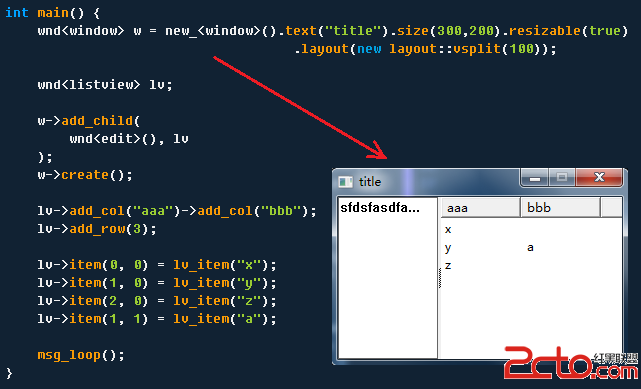
0. 前言 你是否也和我一樣是一個業余c
題目:編寫程序實現一個猜數字游戲:系統隨機生成一個10
圖論3 二分圖匹配,圖論二分圖匹配可以先在這裡學學http:
玩了sample裡面的cocos2d-html
一.使用#define宏應注意的問題 1.使用宏定義表
在過去的學習中,我們始終接觸的單個類的繼承,但是在現