opencl初探-sobel檢測,opencl初探-sobel
sobel檢測的C版本,neon和GPU的時間比較。
Platform:
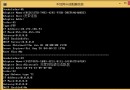
LG G3, Adreno 330 ,img size 3264x2448
sobel:
C code
neon
GPU
73
13
42+3.7+6.6
單位:ms
GPU時間=memory
time+Queued time+Run time
Sobel org
Sobel vector
Sobel vector +
mem_fence
Queued time
4.6
7.2
2.8
Wait time
0.07
0.09
0.07
Run time
66.9
7.3
6.6

![]()
typedef unsigned char BYTE;
void sobel(BYTE *src,int w,int h,BYTE *Ix,BYTE *Iy)
{
int src_step = w;
int dst_step = w;
int x, height = h - 2;
BYTE* dstX = Ix+dst_step;
BYTE* dstY = Iy+dst_step;
for( ; height--; src += src_step, dstX += dst_step, dstY += dst_step )
{
const BYTE* src2 = src + src_step;
const BYTE* src3 = src + src_step*2;
for( x = 1; x < w-1 ; x++ )
{
short t0 = 0 ;
short t1 = 0 ;
t0 = -src[x-1]+src[x+1] ;
t1 = src[x-1]+(src[x]<<1)+src[x+1];
t0 += ((-src2[x-1]+src2[x+1])<<1) ;
t0 += -src3[x-1]+src3[x+1] ;
t1 -= ( src3[x-1]+(src3[x]<<1)+src3[x+1] );
dstX[x] = t0>>3;
dstY[x] = t1>>3;
}
}
}
void sobel_neon(BYTE *src,int w,int h,BYTE *Ix,BYTE *Iy)
{
int src_step = w;
int dst_step = w;
int x, height = h - 2;
BYTE* dstX = Ix+dst_step;
BYTE* dstY = Iy+dst_step;
for( ; height--; src += src_step, dstX += dst_step, dstY += dst_step )
{
const BYTE* src2 = src + src_step;
const BYTE* src3 = src + src_step*2;
x = 1;
while((x+8) <= w-1 )
{
uint8x8_t left = vld1_u8(src+x-1);
uint8x8_t mid = vld1_u8(src+x) ;
uint8x8_t right = vld1_u8(src+x+1) ;
int16x8_t t0 = vreinterpretq_s16_u16( vsubl_u8(right,left) ) ;
int16x8_t t1 = vaddq_s16( vreinterpretq_s16_u16( vaddl_u8(left,right) ) ,
vreinterpretq_s16_u16( vshll_n_u8(mid,1) ) );
left = vld1_u8(src2+x-1);
right = vld1_u8(src2+x+1) ;
int16x8_t temp = vreinterpretq_s16_u16( vsubl_u8(right,left) );
t0 = vaddq_s16(t0,vshlq_n_s16(temp,1));
left = vld1_u8(src3+x-1);
mid = vld1_u8(src3+x) ;
right = vld1_u8(src3+x+1) ;
t0 = vaddq_s16(t0,vreinterpretq_s16_u16( vsubl_u8(right,left) ));
temp = vaddq_s16( vreinterpretq_s16_u16( vaddl_u8(left,right) ) ,
vreinterpretq_s16_u16( vshll_n_u8(mid,1) ) );
t1 = vsubq_s16(t1,temp);
vst1_s8((int8_t*)dstX+x,vshrn_n_s16(t0,3));
vst1_s8((int8_t*)dstY+x,vshrn_n_s16(t1,3));
x += 8;
}
while( (x) < w-1 )
{
short t0 = 0 ;
short t1 = 0 ;
t0 = -src[x-1]+src[x+1] ;
t1 = src[x-1]+(src[x]<<1)+src[x+1];
t0 += ((-src2[x-1]+src2[x+1])<<1) ;
t0 += -src3[x-1]+src3[x+1] ;
t1 -= ( src3[x-1]+(src3[x]<<1)+src3[x+1] );
dstX[x] = t0>>3;
dstY[x] = t1>>3;
x++;
}
}
}
View Code