編寫C++中的兩個類 一個只能在棧中分配空間 一個只能在堆中分配。
解答: (1)代碼如下#include<iostream>
using namespace std;
//只能在堆上分配內存
class HeapOnly
{
public:
HeapOnly()
{
cout<<"Construct."<<endl;
}
void destory()
{
delete this;
}
private:
~HeapOnly()
{
}
};
//只能在棧上分配空間
class StackOnly
{
public:
StackOnly()
{
}
~StackOnly()
{
}
private:
void* operator new(size_t size) //將new操作符私有化,在外面無法調用
{
}
};
int main()
{
HeapOnly *hO=new HeapOnly();
hO->destory();
//HeapOnly he; //編譯錯誤:HeapOnly::~HeapOnly”: 無法訪問 private 成員(在“HeapOnly”類中聲明),所以不能通過棧來分配這個對象的空間
StackOnly so;
//StackOnly *st=new StackOnly(); //StackOnly::operator new”: 無法訪問 private 成員(在“StackOnly”類中聲明)
}
(2)堆棧分配內存的介紹
一、一個經過編譯的C/C++的程序占用的內存分成以下幾個部分:
1、棧區(stack):由編譯器自動分配和釋放 ,存放函數的參數值、局部變量的值等,甚至函數的調用過程都是用棧來完成。其操作方式類似於數據結構中的棧。
2、堆區(heap) :一般由程序員手動申請以及釋放, 若程序員不釋放,程序結束時可能由OS回收 。注意它與數據結構中的堆是兩回事,分配方式類似於鏈表。
3、全局區(靜態區)(static):全局變量和靜態變量的存儲是放在一塊的,初始化的全局變量和靜態變量在一塊區域, 未初始化的全局變量和未初始化的靜態變量在相鄰的另一塊區域。程序結束後由系統釋放空間。
4、文字常量區:常量字符串就是放在這裡的。 程序結束後由系統釋放空間。
5、程序代碼區:存放函數體的二進制代碼。
下面的例子可以完全展示不同的變量所占的內存區域:
//main.cpp
int a = 0; 全局初始化區
char *p1; 全局未初始化區
main(){
int b; //棧中
char s[] = "abc"; //棧中
char *p2; //棧中
char *p3 = "123456"; //123456/0在常量區,p3在棧上
static int c =0; //全局(靜態)初始化區
//以下分配得到的10和20字節的區域就在堆區
p1 = (char *)malloc(10);
p2 = new char[20];//
(char *)malloc(20);strcpy(p1, "123456");
//123456/0放在常量區,編譯器可能會將它與p3所指向的"123456"優化成一個地方。
}
二、棧(stack)和堆(heap)具體的區別。
1、在申請方式上
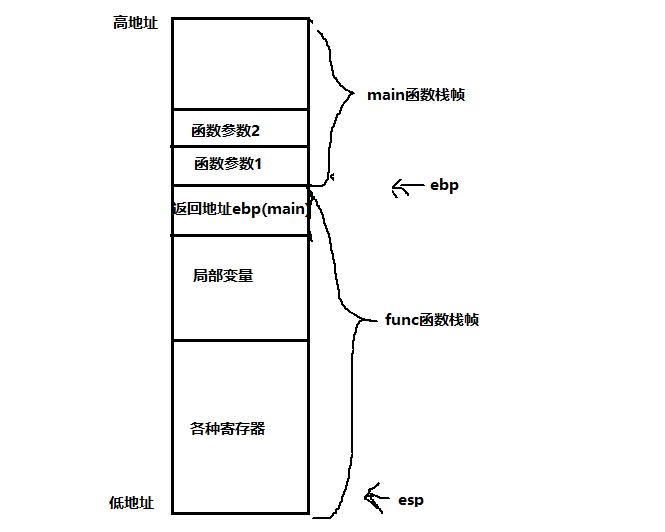
棧(stack): 現在很多人都稱之為堆棧,這個時候實際上還是指的棧。它由編譯器自動管理,無需我們手工控制。 例如,聲明函數中的一個局部變量 int b 系統自動在棧中為b開辟空間;在調用一個函數時,系統自動的給函數的形參變量在棧中開辟空間。
堆(heap): 申請和釋放由程序員控制,並指明大小。容易產生memory leak。
在C中使用malloc函數。
如:p1 = (char *)malloc(10);
在C++中用new運算符。
如:p2 = new char[20];//(char *)malloc(10);
但是注意p1本身在全局區,而p2本身是在棧中的,只是它們指向的空間是在堆中。
2、申請後系統的響應上
棧(stack):只要棧的剩余空間大於所申請空間,系統將為程序提供內存,否則將報異常提示棧溢出。
堆(heap): 首先應該知道操作系統有一個記錄空閒內存地址的鏈表,當系統收到程序的申請時, 會遍歷該鏈表,尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閒結點鏈表中刪除,並將該結點的空間分配給程序。另外,對於大多數系統,會在這塊內存空間中的首地址處記錄本次分配的大小,這樣,代碼中的delete或free語句才能正確的釋放本內存空間。另外,由於找到的堆結點的大小不一定正好等於申請的大小,系統會自動的將多余的那部分重新放入空閒鏈表中。
3、申請大小的限制
棧(stack):在Windows下,棧是向低地址擴展的數據結構,是一塊連續的內存的區域。這句話的意思是棧頂的地址和棧的最大容量是系統預先規定好的,在WINDOWS下,棧的大小是2M(也有的說是1M,總之是一個編譯時就確定的常數),如果申請的空間超過棧的剩余空間時,將提示overflow。因此,能從棧獲得的空間較小。 例如,在VC6下面,默認的棧空間大小是1M(好像是,記不清楚了)。當然,我們可以修改:打開工程,依次操作菜單如下:Project->Setting->Link,在Category 中選中Output,然後在Reserve中設定堆棧的最大值和commit。
注意:reserve最小值為4Byte;commit是保留在虛擬內存的頁文件裡面,它設置的較大會使棧開辟較大的值,可能增加內存的開銷和啟動時間。
堆(heap): 堆是向高地址擴展的數據結構,是不連續的內存區域(空閒部分用鏈表串聯起來)。正是由於系統是用鏈表來存儲空閒內存,自然是不連續的,而鏈表的遍歷方向是由低地址向高地址。一般來講在32位系統下,堆內存可以達到4G的空間,從這個角度來看堆內存幾乎是沒有什麼限制的。由此可見,堆獲得的空間比較靈活,也比較大。
4、分配空間的效率上
棧(stack):棧是機器系統提供的數據結構,計算機會在底層對棧提供支持:分配專門的寄存器存放棧的地址,壓棧出棧都有專門的指令執行,這就決定了棧的效率比較高。但程序員無法對其進行控制。
堆(heap):是C/C++函數庫提供的,由new或malloc分配的內存,一般速度比較慢,而且容易產生內存碎片。它的機制是很復雜的,例如為了分配一塊內存,庫函數會按照一定的算法(具體的算法可以參考數據結構/操作系統)在堆內存中搜索可用的足夠大小的空間,如果沒有足夠大小的空間(可能是由於內存碎片太多),就有可能調用系統功能去增加程序數據段的內存空間,這樣就有機會分到足夠大小的內存,然後進行返回。這樣可能引發用戶態和核心態的切換,內存的申請,代價變得更加昂貴。顯然,堆的效率比棧要低得多。
5、堆和棧中的存儲內容
棧(stack):在函數調用時,第一個進棧的是主函數中子函數調用後的下一條指令(子函數調用語句的下一條可執行語句)的地址,然後是子函數的各個形參。在大多數的C編譯器中,參數是由右往左入棧的,然後是子函數中的局部變量。注意:靜態變量是不入棧的。 當本次函數調用結束後,局部變量先出棧,然後是參數,最後棧頂指針指向最開始存的地址,也就是主函數中子函數調用完成的下一條指令,程序由該點繼續運行。
堆(heap):一般是在堆的頭部用一個字節存放堆的大小,堆中的具體內容有程序員安排。
6、存取效率的比較
這個應該是顯而易見的。拿棧上的數組和堆上的數組來說:
void main()
{
int arr[5]={1,2,3,4,5};
int *arr1;
arr1=new int[5];
for (int j=0;j<=4;j++) { arr1[j]=j+6; }
int a=arr[1];
int b=arr1[1];
}
上面代碼中,arr1(局部變量)是在棧中,但是指向的空間確在堆上,兩者的存取效率,當然是arr高。因為arr[1]可以直接訪問,但是訪問arr1[1],首先要訪問數組的起始地址arr1,然後才能訪問到arr1[1]。
總而言之,言而總之:
堆和棧的區別可以用如下的比喻來看出:
使用棧就象我們去飯館裡吃飯,只管點菜(聲明變量)、付錢、和吃(使用),吃飽了就走,不必理會切菜、洗菜等准備工作和洗碗、刷鍋等掃尾工作,他的好處是快捷,但是自由度小。
使用堆就象是自己動手做喜歡吃的菜肴,比較麻煩,但是比較符合自己的口味,而且自由度大。