項目地址(由於課程TA要求,代碼地址在deadline後貼出,請見諒。)
轉載請注明出處。
前言
這是學校裡編譯原理課程的大作業,此Project十分適合編譯原理的學習,讓基本不聽課的我理解了一個編譯器的編寫過程。
所以忍不住想分享一下。
什麼是AQL?
全稱: Annotation Query Language
用於Text Analytics。
可以從非結構化或半結構化的文本中提取結構化信息的語言。
語法與SQL類似。
什麼是AQL Subset?
AQL語法復雜,功能強大,實現難度較高,作為學習用,我們選擇實現AQL的部分語法功能達到學習編譯器編寫的效果。
AQL Subset具有AQL的主要特點。
主要實現以下功能:
1. 通過regex來生成一個view。
2. 通過pattern來拼接多個view或者正則表達式處理的結果。
3. 通過select來選擇已有view的列生成新的view。
4. 打印view的結果。
例子:PerLoc.aql
1 create view Cap as
2 extract regex /[A-Z][a-z]*/
3 on D.text as Cap
4 from Document D;
5
6 create view Stt as
7 extract regex /Washington|Georgia|Virginia/
8 on D.text
9 return group 0 as Stt
10 from Document D;
11
12 create view Loc as
13 extract pattern (<C.Cap>) /,/ (<S.Stt>)
14 return group 0 as Loc
15 and group 1 as Cap
16 and group 2 as Stt
17 from Cap C, Stt S;
18
19 create view Per as
20 extract regex /[A-Z][a-z]*/
21 on D.text
22 return group 0 as Per
23 from Document D;
24
25 create view PerLoc as
26 extract pattern (<P.Per>) <Token>{1,2} (<L.Loc>)
27 return group 0 as PerLoc
28 and group 1 as Per
29 and group 2 as Loc
30 from Per P, Loc L;
31
32 create view PerLocOnly as
33 select PL.PerLoc as PerLoc
34 from PerLoc PL;
35
36 output view Cap;
37 output view Stt;
38 output view Loc;
39 output view Per;
40 output view PerLoc;
41 output view PerLocOnly;
假設處理的文本內容是:
Carter from Plains, Georgia, Washington from Westmoreland, Virginia
那麼輸出結果為:
Processing ../dataset/perloc/PerLoc.input View: Cap +----------------------+ | Cap | +----------------------+ | Carter:(0,6) | | Plains:(12,18) | | Georgia:(20,27) | | Washington:(29,39) | | Westmoreland:(45,57) | | Virginia:(59,67) | +----------------------+ 6 rows in set View: Stt +--------------------+ | Stt | +--------------------+ | Georgia:(20,27) | | Washington:(29,39) | | Virginia:(59,67) | +--------------------+ 3 rows in set View: Loc +--------------------------------+----------------------+--------------------+ | Loc | Cap | Stt | +--------------------------------+----------------------+--------------------+ | Plains, Georgia:(12,27) | Plains:(12,18) | Georgia:(20,27) | | Georgia, Washington:(20,39) | Georgia:(20,27) | Washington:(29,39) | | Westmoreland, Virginia:(45,67) | Westmoreland:(45,57) | Virginia:(59,67) | +--------------------------------+----------------------+--------------------+ 3 rows in set View: Per +----------------------+ | Per | +----------------------+ | Carter:(0,6) | | Plains:(12,18) | | Georgia:(20,27) | | Washington:(29,39) | | Westmoreland:(45,57) | | Virginia:(59,67) | +----------------------+ 6 rows in set View: PerLoc +------------------------------------------------+--------------------+--------------------------------+ | PerLoc | Per | Loc | +------------------------------------------------+--------------------+--------------------------------+ | Carter from Plains, Georgia:(0,27) | Carter:(0,6) | Plains, Georgia:(12,27) | | Plains, Georgia, Washington:(12,39) | Plains:(12,18) | Georgia, Washington:(20,39) | | Washington from Westmoreland, Virginia:(29,67) | Washington:(29,39) | Westmoreland, Virginia:(45,67) | +------------------------------------------------+--------------------+--------------------------------+ 3 rows in set View: PerLocOnly +------------------------------------------------+ | PerLoc | +------------------------------------------------+ | Carter from Plains, Georgia:(0,27) | | Plains, Georgia, Washington:(12,39) | | Washington from Westmoreland, Virginia:(29,67) | +------------------------------------------------+ 3 rows in set
很容易看懂,Cap這個view提取了大寫字母開頭的英文單詞,Stt提取了美國洲名的單詞,Loc對Cap和Stt進行拼接,按照中間只隔了一個逗號,且後一個單詞為州名為一個地名的規則得到地名。
其中group 0指的是匹配的結果,group 1, 2, 3...指的是匹配規則中括號的內容。
然後Per人名假設和Cap一樣,那麼PerLoc則是拼接了Per和Loc,指定中間間隔1到2個Token(以字母或者數字組成的無符號分隔的字符串,或者單純的特殊符號,不包含空白符。)。
最後PerLocOnly則是從view PerLoc中select了一個列出來。
其中配個匹配後面的(x, y)指的是匹配的字符在原文中的位置,左閉右開。
然後output view xxx就是把提取出的view打印出來得到了以上的結果。
Language
aql_stmt → create_stmt ; | output_stmt ;
create_stmt → create view ID as view_stmt
view_stmt → select_stmt | extract_stmt
output_stmt → output view ID alias
alias → as ID | ε
elect_stmt → select select_list from from_list
select_list → select_item | select_list , select_item
select_item → ID . ID alias
from_list → from_item | from_list , from_item
from_item → ID ID
extract_stmt → extract extract_spec from from_list
extract_spec → regex_spec | pattern_spec
regex_spec → regex REG on column name_spec
column → ID . ID
name_spec → as ID | return group_spec
group_spec → single_group | group_spec and single_group
single_group → group NUM as ID
pattern_spec → pattern pattern_expr name_spec
pattern_expr → pattern_pkg | pattern_expr pattern_pkg
pattern_pkg → atom | atom { NUM , NUM } | pattern_group
atom→ < column > | < Token > | REG
pattern_group → ( pattern_expr )
以上為AQL Subset的文法,這是語法分析生成抽象語法樹的規則。
從文法可以看出,所有文法左邊的為非終結符,而其他的關鍵詞為終結符(語法數的葉子節點)。
編譯器結構
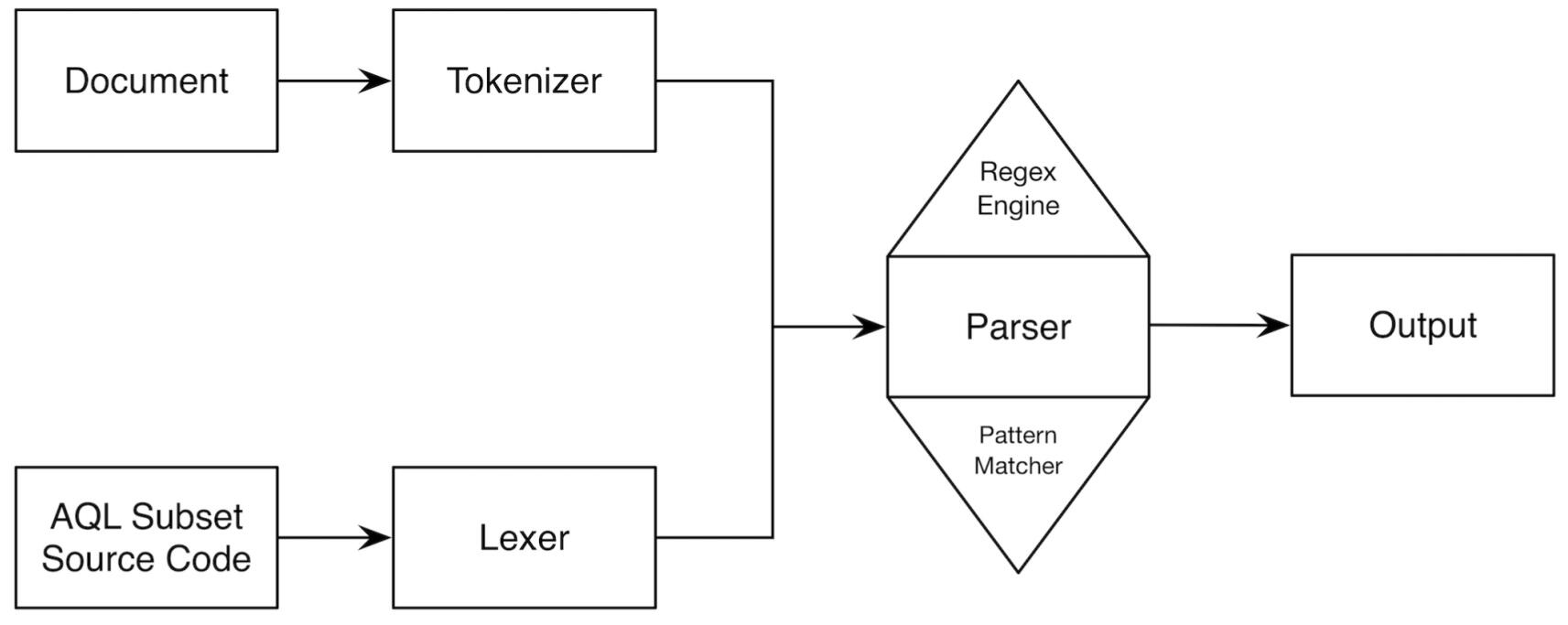
詞法分析器(Lexer)
首先要把AQL語言源文件輸入到詞法分析器中,詞法分析器的職責就是從一個字符串中提取出AQL語言的非終結符序列,然後這個非終結符序列作為輸入提供給語法分析器解析生成抽象語法樹。
那Lexer要做的事情就很清晰了,首先定義一個token(非終結符)的數據結構如下:
1 struct token {
2 std::string value;
3 Type type;
4 bool is_grouped;
5 token(std::string value, Type type) {
6 this->value = value;
7 this->type = type;
8 this->is_grouped = false;
9 }
10 bool operator==(const token &t) const {
11 return this->value == t.value && this->type == t.type;
12 }
13 };
value是匹配到的字符串,Type為token的類型,is_grouped是之後語法分析的時候匹配group用的,暫時不管。
然後根據AQL Subset的文法(上面的Language),可以得出非終結符的類型有如下:
typedef enum {
CREATE, VIEW, AS, OUTPUT, SELECT, FROM, EXTRACT, REGEX, ON, RETURN,
GROUP, AND, TOKEN, PATTERN, ID, DOT, REG, NUM, LESSTHAN, GREATERTHAN,
LEFTBRACKET, RIGHTBRACKET, CURLYLEFTBRACKET, CURLYRIGHTBRACKET, SEMICOLON, COMMA, END, EMPTY
} Type;
最後兩個END和EMPTY也是方便語法分析用的,並不是一個真實的token類型。
然後定義一個Lexer類:
1 class Lexer {
2 public:
3 Lexer(char *file_path);
4 std::vector<token> get_tokens();
5 private:
6 std::vector<token> tokens;
7 };
Lexer在構造函數的時候就把AQL源文件進行處理得到一組token存放在tokens這個vector裡,然後提供get_tokens方便語法分析器調用獲得到tokens。
具體實現細節我不會在這裡講述,感興趣的可以回到頂部進入項目代碼地址查看源代碼。
語法分析器(Parser)
語法分析器做的就是利用詞法分析出來的token序列,構建出一個抽象語法樹(AST),然後傳遞給編譯器後端執行(Lexer + Parser我們通常稱為編譯器的前端)。
編譯器後端做的主要是根據語法樹的結構,完成具體的執行邏輯。
這裡需要注意!很多同學混淆不清的一個問題:這裡所說的構建抽象語法樹並不是在數據結構上去構建一顆樹出來,這裡的樹的意思體現在函數的調用邏輯,舉個例子,一個簡單的DFS搜索,遞歸實現,這個搜索經常會呈現出一個樹的邏輯結構。
然後根據文法(Language),我們可以定義一個Parser類:
1 class Parser {
2 public:
3 Parser(Lexer lexer, Tokenizer tokenizer, const char *output_file, const char *processing);
4 ~Parser();
5 token scan();
6 void match(std::string);
7 void error(std::string str);
8 void output_view(view v, token alias_name);
9 void program();
10 void aql_stmt();
11 void create_stmt();
12 std::vector<col> view_stmt();
13 void output_stmt();
14 token alias();
15 std::vector<col> select_stmt();
16 std::vector<token> select_list();
17 std::vector<token> select_item();
18 std::vector<token> from_list();
19 std::vector<token> from_item();
20 std::vector<col> extract_stmt();
21 std::vector<token> extract_spec();
22 std::vector<token> regex_spec();
23 std::vector<token> column();
24 std::vector<token> name_spec();
25 std::vector<token> group_spec();
26 std::vector<token> single_group();
27 std::vector<token> pattern_spec();
28 std::vector<token> pattern_expr();
29 std::vector<token> pattern_pkg();
30 std::vector<token> atom();
31 std::vector<token> pattern_group();
32 inline col get_col(view v, std::string col_name);
33 inline view get_view(std::string view_name);
34 inline void print_line(view &v);
35 inline void print_col(view &v);
36 inline void print_span(view &v);
37 private:
38 std::vector<token> lexer_tokens;
39 int lexer_parser_pos;
40 token look;
41 std::vector<document_token> document_tokens;
42 std::vector<view> views;
43 FILE *output_file;
44 };
需要注意的是構造函數裡的tokenizer並不是詞法分析器,只是AQL需要處理的文本的分詞器,作用和Lexer類似,因為在pattern匹配的時候需要用到<Token>的表示。
然後從樹的根節點program()開始,不斷的根據文法規則和look(預讀的token,通過look我們可以唯一的定位到在一個非終結符節點下一步的函數調用)調用,然後利用函數的返回值傳遞必要的執行參數(我這裡主要是以token的vector形式實現)。
這樣描述可能有點抽象,看個具體的例子。
來看我們之前例子的第一個create語句:
create view Cap as
extract regex /[A-Z][a-z]*/
on D.text as Cap
from Document D;
我們根據向前看規則,可以得到如下抽象語法樹:
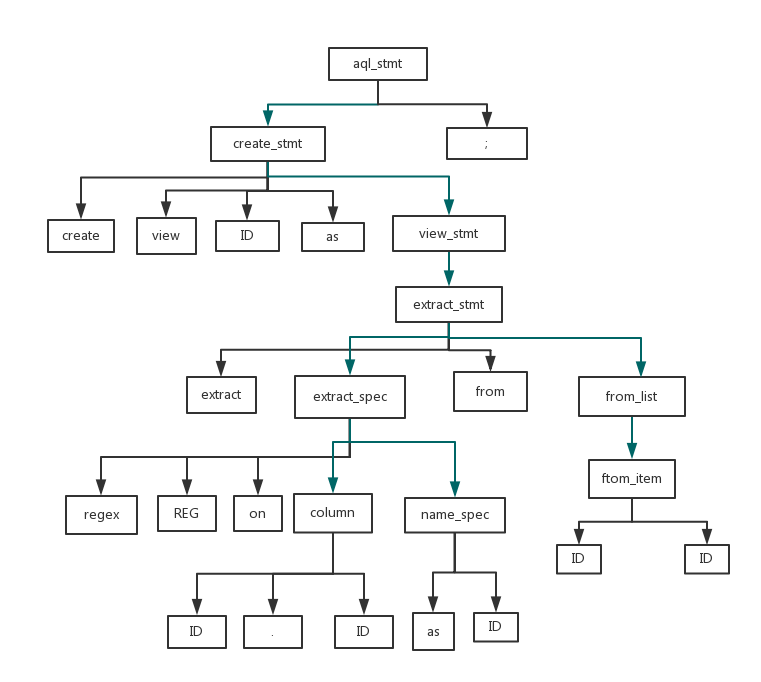
綠色的線表示函數調用,黑色表示終結符匹配。
來看預讀的token是怎麼幫助我們找到正確的函數調用的,以非終結符節點aql_stmt為例:
aql_stmt → create_stmt ; | output_stmt ;
aql_stmt可以推導出create_stmt+;或者output_stmt+;。
然後此時如果look.Type是CREATE的話其實就意味著應該調用create_stmt,如果是output_stmt的話此時預讀的token類型應該是OUTPUT。
整體思路就是這樣,我們分別把每個非終結符按照文法規則利用預讀的look即可完成一個抽象語法樹的結構(非終結符的節點箭頭指向表示的是函數調用)。
編譯器後端
我們在抽象語法樹構造的過程中,在必要的節點返回程序執行需要的數據,然後後端做的事情就是利用抽象語法樹提取出來的關鍵數據去執行AQL語言需要實現的邏輯。
而AQL Subset的後端邏輯其實只有4個:
1. 利用正則表達式創建一個view。
2. 利用pattern匹配創建一個view。
3. 利用select提取創建一個view。
4. 打印view。
按理說還應該抽象出一個執行類,提供方法,讓Parser直接調用去執行的,由於這裡後端邏輯挺簡單的我就直接寫在抽象語法樹構造過程函數的內部了。
對應分別是:
1. extract_stmt的條件分支(Parser.cpp 200-215行)實現正則提取文本。
2. extract_stmt的條件分支(Parser.cpp 216-302行)實現pattern匹配提取文本。
3. select_stmt尾部實現select邏輯。
4. output_view函數實現打印邏輯。
5. view的創建邏輯實現在create_stmt尾部。
具體實現沒什麼好說的了,coding就是了。
完成之後可以自己玩各種有趣的文本處理,比如我從HTML文本中提取出所有meta的內容,又比如可以提取出HTML中所有的class, id等等....(結果可以參考dataset/html/*.output,提取的aql源文件為dataset/html.aql)。
一些體會
一個編譯器的編寫完全體現了自頂向下,逐步求精的分而治之的架構思想,其實具體coding對於大三的學生來說已經完全不是什麼難事了,重要的是怎麼把一個大的問題不斷分治到能夠被輕易解決的小的問題上來。
謝謝。