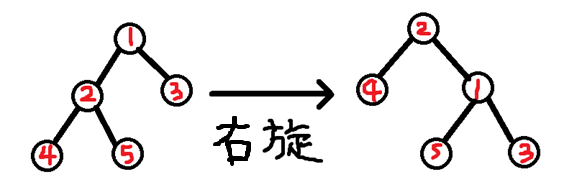
這裡的內容注意參考書籍《深入應用C++11代碼優化與工程級應用》
今天,重溫一下右值。
使用右值,使得我們的C++程序更加高效。
我們可以簡單把右值理解為一個臨時變量。之前,我們誰也不會在意這個臨時變量,但要付出了效率的代價。
而右值引用就是對右值進行的引用類型,與我們通常所說的引用一樣,一定要記得初始化。
左右值區分:
void func(X& x); // 左值引用 重載
void func(X&& x); // 右值引用 重載
X x;
X foobar();
func(x); // 參數為左值,調用func(X& x);
func(foobar()); // 參數為右值,調用func(X&& x);
再看看這個:
// lvalues:
//
int i = 42;
i = 43; // ok, i is an lvalue
int* p = &i; // ok, i is an lvalue
int& foo();
foo() = 42; // ok, foo() is an lvalue
int* p1 = &foo(); // ok, foo() is an lvalue
// rvalues:
//
int foobar();
int j = 0;
j = foobar(); // ok, foobar() is an rvalue
int* p2 = &foobar(); // error, cannot take the address of an rvalue
j = 42; // ok, 42 is an rvalue
之前在初始化列表的博客中提到過,使用初始化列表進行初始化,比在構造函數中初始化效率更高,道理是一樣的。
這結論一定是正確的,當你用VS編譯器試圖寫代碼進行驗證的時候,你也許就會罵娘了,這他媽輸出結果不是一樣的嗎。
我只能呵呵了,因為編譯器對程序進行了優化,你是看不到的。如果非要搞明白,就試圖一步一步看看反匯編吧,包你滿意。
下面就說說使用右值如何避免深拷貝。
此時,你可能又要犯嘀咕了?
深拷貝不是好事兒嗎,使我們自己寫的賦值構造函數實現深拷貝嗎,是為了避免兩個指針指向同一個東西,也避免刪除同一個東西兩次。
但,凡是都是在不停的發展的。因為C++11引入了右值概念,所以這就使得之前我們所寫的賦值構造函數並不是那麼完美了。主要還是效率的問題了。
下面就是用到了移動構造函數~之前也有提到過啊:
MyString(MyString&& str) {
std::cout <<"Move Constructor is called! source: "<< str._data << std::endl;
_len = str._len;
_data = str._data; // 避免了不必要的拷貝
str._len = 0;
str._data = NULL;
}
MyString&operator=(MyString&& str) {
std::cout <<"Move Assignment is called! source: "<< str._data << std::endl;
if (this != &str) {
_len = str._len;
_data = str._data; // 避免了不必要的拷貝
str._len = 0;
str._data = NULL;
}
return *this;
}
有了右值引用和移動語義,在設計和實現類時,對於需要動態申請大量資源的類,應該設計右值引用的拷貝構造函數和賦值函數,以提高應用程序的效率。需要注意的是,我們一般在提供右值引用的構造函數的同時,也會提供常量左值引用的拷貝構造函數,以保證移動不成還可以使用拷貝構造。