數組的基本概念:數組是最簡單最常用的數據結構,但是也有一些注意事項:
(1)數組的分配方式以及存儲位置;
(2)初始化;
(3)不同語言中的數組高級定義;
(4)多維數組;
C/C++中數組分配方式:
(1)int a[10];
適用於數組長度已知或者對數組長度不敏感的情況,比如定義一個字符串。
(2)int *a = (int *)malloc(sizeof(int)*n);
用在C中,適用於動態申請數組的長度。記得最後要free,防止內存洩露。
(3)int[] a = new int[n];
用在C++中。最後要delete。
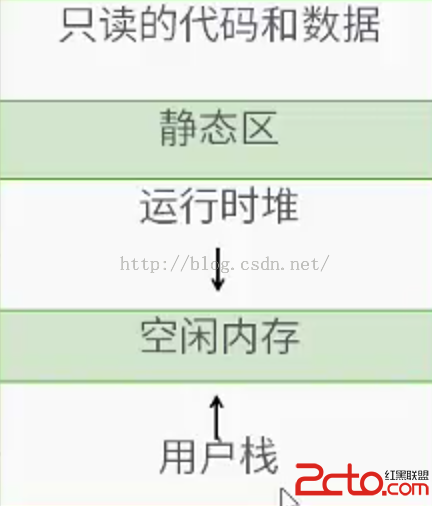
進程的虛擬地址空間:
 。
。
進程在運行的過程中會將地址劃分為許多段,重要的有兩個:運行時堆和用戶棧。動態申請的數組(malloc和new)會在運行時堆中,常量數組(int a[10])會放在用戶棧裡面。放在運行時堆中的數組是永久性的,不主動釋放就會永久存在,所以才會導致內存洩露。而在用戶棧空間是臨時,會隨著函數的調用和返回進行回收。所以我們不能返回局部變量的地址,尤其是返回一個常量數組的首地址,因為這個地址會在用完之後被回收。所以說一個函數如果在函數內部被修改,想要在函數外部繼續用的話,就要使用動態分配的數組。
C/C++中數組的初始化
編程中很多bug都是由直接引用未初始化的變量導致的,一般數組的初始話如下:
(1)全局數組自動初始化;
(2)malloc方式不初始化,可以用memset(可初始化為0或者-1),fill進行初始化;
(3)new方式需要根據編譯器判斷;
基礎的數組直接操作內存,效率高,但是缺乏豐富的api,所以高級語言往往會有相應的高級實現。C/C++中使用STL中的vector.
多維數組是一維數組的擴展,二維數組可以用來描述矩陣或者圖,如下:
int a1[10][10];//要求數組的兩維都確定;
int **a2;//兩維都不確定;
int* a3[10];//每一維單獨分配,長度可以不一致;
vector a4[10];//只能在C++中使用;
vector> a5;//只能在C++中使用;
數組在排序中的作用
對於常用的七大排序,在我前面幾篇博客中都有講到,包括代碼實現。其中數組在排序中有非常大的作用,下面做一個簡單的排序概述:
復雜度為O(n^2):
(1)插入排序-復雜度為O(n^2)中最快的;
(2)選擇排序、冒泡排序比較慢,一般會出現在面試題中。
復雜度為O(N*logN):
(1)快速排序:基於比較的排序中速度最快的;
(2)歸並排序:實際中較少使用,經常在面試中;
(3)堆排序:實際中較少使用,但是堆很常用;
復雜度為O(n),只能對正整數進行排序:
(1)基數排序-復雜度O(n+r),r為基數;
(2)計數排序-復雜度O(n+k),k為元素范圍;
但是在實際開發中,C/C++中自帶了排序函數:
(1)在C語言中有qsort函數,需要自定義cmp比較函數,函數形式如下:
int cmp(const void *a,const void *b);
(2)C++中,STL中自帶排序函數sort,調用方法如下:
sort(a.begin(),a.end(),[greater