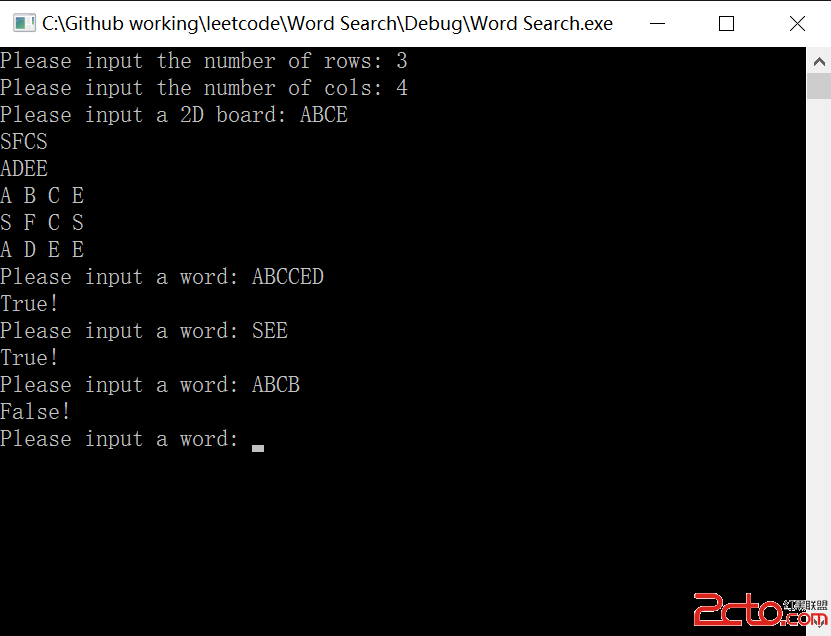
給定一個字符串S,一個單詞的列表words,全是相同的長度。
找到的子串(多個)以s即每個詞的字串聯恰好一次並沒有任何插入的字符所有的起始索引。
You are given a string, s, and a list of words, words, that are all of the same length. Find all starting indices of substring(s) in s that is a concatenation of each word in words exactly once and without any intervening characters.
For example, given:
s: barfoothefoobarman
words: [foo, bar]
You should return the indices: [0,9].
(order does not matter).
難度對我來說還是太大了,但還是先發個博客占個位置,不然以後順序就不連串了……
// for sort the |words|
int strcmp1(const void* p1, const void* p2) {
return strcmp(*(char**)p1, *(char**)p2);
}
// to handle duplicate words in |words|
struct word_t {
char* w;
int count;
int* pos;
int cur;
};
int word_t_cmp(const void* p1, const void* p2) {
return strcmp(((const struct word_t*)p1)->w, ((const struct word_t*)p2)->w);
}
/**
* Return an array of size *returnSize.
* Note: The returned array must be malloced, assume caller calls free().
*
* It is a variant of the longest-substring-without-repetition problem
*/
int* findSubstring(char* s, char** words, int wordsSize, int* returnSize) {
if (!s || wordsSize == 0 || strlen(s) < wordsSize*strlen(words[0])) {
*returnSize = 0;
return NULL;
}
if (strlen(s) == 0 && strlen(words[0]) == 0) {
*returnSize = 1;
int* ret = (int*) malloc(sizeof(int));
ret[0] = 0;
return ret;
}
int n = strlen(s);
int k = strlen(words[0]);
// sort |words| first, prepare for binary search
qsort(words, wordsSize, sizeof(char*), strcmp1);
// construct array of word_t
// @note please note that after construction, |wts| is already sorted
struct word_t* wts = (struct word_t*) malloc(wordsSize * sizeof(struct word_t));
int wtsSize = 0;
for (int i = 0; i < wordsSize;) {
char* w = words[i];
int count = 1;
while (++i < wordsSize && !strcmp(w, words[i]))
count++;
struct word_t* wt_ptr = wts + wtsSize++;
wt_ptr->w = w;
wt_ptr->count = count;
wt_ptr->pos = (int*) malloc(count * sizeof(int));
wt_ptr->cur = 0;
}
// store one word
struct word_t wt;
wt.w = (char*) malloc((k+1) * sizeof(char));
// return value
int cap = 10;
int* ret = (int*) malloc(cap * sizeof(int));
int size = 0;
for (int offset = 0; offset < k; offset++) {
// init word_t array
for (int i = 0; i < wtsSize; i++) {
struct word_t* wt_ptr = wts + i;
for (int j = 0; j < wt_ptr->count; j++)
wt_ptr->pos[j] = -1;
wt_ptr->cur = 0;
}
int start = offset; // start pos of current substring
int len = 0; // number of words encountered
for (int i = offset; i <= n - k; i += k) {
strncpy(wt.w, s+i, k);
wt.w[k] = '';
struct word_t* p = (struct word_t*) bsearch(&wt, wts, wtsSize, sizeof(struct word_t), word_t_cmp);
if (!p) {
start = i + k;
len = 0;
continue;
}
// @note the following five lines covers extra occurrence of
// (possible duplicate) word, you can draw some special case
// on a paper if it's hard to understand why it could cover
// all boundary conditions
// |p->cur| and |p->pos| implement a simple rounded queue,
// and |p->cur| always point to the smallest index position
int pos = p->pos[p->cur];
p->pos[p->cur++] = i;
if (p->cur >= p->count)
p->cur -= p->count;
if (pos < start) { // valid occurrence of this word in current substring started at |start|
len++;
if (len == wordsSize) { // all words encounterd, add to result set
if (size == cap) { // extend the array
cap = 2*cap;
int* tmp = (int*) malloc(cap * sizeof(int));
memcpy(tmp, ret, size*sizeof(int));
free(ret);
ret = tmp;
}
ret[size++] = start;
// move substring forward by one word length
start += k;
len--;
}
} else { // extra occurence of (possible duplicat) word encountered, update |start| and |len|
start = pos + k;
len = (i - start)/k + 1;
}
}
}
// cleanup
for (int i = 0; i < wtsSize; i++)
free(wts[i].pos);
free(wts);
*returnSize = size;
if (size == 0) {
free(ret);
ret = NULL;
}
return ret;
}