之前的博文中已經將卷積層、下采樣層進行了分析,在這篇博文中我們對最後一個頂層層結構fully_connected_layer類(全連接層)進行分析:
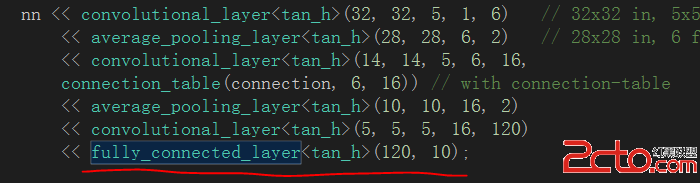
一、卷積神經網路中的全連接層
在卷積神經網絡中全連接層位於網絡模型的最後部分,負責對網絡最終輸出的特征進行分類預測,得出分類結果:
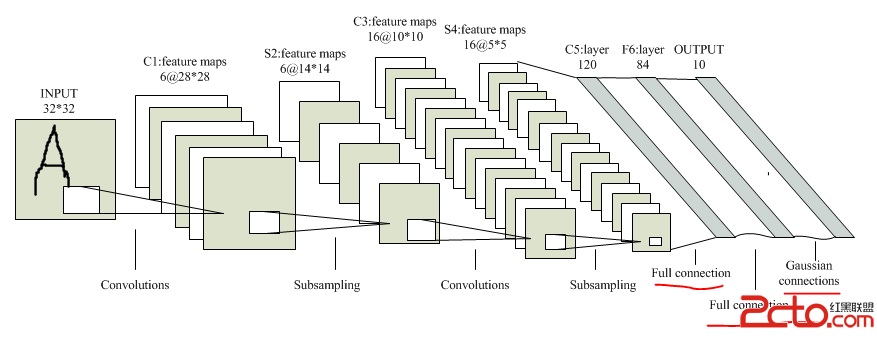
LeNet-5模型中的全連接層分為全連接和高斯連接,該層的最終輸出結果即為預測標簽,例如這裡我們需要對MNIST數據庫中的數據進行分類預測,其中的數據一共有10類(數字0~9),因此全全連接層的最終輸出就是一個10維的預測結果向量,哪一維的值為非零,則預測結果對應的就是幾。
二、fully_connected_layer類結構
與之前卷積層和下采樣層不同的是,這裡的全連接層fully_connected_layer類繼承自基類layer,其中類成員一共可分為四大部分:成員變量、構造函數、前向傳播函數、反向傳播函數。
2.1 成員變量
fully_connected_layer類的成員變量只有一個,就是一個Filter類型的變量:
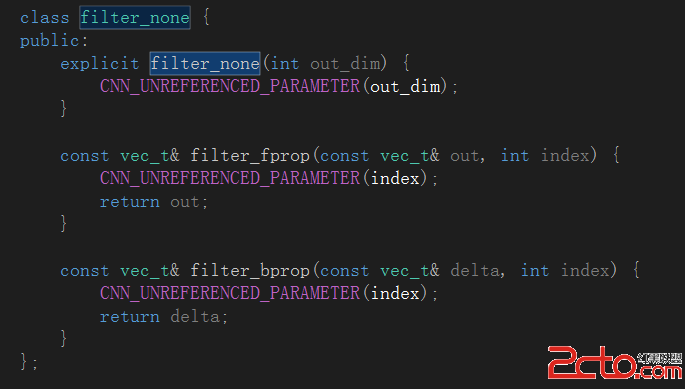
而這裡的Filter是通過類模板參數傳入的一個缺省filter_none類型,具體如下:

至於filter_none類型,從名稱判斷應該是一個和濾波器核相關的類封裝,具體定義在dropout.h文件中:
有關dropout.h文件中封裝的相關類的詳細信息我會在之後的博文中進行詳細的介紹,這裡先留一個坑,不過事先透漏一點,卷積神經網絡中的dropout本質上是為了改善網絡過擬合性能而設計的。
2.2 構造函數
構造函數極其簡單,單純的調用了基類layer的構造函數:

至於基類layer,裡面封裝了大量的虛函數以及純虛函數,並給出了網絡層基本的框架設定,對layer_base類進行了一部分實例化,這幾點我們以後會詳細說的。
2.3 前向傳播函數
眾所周知,卷積神經網絡在訓練時和BP神經網絡的訓練極其相似,包括一個樣本預測的前向傳播過程和誤差的反向傳播過程。首先前向傳播函數的代碼如下:
const vec_t& forward_propagation(const vec_t& in, size_t index) {
vec_t &a = a_[index];
vec_t &out = output_[index];
for_i(parallelize_, out_size_, [&](int i) {
a[i] = 0.0;
for (int c = 0; c < in_size_; c++)
a[i] += W_[c*out_size_ + i] * in[c];
a[i] += b_[i];
});
for_i(parallelize_, out_size_, [&](int i) {
out[i] = h_.f(a, i);
});
auto& this_out = filter_.filter_fprop(out, index);
return next_ ? next_->forward_propagation(this_out, index) : this_out;
}
從代碼中可以看出這個前向傳播函數本質上屬於一個遞歸函數,用遞歸的方式實現層層傳播的功能:

在前向傳播的過程中,主要有兩個階段,一是通過當前層的卷積核和偏置完成對輸入數據的映射:
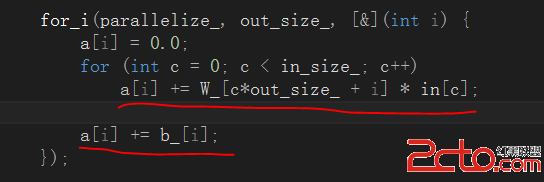
從代碼中可見,卷積層的映射過程本質上就是一個卷積操作,然後在對卷積結果累加偏置。第二個階段就是將卷積層的映射結果送入激活函數中進行處理:

激活函數的主要作用是對卷積層的映射輸出進行規范化,調整期數據分布。經典的激活函數是Sigmoid函數,主要對輸出特征進行平滑。在之後學者又提出Relu類型的激活函數,主要是對輸出特征進行稀疏化規范,使其更接近於人腦的視覺映射機理。在tiny_cnn中作者封裝了sigmoid、relu、leaky_relu、softmax、tan_h、tan_hp1m2等激活函數,這些類都定義在activation命名空間中,具體在activation_function.h文件中,在後續的篇幅中我會專門拿出一篇博文的篇幅對tiny_cnn的激活函數做集中的分析。
2.4 反向傳播函數
反向傳播算法是BP類型神經網絡的經典特征,大部分都采用隨機梯度下降法對誤差進行求導和傳播。由於反向傳播算法涉及到誤差的求偏導、靈敏度傳遞等概念,導致其在原理上相對於前向傳播過程顯得更為復雜,代碼實現也較為繁瑣,我們這裡只是先給出反向傳播的代碼,在後續的博文中在針對這個傳播過程進行更文詳細的分析,OK,又是一個坑:
const vec_t& back_propagation(const vec_t& current_delta, size_t index) {
const vec_t& curr_delta = filter_.filter_bprop(current_delta, index);
const vec_t& prev_out = prev_->output(index);
const activation::function& prev_h = prev_->activation_function();
vec_t& prev_delta = prev_delta_[index];
vec_t& dW = dW_[index];
vec_t& db = db_[index];
for (int c = 0; c < this->in_size_; c++) {
// propagate delta to previous layer
// prev_delta[c] += current_delta[r] * W_[c * out_size_ + r]
prev_delta[c] = vectorize::dot(&curr_delta[0], &W_[c*out_size_], out_size_);
prev_delta[c] *= prev_h.df(prev_out[c]);
}
for_(parallelize_, 0, out_size_, [&](const blocked_range& r) {
// accumulate weight-step using delta
// dW[c * out_size + i] += current_delta[i] * prev_out[c]
for (int c = 0; c < in_size_; c++)
vectorize::muladd(&curr_delta[0], prev_out[c], r.end() - r.begin(), &dW[c*out_size_ + r.begin()]);
for (int i = r.begin(); i < r.end(); i++)
db[i] += curr_delta[i];
});
return prev_->back_propagation(prev_delta_[index], index);
}
四、注意事項
1、卷積層和下采樣層的前向/反向傳播函數
在fully_connected_layer類中我們發現其內部封裝了前向/反向傳播函數,但在之前介紹的卷積層和均值下采樣層中我們並沒有發現前向/反向傳播函數的影子,但前向/反向傳播函數確實是一個全局的過程,不可能出現斷層,因此仔細研究就會發現原來作者是將convolutional_layer類和average_pooling_layer對應的前向/反向傳播函數封裝在了它們共同的基類:partial_connected_layer中了。
2、前向傳播函數和反向傳播函數
在這篇博文中我為後續的博文中挖下了很多大坑,尤其像前向/反向傳播函數這種卷積神經網絡訓練的精華部分,是最能體現作者編程功力和框架設計功力的地方,一兩篇博文都不一定能講的清楚,所以請大家不要著急,我會盡快把其中的玄機弄明白,然後用通俗的語言進行解釋的,所以說,坑一定會都一一填上的。