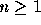標題是個噱頭,這裡只說積分數據全部裝載到內存
首先,玩家的積分什麼的有單獨的表存儲,這裡不談序列化,語言是C++
假定score是double,id是int64
然後計算空間需求,這裡假設實現了專用無稅收的內存適配器
32位進程大地址,每個節點32字節,4G的進程可以放下1.34億的數據,去掉進程本身的邊角,1.2億
64位進程,每個節點48字節,1億數據需要4.47G內存,根據需要自己給服務器加內存吧...
然後就沒有然後了...
就是這麼簡單粗暴的把所有積分塞進內存
查詢第k名玩家的id
查詢積分n可以排多少名
好吧,存在的問題是,更新略惡心,用積分做k,存在相同積分時候,equal_range後遍歷找到對應id,erase後重新insert吧
序列化什麼的,可以考慮內存映射文件+對應內存適配器來搞定
然後說說容器本身!
自己碼的sorted_set類,可隨機訪問的kv容器,std::multimap風格,允許重復key
operator[]操作不明確下標訪問或是key-value查詢,所以沒有實現
內部二叉樹結構,除了parent,left,right之外,只有一個SBT需要的size域,4個指針大小
隨機訪問迭代器,可以+/-/+=/-=操作,可以兩個迭代器相減求距離
這裡的rank從0開始,並沒有給出select函數,而是參考std::vector使用at隨機訪問
各種接口的復雜度不超過O(log2n),參考陳啟峰的size balanced tree
實測4千萬數據,可以達到每秒百萬查,作為一般的游戲行業,算是足夠了
樹結構還算平衡,順序/亂序插入的時間開銷是std::multimap的1.2倍左右,這裡請教是不是我實現有問題?

最後念叨點題外的!
說起來個人比較懶...
最初是我的俄羅斯方塊AI裡面的需求,對有序的std::vector不斷歸並,std::merge成了性能瓶頸!
之後考慮節AI內部本身就是一個個節點,直接建立二叉樹來排序效果應該不錯,但是AI內部節點都是百萬級別!
於是直接用std::map的問題就是new的時候會有稅收,而且本身就是AI節點,所以參考std::map源碼直接搞了個一個不去new節點,直接把外部節點掛在樹上的容器!還沒有clear開銷!
似乎就是這樣了,然而後來聽說size balanced tree比red black tree性能還好,然後改造起來也不麻煩!索性順手加上那個神maintain來測試一下性能~
結果實測,比紅黑樹稍慢,也可能是我的實現有問題?沒有達到陳啟峰說的超越紅黑樹,不過也算是一個數量級~
最終俄羅斯方塊AI還是用了紅黑樹...
------分割線------
群裡某人問:"SortedList相當於C++裡的啥容器?"
於是我就把之前的外掛節點的容器拿來重構...
暫時叫sorted_set,跟redis的Z系列很像,同npm的sorted-set(內部跳表實現)
相比其他的rank tree實現,附加域沒有任何浪費什麼的太漂亮了
本文3個目的
1.安利一下size balanced tree
2.找高人看看我的實現有什麼問題
3.拋磚引玉
最後傳送門