變量上時,哪一個線程被喚醒是由線程的調度策略所決定的。要注意的是,必須用保護條件變量的互斥鎖來保護這個函數,否則條件滿足信號又可能在測試條件和調用pthread_cond_wait函數之間被發出,從而造成無限制的等待。下面是使用函數pthread_cond_wait()和函數
pthread_cond_signal()的一個簡單的例子。
pthread_mutex_t count_lock;
pthread_cond_t count_nonzero;
unsigned count;
decrement_count () {
pthread_mutex_lock (&count_lock);
while(count==0)
pthread_cond_wait( &count_nonzero, &count_lock);
count=count -1;
pthread_mutex_unlock (&count_lock);
}
increment_count(){
pthread_mutex_lock(&count_lock);
if(count==0)
pthread_cond_signal(&count_nonzero);
count=count+1;
pthread_mutex_unlock(&count_lock);
}
count值為0時,decrement函數在pthread_cond_wait處被阻塞,並打開互斥鎖count_lock。此時,當調用到函數increment_count時,pthread_cond_signal()函數改變條件變量,告知decrement_count()停止阻塞。讀者可以試著讓兩個線程分別運行這兩個函數,看看會出現什麼樣的結果。
函數pthread_cond_broadcast(pthread_cond_t *cond)用來喚醒所有被阻塞在條件變量cond上的線程。這些線程被喚醒後將再次競爭相應的互斥鎖,所以必須小心使用這個函數。
4.4 信號量
信號量本質上是一個非負的整數計數器,它被用來控制對公共資源的訪問。當公共資源增加時,調用函數sem_post()增加信號量。只有當信號量值大於0時,才能使用公共資源,使用後,函數sem_wait()減少信號量。函數sem_trywait()和函數pthread_ mutex_trylock()起同樣的作用,它是函數sem_wait()的非阻塞版本。下面我們逐個介紹和信號量有關的一些函數,它們都在頭文件/usr/include/semaphore.h中定義。
信號量的數據類型為結構sem_t,它本質上是一個長整型的數。函數sem_init()用來初始化一個信號量。它的原型為:
extern int sem_init __P ((sem_t *__sem, int __pshared, unsigned int __value));
sem為指向信號量結構的一個指針;pshared不為0時此信號量在進程間共享,否則只能為當前進程的所有線程共享;value給出了信號量的初始值。
函數sem_post( sem_t *sem )用來增加信號量的值。當有線程阻塞在這個信號量上時,調用這個函數會使其中的一個線程不在阻塞,選擇機制同樣是由線程的調度策略決定的。
函數sem_wait( sem_t *sem )被用來阻塞當前線程直到信號量sem的值大於0,解除阻塞後將sem的值減一,表明公共資源經使用後減少。函數sem_trywait ( sem_t *sem )是函數sem_wait()的非阻塞版本,它直接將信號量sem的值減一。
函數sem_destroy(sem_t *sem)用來釋放信號量sem。
下面我們來看一個使用信號量的例子。在這個例子中,一共有4個線程,其中兩個線程負責從文件讀取數據到公共的緩沖區,另兩個線程從緩沖區讀取數據作不同的處理(加和乘運算)。
/* File sem.c */
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#define MAXSTACK 100
int stack[MAXSTACK][2];
int size=0;
sem_t sem;
/* 從文件1.dat讀取數據,每讀一次,信號量加一*/
void ReadData1(void){
FILE *fp=fopen("1.dat","r");
while(!feof(fp)){
fscanf(fp,"%d %d",&stack[size][0],&stack[size][1]);
sem_post(&sem);
++size;
}
fclose(fp);
}
/*從文件2.dat讀取數據*/
void ReadData2(void){
FILE *fp=fopen("2.dat","r");
while(!feof(fp)){
fscanf(fp,"%d %d",&stack[size][0],&stack[size][1]);
sem_post(&sem);
++size;
}
fclose(fp);
}
/*阻塞等待緩沖區有數據,讀取數據後,釋放空間,繼續等待*/
void HandleData1(void){
while(1){
sem_wait(&sem);
printf("Plus:%d+%d=%d\n",stack[size][0],stack[size][1],
stack[size][0]+stack[size][1]);
--size;
}
}
void HandleData2(void){
while(1){
sem_wait(&sem);
printf("Multiply:%d*%d=%d\n",stack[size][0],stack[size][1],
stack[size][0]*stack[size][1]);
--size;
}
}
int main(void){
pthread_t t1,t2,t3,t4;
sem_init(&sem,0,0);
pthread_create(&t1,NULL,(void *)HandleData1,NULL);
pthread_create(&t2,NULL,(void *)HandleData2,NULL);
pthread_create(&t3,NULL,(void *)ReadData1,NULL);
pthread_create(&t4,NULL,(void *)ReadData2,NULL);
/* 防止程序過早退出,讓它在此無限期等待*/
pthread_join(t1,NULL);
}
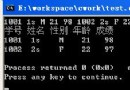
在Linux下,我們用命令gcc -lpthread sem.c -o sem生成可執行文件sem。 我們事先編輯好數據文件1.dat和2.dat,假設它們的內容分別為1 2 3 4 5 6 7 8 9 10和 -1 -2 -3 -4 -5 -6 -7 -8 -9 -10 ,我們運行sem,得到如下的結果:
Multiply:-1*-2=2
Plus:-1+-2=-3
Multiply:9*10=90
Plus:-9+-10=-19
Multiply:-7*-8=56
Plus:-5+-6=-11
Multiply:-3*-4=12
Plus:9+10=19
Plus:7+8=15
Plus:5+6=11
從中我們可以看出各個線程間的競爭關系。而數值並未按我們原先的順序顯示出來這是由於size這個數值被各個線程任意修改的緣故。這也往往是多線程編程要注意的問題。
5. 小結
多線程編程是一個很有意思也很有用的技術,使用多線程技術的網絡螞蟻是目前最常用的下載工具之一,使用多線程技術的grep比單線程的grep要快上幾倍,類似的例子還有很多。希望大家能用多線程技術寫出高效實用的好程序來。