項目中有一處需求,需要把長網址縮為短網址,把結果通過短信、微信等渠道推送給客戶。剛開始直接使用網上現成的開放服務,然後在某個周末突然手癢想自己動手實現一個別具特色的長網址文本)縮短服務。
由於以前做過socket服務,對數據包的封裝排列還有些印象,因此,短網址服務我第一反應是先設計數據的存儲格式,我這裡沒有采用數據庫,而是使用2個文件來實現:
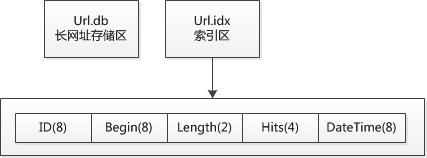
Url.db存儲用戶提交的長網址文本,Url.idx 存儲數據索引,記錄每次提交數據的位置Begin)與長度Length),還有一些附帶信息Hits,DateTime)。由於每次添加長網址,對 兩個文件都是進行Append操作,因此即使這兩個文件體積很大比如若干GB),也沒有太大的IO壓力。
再看看Url.idx文件的結構,ID是主鍵,設為Int64類型,轉換為字節數組後的長度為8,緊跟的是Begin,該值是把長網址數據續寫到 Url.db文件之前,Url.db文件的長度,同樣設為Int64類型。長網址的字符串長度有限,Int16足夠使用 了,Int16.MaxValue==65536,比Url規范定義的4Kb長度還大,Int16轉換為字節數組後長度為2字節。Hits表示短網址的解 析次數,設為Int32,字節長度為4,DateTime 設為Int64,長度8。由於ID不會像數據庫那樣自動遞增,因此需要手工實現。因此在開始寫入Url.idx前,需要預先讀取最後一行行是虛的,其實 就是最後30字節)中的的ID值,遞增後才開始寫入新的一行。
也就是說每次提交一個長網址,不管數據有多長最大不能超過65536字節),Url.idx 文件都固定增加 30 字節。
數據結構一旦明確下來,整個網址縮短服務就變得簡單明了。例如連續兩次提交長網址,可能得到的短網址為http://域名/1000,與http://域名/1001,結果顯然很丑陋,域名後面的ID全是數字,而且遞增關系明顯,很容易暴力枚舉全部的數據。而且10進制的數字容量有限,一次提交100萬條的長網址,產生的短網址越來越長,失去意義。
因此下面就開始對ID進行改造,改造的目標有2:
1、增加混淆機制,相鄰兩個ID表面上看不出區別。
2、增加容量,一次性提交100萬條長網址,ID的長度不能有明顯變化。
最簡單最直接的混淆機制,就是把10進制轉換為62進制0-9a-zA-Z),由於順序的abcdef…也很容易猜到下一個ID,因此62進制字符序列隨機排列一次:
/// <summary>
/// 生成隨機的0-9a-zA-Z字符串
/// </summary>
/// <returns></returns>
public static string GenerateKeys()
{
string[] Chars = "0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z".Split(',');
int SeekSeek = unchecked((int)DateTime.Now.Ticks);
Random SeekRand = new Random(SeekSeek);
for (int i = 0; i < 100000; i++)
{
int r = SeekRand.Next(1, Chars.Length);
string f = Chars[0];
Chars[0] = Chars[r - 1];
Chars[r - 1] = f;
}
return string.Join("", Chars);
}
運行一次上面的方法,得到隨機序列:
string Seq = "s9LFkgy5RovixI1aOf8UhdY3r4DMplQZJXPqebE0WSjBn7wVzmN2Gc6THCAKut";
用這個序列字符串替代0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,具有很強的混淆特性。一個10進制的數字按上面的序列轉換為62進制,將變得面目全非,附轉換方法:
/// <summary>
/// 10進制轉換為62進制
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Convert(long id)
{
if (id < 62)
{
return Seq[(int)id].ToString();
}
int y = (int)(id % 62);
long x = (long)(id / 62);
return Convert(x) + Seq[y];
}
/// <summary>
/// 將62進制轉為10進制
/// </summary>
/// <param name="Num"></param>
/// <returns></returns>
private static long Convert(string Num)
{
long v = 0;
int Len = Num.Length;
for (int i = Len - 1; i >= 0; i--)
{
int t = Seq.IndexOf(Num[i]);
double s = (Len - i) - 1;
long m = (long)(Math.Pow(62, s) * t);
v += m;
}
return v;
}
例如執行 Convert(123456789) 得到 RYswX,執行 Convert(123456790) 得到 RYswP。
如果通過分析大量的連續數值,還是可以暴力算出上面的Seq序列值,進而猜測到某個ID左右兩邊的數值。下面進一步強化混淆,ID每次遞增的單位不是固定的1,而是一個隨機值,比如1000,1005,1013,1014,1020,毫無規律可言。
private static Int16 GetRnd(Random seekRand)
{
Int16 s = (Int16)seekRand.Next(1, 11);
return s;
}
即使把62進制的值逆向計算出10進制的ID值,也難於猜測到左右兩邊的值,大大增加暴力枚舉的難度。難度雖然增加,但是連續產生的2個62進制值 如前面的RyswX與RyswP,僅個位數不同,還是很像,因此我們再進行第三次簡單的混淆,把62進制字符向左右)旋轉一定次數解析時反向旋轉同樣 的次數):
/// <summary>
/// 混淆id為字符串
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Mixup(long id)
{
string Key = Convert(id);
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return NewKey;
}
/// <summary>
/// 解開混淆字符串
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
private static long UnMixup(string Key)
{
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
x = Len - x;
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return Convert(NewKey);
}
執行 Mixup(123456789)得到wXRYs,假如隨機遞增值為7,則下一條記錄的ID執行 Mixup(123456796)得到swWRY,肉眼上很難再聯想到這兩個ID值是相鄰的。
以上講述了數據結構與ID的混淆機制,下面講述的是短網址的解析機制。
得到了短網址,如wXRYs,我們可以通過上面提供的UnMixup()方法,逆向計算出ID值,由於ID不是遞增步長為1的數字,因此不能根據ID馬上計算出記錄在索引文件中的位置如:ID * 30)。由於ID是按小到大的順序排列,因此在索引文件中定位ID,非二分查找法莫屬。
//二分法查找的核心代碼片段
FileStream Index = new FileStream(IndexFile, FileMode.OpenOrCreate, FileAccess.ReadWrite);
long Id =;//解析短網址得到的真實ID
long Left = 0;
long Right = (long)(Index.Length / 30) - 1;
long Middle = -1;
while (Left <= Right)
{
Middle = (long)(Math.Floor((double)((Right + Left) / 2)));
if (Middle < 0) break;
Index.Position = Middle * 30;
Index.Read(buff, 0, 8);
long val = BitConverter.ToInt64(buff, 0);
if (val == Id) break;
if (val < Id)
{
Left = Middle + 1;
}
else
{
Right = Middle - 1;
}
}
Index.Close();
二分法查找的核心是不斷移動指針,讀取中間的8字節,轉換為數字後再與目標ID比較的過程。這是一個非常高速的算法,如果有接近43億條短網址記 錄,查找某一個ID,最多只需要移動32次指針上面的while循環32次)就能找到結果,因為2^32=4294967296。
用二分法查找是因為前面使用了隨機遞增步長,如果遞增步長設為1,則二分法可免,直接從 ID*30 就能一次性精准定位到索引文件中的位置。
下面是完整的代碼,封裝了一個ShortenUrl類:
using System;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
/// <summary>
/// ShortenUrl 的摘要說明
/// </summary>
public class ShortenUrl
{
const string Seq = "s9LFkgy5RovixI1aOf8UhdY3r4DMplQZJXPqebE0WSjBn7wVzmN2Gc6THCAKut";
private static string DataFile
{
get { return HttpContext.Current.Server.MapPath("/Url.db"); }
}
private static string IndexFile
{
get { return HttpContext.Current.Server.MapPath("/Url.idx"); }
}
/// <summary>
/// 批量添加網址,按順序返回Key。如果輸入的一組網址中有不合法的元素,則返回數組的相同位置下標)的元素將為null。
/// </summary>
/// <param name="Url"></param>
/// <returns></returns>
public static string[] AddUrl(string[] Url)
{
FileStream Index = new FileStream(IndexFile, FileMode.OpenOrCreate, FileAccess.ReadWrite);
FileStream Data = new FileStream(DataFile, FileMode.Append, FileAccess.Write);
Data.Position = Data.Length;
DateTime Now = DateTime.Now;
byte[] dt = BitConverter.GetBytes(Now.ToBinary());
int _Hits = 0;
byte[] Hits = BitConverter.GetBytes(_Hits);
string[] ResultKey = new string[Url.Length];
int seekSeek = unchecked((int)Now.Ticks);
Random seekRand = new Random(seekSeek);
string Host = HttpContext.Current.Request.Url.Host.ToLower();
byte[] Status = BitConverter.GetBytes(true);
//index: ID(8) + Begin(8) + Length(2) + Hits(4) + DateTime(8) = 30
for (int i = 0; i < Url.Length && i<1000; i++)
{
if (Url[i].ToLower().Contains(Host) || Url[i].Length ==0 || Url[i].Length > 4096) continue;
long Begin = Data.Position;
byte[] UrlData = Encoding.UTF8.GetBytes(Url[i]);
Data.Write(UrlData, 0, UrlData.Length);
byte[] buff = new byte[8];
long Last;
if (Index.Length >= 30) //讀取上一條記錄的ID
{
Index.Position = Index.Length - 30;
Index.Read(buff, 0, 8);
Index.Position += 22;
Last = BitConverter.ToInt64(buff, 0);
}
else
{
Last = 1000000; //起步ID,如果太小,生成的短網址會太短。
Index.Position = 0;
}
long RandKey = Last + (long)GetRnd(seekRand);
byte[] BeginData = BitConverter.GetBytes(Begin);
byte[] LengthData = BitConverter.GetBytes((Int16)(UrlData.Length));
byte[] RandKeyData = BitConverter.GetBytes(RandKey);
Index.Write(RandKeyData, 0, 8);
Index.Write(BeginData, 0, 8);
Index.Write(LengthData, 0, 2);
Index.Write(Hits, 0, Hits.Length);
Index.Write(dt, 0, dt.Length);
ResultKey[i] = Mixup(RandKey);
}
Data.Close();
Index.Close();
return ResultKey;
}
/// <summary>
/// 按順序批量解析Key,返回一組長網址。
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
public static string[] ParseUrl(string[] Key)
{
FileStream Index = new FileStream(IndexFile, FileMode.OpenOrCreate, FileAccess.ReadWrite);
FileStream Data = new FileStream(DataFile, FileMode.Open, FileAccess.Read);
byte[] buff = new byte[8];
long[] Ids = Key.Select(n => UnMixup(n)).ToArray();
string[] Result = new string[Ids.Length];
long _Right = (long)(Index.Length / 30) - 1;
for (int j = 0; j < Ids.Length; j++)
{
long Id = Ids[j];
long Left = 0;
long Right = _Right;
long Middle = -1;
while (Left <= Right)
{
Middle = (long)(Math.Floor((double)((Right + Left) / 2)));
if (Middle < 0) break;
Index.Position = Middle * 30;
Index.Read(buff, 0, 8);
long val = BitConverter.ToInt64(buff, 0);
if (val == Id) break;
if (val < Id)
{
Left = Middle + 1;
}
else
{
Right = Middle - 1;
}
}
string Url = null;
if (Middle != -1)
{
Index.Position = Middle * 30 + 8; //跳過ID
Index.Read(buff, 0, buff.Length);
long Begin = BitConverter.ToInt64(buff, 0);
Index.Read(buff, 0, buff.Length);
Int16 Length = BitConverter.ToInt16(buff, 0);
byte[] UrlTxt = new byte[Length];
Data.Position = Begin;
Data.Read(UrlTxt, 0, UrlTxt.Length);
int Hits = BitConverter.ToInt32(buff, 2);//跳過2字節的Length
byte[] NewHits = BitConverter.GetBytes(Hits + 1);//解析次數遞增, 4字節
Index.Position -= 6;//指針撤回到Length之後
Index.Write(NewHits, 0, NewHits.Length);//覆蓋老的Hits
Url = Encoding.UTF8.GetString(UrlTxt);
}
Result[j] = Url;
}
Data.Close();
Index.Close();
return Result;
}
/// <summary>
/// 混淆id為字符串
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Mixup(long id)
{
string Key = Convert(id);
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return NewKey;
}
/// <summary>
/// 解開混淆字符串
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
private static long UnMixup(string Key)
{
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
x = Len - x;
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return Convert(NewKey);
}
/// <summary>
/// 10進制轉換為62進制
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Convert(long id)
{
if (id < 62)
{
return Seq[(int)id].ToString();
}
int y = (int)(id % 62);
long x = (long)(id / 62);
return Convert(x) + Seq[y];
}
/// <summary>
/// 將62進制轉為10進制
/// </summary>
/// <param name="Num"></param>
/// <returns></returns>
private static long Convert(string Num)
{
long v = 0;
int Len = Num.Length;
for (int i = Len - 1; i >= 0; i--)
{
int t = Seq.IndexOf(Num[i]);
double s = (Len - i) - 1;
long m = (long)(Math.Pow(62, s) * t);
v += m;
}
return v;
}
/// <summary>
/// 生成隨機的0-9a-zA-Z字符串
/// </summary>
/// <returns></returns>
public static string GenerateKeys()
{
string[] Chars = "0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z".Split(',');
int SeekSeek = unchecked((int)DateTime.Now.Ticks);
Random SeekRand = new Random(SeekSeek);
for (int i = 0; i < 100000; i++)
{
int r = SeekRand.Next(1, Chars.Length);
string f = Chars[0];
Chars[0] = Chars[r - 1];
Chars[r - 1] = f;
}
return string.Join("", Chars);
}
/// <summary>
/// 返回隨機遞增步長
/// </summary>
/// <param name="SeekRand"></param>
/// <returns></returns>
private static Int16 GetRnd(Random SeekRand)
{
Int16 Step = (Int16)SeekRand.Next(1, 11);
return Step;
}
}
本方案的優點:
把10進制的ID轉換為62進制的字符,6位數的62進制字符容量為 62^6約為568億,如果每次隨機遞增值為1~10取平均值為5),6位字符的容量仍然能容納113.6億條!這個數據已經遠遠大於一般的數據庫承受 能力。由於每次提交長網址采用Append方式寫入,因此寫入性能也不會差。在解析短網址時由於采用二分法查找,僅移動文件指針與讀取8字節的緩存,性能 上依然非常優秀。
缺點:在高並發的情況下,可能會出現文件打開失敗等IO異常,如果改用單線程的Node.js來實現,或許可以杜絕這種情況。