在之前的博文中,我們已經隊大部分層結構類都進行了分析,在這篇博文中我們准備針對最後兩個,也是處於層結構類繼承體系中最底層的兩個基類layer_base和layer做一下簡要分析。由於layer類只是對layer_base的一個簡單實例化,因此這裡著重分析layer_base類。
首先,給出layer_base類的基本結構框圖:
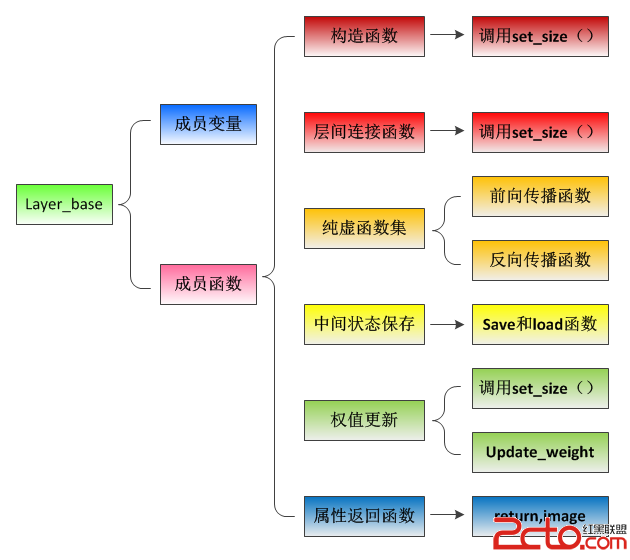
一、成員變量
由於layer_base是這個類體系結構的基類,是構建網絡層的基石,因此其內部封裝了網絡層的基本屬性,相應的也有大量對應的成員變量:
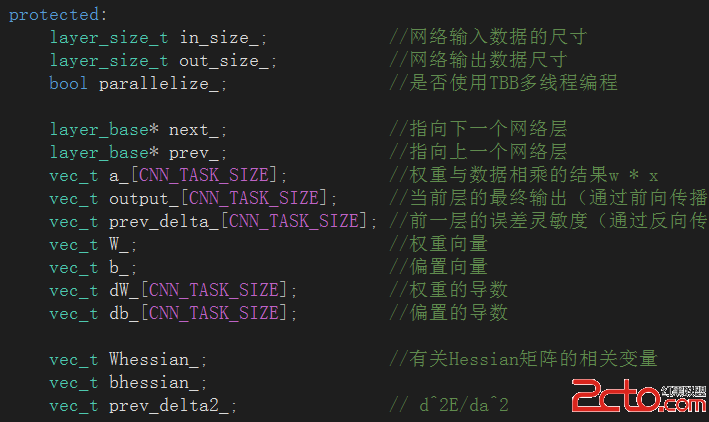
接下來一一對這些成員變量的基本含義做一下大致介紹:
(1)in_size_、out_size_:保存了當前層的輸入數據尺寸和輸出數據尺寸。
(2)parallelize_:布爾類型標志位,用以標記當前工程是否使用TBB多線程加速。
(3)next_、prev_:兩個指向layer_base類型的指針,用以指向當前層的下一層以及當前層的上一層,是維持層間聯系的關鍵紐帶。
(4)a_:保留當前層卷積運算的中間結果。
(5)output_:經過激活函數處理之後的當前層的最終特征輸出。
(6)prev_delta_:有前一層傳播過來的誤差靈敏度(梯度下降法過程中使用)。
(7)W_、b_:當前層的卷積核權重以及偏置。
(8)dW_、db_:權重的導數和偏置的導數,用以對權重和偏置進行更新。
(9)Whessian_、bhessian_:海森矩陣的相關變量,具體含義在後續博文中會詳細解釋。
(10)prev_delta2_:誤差相對於輸入的二階導數,主要用於全連接層中的誤差計算。
二、構造函數
構造函數的功能十分簡單,通過調用set_size()成員函數來完成網絡層中各個相關變量的初始化:
layer_base(layer_size_t in_dim, layer_size_t out_dim, size_t weight_dim, size_t bias_dim) : parallelize_(true), next_(nullptr), prev_(nullptr)
{
set_size(in_dim, out_dim, weight_dim, bias_dim);//初始化神經網絡層的參數
}
需要注意的一點是這裡默認將parallelize_標志位初始化為true,即默認使用TBB加速。至於set_size()函數,主要是通過調用vector的成員函數resize()來對各個參數進行初始化。
三、權重初始化
權重初始化主要通過set_size()函數完成(注意,這個函數不僅僅在構造函數中有所調用),正如上文所說,這個函數本質上就是在調用resize():
void set_size(layer_size_t in_dim, layer_size_t out_dim, size_t weight_dim, size_t bias_dim) {
in_size_ = in_dim;
out_size_ = out_dim;
W_.resize(weight_dim);
b_.resize(bias_dim);
Whessian_.resize(weight_dim);
bhessian_.resize(bias_dim);
prev_delta2_.resize(in_dim);
for (auto& o : output_) o.resize(out_dim);
for (auto& a : a_) a.resize(out_dim);
for (auto& p : prev_delta_) p.resize(in_dim);
for (auto& dw : dW_) dw.resize(weight_dim);
for (auto& db : db_) db.resize(bias_dim);
}
需要注意的一點就是這裡使用了范圍for循環來完成這個vector容器中元素的遍歷和操作,這算是C++11的一個特點,需要慢慢體會,不過單純的從遍歷的角度講,這的確比傳統的for循環更為方便而安全。
四、純虛函數集
由於layer_base是一個公共基類,有必要定義一些虛函數以及純虛函數供派生出來的不同類型的子類進行改寫。這裡作者選擇將與激活函數和前向/反向傳播算法定義成純虛函數,原因很明確:不同層的前向/反向傳播算法是不同的,並且激活函數也是可有可無:
/**********將激活函數、前向傳播和反向傳播全部聲明為純虛函數,在子類中進行定義**********/
virtual activation::function& activation_function() = 0;
virtual const vec_t& forward_propagation(const vec_t& in, size_t worker_index) = 0;
virtual const vec_t& back_propagation(const vec_t& current_delta, size_t worker_index) = 0;
virtual const vec_t& back_propagation_2nd(const vec_t& current_delta2) = 0;
五、中間狀態保存
由於卷積神經網絡的訓練時間都較長,因此有必要定義保存中間訓練結果的接口以完成斷點續傳(這個用詞可能不太恰當),因此在layer_base中提供了用以保存和加載網絡中間訓練狀態的結構函數save和load:
/**********保存網絡層中的權重和偏置(中間訓練結果)**********/
virtual void save(std::ostream& os) const {
if (is_exploded()) throw nn_error("failed to save weights because of infinite weight");
for (auto w : W_) os << w << " ";
for (auto b : b_) os << b << " ";
}
/**********加載中間訓練值**********/
virtual void load(std::istream& is) {
for (auto& w : W_) is >> w;
for (auto& b : b_) is >> b;
}
這裡主要通過流操作來完成結果的輸入輸出操作,同樣體現出了強力的C++特性。
六、權值更新
layer_base對權值更新的操作主要有兩個,一是權值和偏置的參數的初始化操作set_size(),這個前文已經介紹過了;二是更新函數update_weight()。update_weight()函數主要是通過調用各個收斂算法(如這裡默認使用的gradient_descent_levenberg_marquardt算法)中的update()函數來完成對應權值和偏置的更新操作:
至於update函數的具體實現細節則取決於所使用的收斂算法,有關這部分內容我會在之後介紹收斂算法(Optimizer結構體)的博文中專門進行詳細的介紹。不過從表面的調用形式上可以看出,在BP算法對權值進行更新的過程中,需要用到dW(一階導數)和海森矩陣(二階導數)。
七、屬性返回參數
這部分結構函數幾乎是各個網絡層的必備函數,方便用戶查看對應網絡層的具體參數信息和特征輸出結果,一般都包含兩個方面,return語句和output_to_image類型的視覺轉換函數。return語句負責返回網絡層的相關成員變量(可以在內部進行一些簡單運算),output_to_image()函數則負責將映射核、特征輸出結果轉換成圖像的形式供我們觀賞,這些在之前的博文中都有提到過,這裡不再贅述。
八、layer類結構分析
相對於layer_base類,layer的結構功能則簡單了很多,大體上可以分為三類。激活函數實例化,保存/加載函數具體化,定義錯誤提示信息。
8.1 激活函數實例化
由於在layer_base類中將激活函數定義為純虛函數,作者選擇在子類layer中對其進行實例化:

這裡涉及到了Activation類的使用,在這個類中封裝了各種各樣類型的激活函數,在後續的博文中會專門拿出一兩篇的篇幅來對這個類進行分析。
8.2 保存、加載中間訓練值函數具體化
這裡沒什麼可細說的,通過流操作basic_ostream來進行輸入輸出:
/**********輔助的保存、加載操作**********/
template
std::basic_ostream& operator << (std::basic_ostream& os, const layer_base& v) {
v.save(os);
return os;
}
template
std::basic_istream& operator >> (std::basic_istream& os, layer_base& v) {
v.load(os);
return os;
}
8.3 錯誤提示函數定義
在layer中定義了三種錯誤類型的信息提示函數:連接不匹配、輸入特征維數不匹配、下采樣維數不匹配:
(1)連接不匹配信息提示函數connection_mismatch。這個函數主要是在程序發現當前一層的特征輸出維數與後一層的特征輸入維數不同時調用,格式化輸出錯誤信息,指明出現問題的具體層。
(2)輸入特征維數不匹配信息提示函數data_mismatch:這個函數主要是在程序發現輸入數據的維數與當前層的輸入維數不匹配時調用,格式化輸出錯誤信息,指明出現問題的具體層。
(3)下采樣維數不匹配信息提示函數pooling_size_mismatch:這個函數主要是在程序發現當前特征維數不能被下采樣窗口尺寸整除時調用,格式化輸出錯誤信息,指明出現問題的具體層。
需要注意的一點是,以上三個函數只負責格式化輸出錯誤信息提示,具體錯誤檢查機制需要在對應的可能的調用環境中中自行編寫進行判斷。
九、注意事項
1、范圍for循環
在tiny_cnn工程中對容器進行遍歷時,全部采用了范圍for循環,這點對於之前一直使用傳統for循環的童鞋來說剛開始可能有點難以接受,但畢竟范圍for循環既安全又簡答,以後也要多多使用。
2、layer_base的函數並沒有介紹完全
上文中對layer_base類中的成員函數並沒有百分之百的介紹完全,對於一些小的補丁試的成員函數在後續用到時再進行解釋。
3、激活函數不等於收斂算法
這裡強調一個初學者容易混淆的概念,就是激活函數和收斂算法。首先這兩者是完全不同的,舉個栗子通俗的說明一下:激活函數包含sigmoid,tanh,Relu;收斂算法則主要指梯度下降法,怎麼樣,是不是茅塞頓開了。