一. 題目描述
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index.
According to the definition of h-index on Wikipedia: “A scientist has index h if h of his/her N papers have at least h citations each, and the other N ? h papers have no more than h citations each.”
For example, given citations = [3, 0, 6, 1, 5], which means the researcher has 5 papers in total and each of them had received 3, 0, 6, 1, 5 citations respectively. Since the researcher has 3 papers with at least 3 citations each and the remaining two with no more than 3 citations each, his h-index is 3.
Note: If there are several possible values for h, the maximum one is taken as the h-index.
二. 題目分析
首先需要了解一下題目的大意:
給定一個數組,記載了某研究人員的文章引用次數(每篇文章的引用次數都是非負整數),編寫函數計算該研究人員的h指數。
根據維基百科上對h指數的定義:“一名科學家的h指數是指在其發表的N篇論文中,有h篇論文分別被引用了至少h次,其余N-h篇的引用次數均不超過h次”。
例如,給定一個數組citations = [3, 0, 6, 1, 5],這意味著該研究人員總共有5篇論文,每篇分別獲得了3, 0, 6, 1, 5次引用。由於研究人員有3篇論文分別至少獲得了3次引用,其余兩篇的引用次數均不超過3次,因而其h指數是3。
注意:如果存在多個可能的h值,取最大值作為h指數。
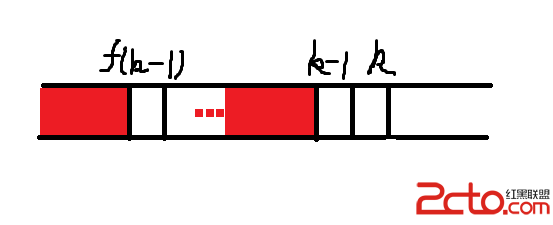
通過下圖,可以更直觀了解h值的定義,對應圖中,即是球左下角正方形的最大值:

以下解釋中,假設給定數組的大小為N,即共有N篇文章。
常規的做法有兩種,也是題目tips中提到的,首先想到的是將數組進行排序,然後從後往前遍歷,找出這個h值,該方法的復雜度是:O(n*logn)。
在面試中,若允許使用輔助內存,可以使用第二種方法,即開辟一個新數組 四. 小結 使用何種方法,需要根據實際條件而定。record,用於記錄0~N次引用次數的各有幾篇文章(引用次數大於N的按照N次計算)遍歷數組,統計過後,遍歷一次統計數組recZ喎?http://www.Bkjia.com/kf/ware/vc/" target="_blank" class="keylink">vcmQ8L2NvZGU+o6y8tL/Jy+Oz9jxjb2RlPmg8L2NvZGU+1rW1xNfutPPWtaGjyrG85Li01NO2yM6qPGNvZGU+TyhuKTwvY29kZT6hozwvcD4NCjxwPjxzdHJvbmc+yP0uIMq+wP20+sLrPC9zdHJvbmc+PC9wPg0KPHByZSBjbGFzcz0="brush:java;">
// 排序+遍歷
class Solution {
public:
int hIndex(vector
// 第二種的方法
class Solution {
public:
int hIndex(vector