List封裝了鏈表,Vector封裝了數組, list和vector得最主要的區別在於vector使用連續內存存儲的,他支持[]運算符,而list是以鏈表形式實現的,不支持[]。
Vector對於隨機訪問的速度很快,但是對於插入尤其是在頭部插入元素速度很慢,在尾部插入速度很快。List對於隨機訪問速度慢得多,因為可能要遍歷整個鏈表才能做到,但是對於插入就快的多了,不需要拷貝和移動數據,只需要改變指針的指向就可以了。另外對於新添加的元素,Vector有一套算法,而List可以任意加入。
Map,Set屬於標准關聯容器,使用了非常高效的平衡檢索二叉樹:紅黑樹,他的插入刪除效率比其他序列容器高是因為不需要做內存拷貝和內存移動,而直接替換指向節點的指針即可。
Set和Vector的區別在於Set不包含重復的數據。Set和Map的區別在於Set只含有Key,而Map有一個Key和Key所對應的Value兩個元素。
Map和Hash_Map的區別是Hash_Map使用了Hash算法來加快查找過程,但是需要更多的內存來存放這些Hash桶元素,因此可以算得上是采用空間來換取時間策略。
1 vector
向量 相當於一個數組#include <vector>
vector屬於std命名域的,因此需要通過命名限定,如下完成你的代碼:
using std::vector; vector<int> v;
或者連在一起,使用全名:
std::vector<int> v;
建議使用全局的命名域方式:
using namespace std;
1.vector的聲明
vector<ElemType> c; 創建一個空的vector
vector<ElemType> c1(c2); 創建一個vector c1,並用c2去初始化c1
vector<ElemType> c(n) ; 創建一個含有n個ElemType類型數據的vector;
vector<ElemType> c(n,elem); 創建一個含有n個ElemType類型數據的vector,並全部初始化為elem;
c.~vector<ElemType>(); 銷毀所有數據,釋放資源;
2.vector容器中常用的函數。(c為一個容器對象)
c.push_back(elem); 在容器最後位置添加一個元素elem
c.pop_back(); 刪除容器最後位置處的元素
c.at(index); 返回指定index位置處的元素
c.begin(); 返回指向容器最開始位置數據的指針
c.end(); 返回指向容器最後一個數據單元的指針+1
c.front(); 返回容器最開始單元數據的引用
c.back(); 返回容器最後一個數據的引用
c.max_size(); 返回容器的最大容量
c.size(); 返回當前容器中實際存放元素的個數
c.capacity(); 同c.size()
c.resize(); 重新設置vector的容量
c.reserve(); 同c.resize()
c.erase(p); 刪除指針p指向位置的數據,返回下指向下一個數據位置的指針(迭代器)
c.erase(begin,end) 刪除begin,end區間的數據,返回指向下一個數據位置的指針(迭代器)
c.clear(); 清除所有數據
c.rbegin(); 將vector反轉後的開始指針返回(其實就是原來的end-1)
c.rend(); 將vector反轉後的結束指針返回(其實就是原來的begin-1)
c.empty(); 判斷容器是否為空,若為空返回true,否則返回false
c1.swap(c2); 交換兩個容器中的數據
c.insert(p,elem); 在指針p指向的位置插入數據elem,返回指向elem位置的指針
c.insert(p,n,elem); 在位置p插入n個elem數據,無返回值
c.insert(p,begin,end) 在位置p插入在區間[begin,end)的數據,無返回值
3.vector中的操作
operator[] 如: c.[i];
同at()函數的作用相同,即取容器中的數據。
在上大致講述了vector類中所含有的函數和操作,下面繼續討論如何使用vector容器;
1.數據的輸入和刪除。push_back()與pop_back()

2.元素的訪問
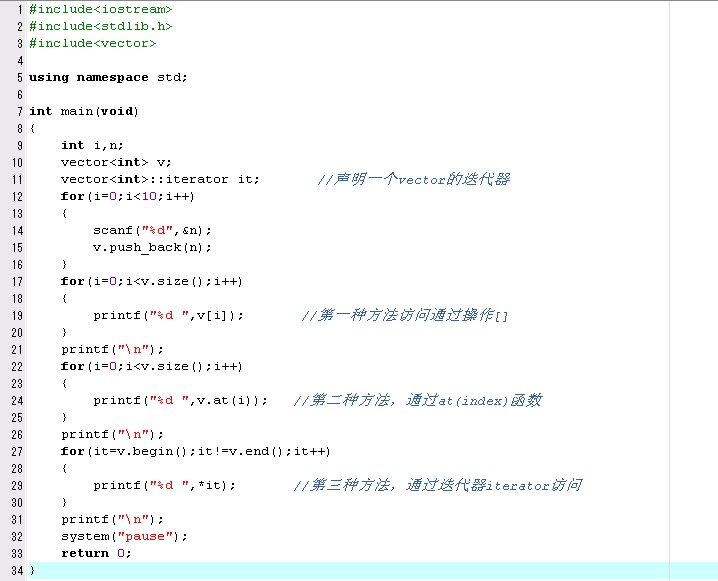
3.排序和查詢
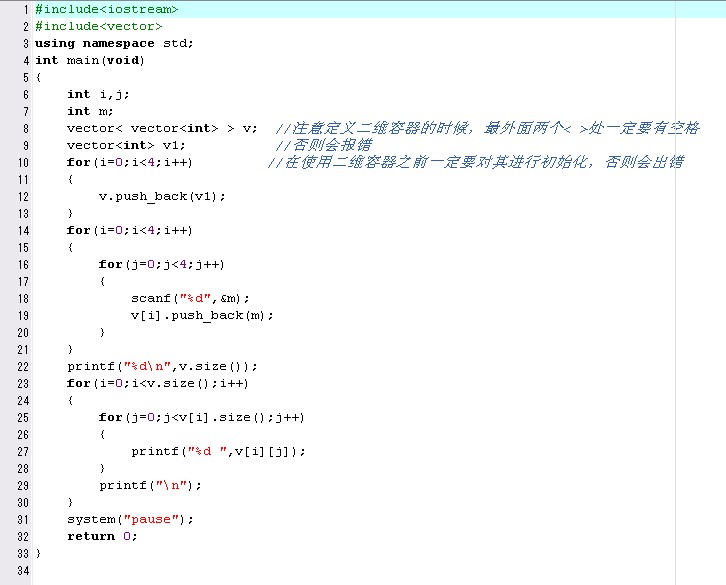
4.二維容器
#include <iostream>
#include <list>
#include <numeric>
#include <algorithm>
using namespace std;
//創建一個list容器的實例LISTINT
typedef list<int> LISTINT;
//創建一個list容器的實例LISTCHAR
typedef list<char> LISTCHAR;
void main(void)
{
//--------------------------
//用list容器處理整型數據
//--------------------------
//用LISTINT創建一個名為listOne的list對象
LISTINT listOne;
//聲明i為迭代器
LISTINT::iterator i;
//從前面向listOne容器中添加數據
listOne.push_front (2);
listOne.push_front (1);
//從後面向listOne容器中添加數據
listOne.push_back (3);
listOne.push_back (4);
//從前向後顯示listOne中的數據
cout<<"listOne.begin()--- listOne.end():"<<endl;
for (i = listOne.begin(); i != listOne.end(); ++i)
cout << *i << " ";
cout << endl;
//從後向後顯示listOne中的數據
LISTINT::reverse_iterator ir;
cout<<"listOne.rbegin()---listOne.rend():"<<endl;
for (ir =listOne.rbegin(); ir!=listOne.rend();ir++) {
cout << *ir << " ";
}
cout << endl;
//使用STL的accumulate(累加)算法
int result = accumulate(listOne.begin(), listOne.end(),0);
cout<<"Sum="<<result<<endl;
cout<<"------------------"<<endl;
//--------------------------
//用list容器處理字符型數據
//--------------------------
//用LISTCHAR創建一個名為listOne的list對象
LISTCHAR listTwo;
//聲明i為迭代器
LISTCHAR::iterator j;
//從前面向listTwo容器中添加數據
listTwo.push_front ('A');
listTwo.push_front ('B');
//從後面向listTwo容器中添加數據
listTwo.push_back ('x');
listTwo.push_back ('y');
//從前向後顯示listTwo中的數據
cout<<"listTwo.begin()---listTwo.end():"<<endl;
for (j = listTwo.begin(); j != listTwo.end(); ++j)
cout << char(*j) << " ";
cout << endl;
//使用STL的max_element算法求listTwo中的最大元素並顯示
j=max_element(listTwo.begin(),listTwo.end());
cout << "The maximum element in listTwo is: "<<char(*j)<<endl;
}
#include <iostream>
#include <list>
using namespace std;
typedef list<int> INTLIST;
//從前向後顯示list隊列的全部元素
void put_list(INTLISTlist, char *name)
{
INTLIST::iterator plist;
cout << "The contents of " << name << " : ";
for(plist = list.begin(); plist != list.end(); plist++)
cout << *plist << " ";
cout<<endl;
}
//測試list容器的功能
void main(void)
{
//list1對象初始為空
INTLIST list1;
//list2對象最初有10個值為6的元素
INTLIST list2(10,6);
//list3對象最初有3個值為6的元素
INTLIST list3(list2.begin(),--list2.end());
//聲明一個名為i的雙向迭代器
INTLIST::iterator i;
//從前向後顯示各list對象的元素
put_list(list1,"list1");
put_list(list2,"list2");
put_list(list3,"list3");
//從list1序列後面添加兩個元素
list1.push_back(2);
list1.push_back(4);
cout<<"list1.push_back(2) andlist1.push_back(4):"<<endl;
put_list(list1,"list1");
//從list1序列前面添加兩個元素
list1.push_front(5);
list1.push_front(7);
cout<<"list1.push_front(5) andlist1.push_front(7):"<<endl;
put_list(list1,"list1");
//在list1序列中間插入數據
list1.insert(++list1.begin(),3,9);
cout<<"list1.insert(list1.begin()+1,3,9):"<<endl;
put_list(list1,"list1");
//測試引用類函數
cout<<"list1.front()="<<list1.front()<<endl;
cout<<"list1.back()="<<list1.back()<<endl;
//從list1序列的前後各移去一個元素
list1.pop_front();
list1.pop_back();
cout<<"list1.pop_front() andlist1.pop_back():"<<endl;
put_list(list1,"list1");
//清除list1中的第2個元素
list1.erase(++list1.begin());
cout<<"list1.erase(++list1.begin()):"<<endl;
put_list(list1,"list1");
//對list2賦值並顯示
list2.assign(8,1);
cout<<"list2.assign(8,1):"<<endl;
put_list(list2,"list2");
//顯示序列的狀態信息
cout<<"list1.max_size(): "<<list1.max_size()<<endl;
cout<<"list1.size(): "<<list1.size()<<endl;
cout<<"list1.empty(): "<<list1.empty()<<endl;
//list序列容器的運算
put_list(list1,"list1");
put_list(list3,"list3");
cout<<"list1>list3: "<<(list1>list3)<<endl;
cout<<"list1<list3: "<<(list1<list3)<<endl;
//對list1容器排序
list1.sort();
put_list(list1,"list1");
//結合處理
list1.splice(++list1.begin(),list3);
put_list(list1,"list1");
put_list(list3,"list3");
}
 #include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main()
#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main()

 {
{ //定義map對象,當前沒有任何元素 map<string,float> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m["Jack"] = 98.5 ; m["Bomi"] = 96.0 ; m["Kate"] = 97.5 ; //先前遍歷元素 map<string,float> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++)
//定義map對象,當前沒有任何元素 map<string,float> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m["Jack"] = 98.5 ; m["Bomi"] = 96.0 ; m["Kate"] = 97.5 ; //先前遍歷元素 map<string,float> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) { cout << (*it).first << " : " << (*it).second << endl ;
{ cout << (*it).first << " : " << (*it).second << endl ; } return 0 ;
} return 0 ;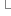 }
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; //刪除鍵值為28的元素 m.erase(28) ; //向前遍歷元素 map<int, char> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) { //輸出鍵值與映照數據 cout << (*it).first << " : " << (*it).second << endl ; } return 0 ;}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; //反向遍歷元素 map<int, char> :: reverse_iterator rit ; for( rit = m.rbegin() ; rit != m.rend() ; rit ++) { //輸入鍵值與映照數據 cout << (*rit).first << " : " << (*rit).second << endl ; } return 0 ;}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; map<int, char> :: iterator it ; it = m.find(28) ; if(it != m.end()) //搜索到該鍵值 cout << (*it).first << " : " << ( *it ).second << endl ; else cout << "not found it" << endl ; return 0 ;}
5、自定義比較函數#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;//自定義比較函數 myCompstruct myComp{ bool operator() (const int &a, const int &b) { if(a != b) return a > b ; else return a > b ; }} ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; //使用前向迭代器中序遍歷map map<int, char,myComp> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) cout << (*it).first << " : " << (*it).second << endl ; return 0 ;}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;struct Info{ string name ; float score ; //重載 “<”操作符,自定義排列規則 bool operator < (const Info &a) const { //按score由大到小排列。如果要由小到大排列,使用“>”號即可 return a.score < score ; }} ;int main(){ //定義map對象,當前沒有任何元素 map<Info, int> m ; //定義Info結構體變量 Info info ; //插入元素,按鍵值的由小到大放入黑白樹中 info.name = "Jack" ; info.score = 60 ; m[info] = 25 ; info.name = "Bomi" ; info.score = 80 ; m[info] = 10 ; info.name = "Peti" ; info.score = 66.5 ; m[info] = 30 ; //使用前向迭代器中序遍歷map map<Info,int> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) { cout << (*it).second << " : " ; cout << ((*it).first).name << " : " << ((*it).first).score << endl ; } return 0 ;}
運行結果:#include <string>#include <map>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<char, int> m ; //賦值:字符映射數字 m['0'] = 0 ; m['1'] = 1 ; m['2'] = 2 ; m['3'] = 3 ; m['4'] = 4 ; m['5'] = 5 ; m['6'] = 6 ; m['7'] = 7 ; m['8'] = 8 ; m['9'] = 9 ; /**//*上面的10條賦值語句可采用下面這個循環簡化代碼編寫 for(int j = 0 ; j < 10 ; j++) { m['0' + j] = j ; } */ string sa, sb ; sa = "6234" ; int i ; int sum = 0 ; for ( i = 0 ; i < sa.length() ; i++ ) sum += m[sa[i]] ; cout << "sum = " << sum << endl ; return 0 ;}
7、數字映照字符的map寫法#include <string>#include <map>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //賦值:字符映射數字 m[0] = '0' ; m[1] = '1' ; m[2] = '2' ; m[3] = '3' ; m[4] = '4' ; m[5] = '5' ; m[6] = '6' ; m[7] = '7' ; m[8] = '8' ; m[9] = '9' ; /**//*上面的10條賦值語句可采用下面這個循環簡化代碼編寫 for(int j = 0 ; j < 10 ; j++) { m[j] = '0' + j ; } */ int n = 7 ; string s = "The number is " ; cout << s + m[n] << endl ; return 0 ;}
運行結果:
}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; //刪除鍵值為28的元素 m.erase(28) ; //向前遍歷元素 map<int, char> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) { //輸出鍵值與映照數據 cout << (*it).first << " : " << (*it).second << endl ; } return 0 ;}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; //反向遍歷元素 map<int, char> :: reverse_iterator rit ; for( rit = m.rbegin() ; rit != m.rend() ; rit ++) { //輸入鍵值與映照數據 cout << (*rit).first << " : " << (*rit).second << endl ; } return 0 ;}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; map<int, char> :: iterator it ; it = m.find(28) ; if(it != m.end()) //搜索到該鍵值 cout << (*it).first << " : " << ( *it ).second << endl ; else cout << "not found it" << endl ; return 0 ;}
5、自定義比較函數#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;//自定義比較函數 myCompstruct myComp{ bool operator() (const int &a, const int &b) { if(a != b) return a > b ; else return a > b ; }} ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //插入元素,按鍵值的由小到大放入黑白樹中 m[25] = 'm' ; m[28] = 'k' ; m[10] = 'x' ; m[30] = 'a' ; //使用前向迭代器中序遍歷map map<int, char,myComp> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) cout << (*it).first << " : " << (*it).second << endl ; return 0 ;}
運行結果:#include <map>#include <string>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;struct Info{ string name ; float score ; //重載 “<”操作符,自定義排列規則 bool operator < (const Info &a) const { //按score由大到小排列。如果要由小到大排列,使用“>”號即可 return a.score < score ; }} ;int main(){ //定義map對象,當前沒有任何元素 map<Info, int> m ; //定義Info結構體變量 Info info ; //插入元素,按鍵值的由小到大放入黑白樹中 info.name = "Jack" ; info.score = 60 ; m[info] = 25 ; info.name = "Bomi" ; info.score = 80 ; m[info] = 10 ; info.name = "Peti" ; info.score = 66.5 ; m[info] = 30 ; //使用前向迭代器中序遍歷map map<Info,int> :: iterator it ; for(it = m.begin() ; it != m.end() ; it ++) { cout << (*it).second << " : " ; cout << ((*it).first).name << " : " << ((*it).first).score << endl ; } return 0 ;}
運行結果:#include <string>#include <map>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<char, int> m ; //賦值:字符映射數字 m['0'] = 0 ; m['1'] = 1 ; m['2'] = 2 ; m['3'] = 3 ; m['4'] = 4 ; m['5'] = 5 ; m['6'] = 6 ; m['7'] = 7 ; m['8'] = 8 ; m['9'] = 9 ; /**//*上面的10條賦值語句可采用下面這個循環簡化代碼編寫 for(int j = 0 ; j < 10 ; j++) { m['0' + j] = j ; } */ string sa, sb ; sa = "6234" ; int i ; int sum = 0 ; for ( i = 0 ; i < sa.length() ; i++ ) sum += m[sa[i]] ; cout << "sum = " << sum << endl ; return 0 ;}
7、數字映照字符的map寫法#include <string>#include <map>#include <iostream>using std :: cout ;using std :: endl ;using std :: string ;using std :: map ;int main(){ //定義map對象,當前沒有任何元素 map<int, char> m ; //賦值:字符映射數字 m[0] = '0' ; m[1] = '1' ; m[2] = '2' ; m[3] = '3' ; m[4] = '4' ; m[5] = '5' ; m[6] = '6' ; m[7] = '7' ; m[8] = '8' ; m[9] = '9' ; /**//*上面的10條賦值語句可采用下面這個循環簡化代碼編寫 for(int j = 0 ; j < 10 ; j++) { m[j] = '0' + j ; } */ int n = 7 ; string s = "The number is " ; cout << s + m[n] << endl ; return 0 ;}
運行結果:准模板庫就是類與函數模板的大集合。STL共有6種組件:容器,容器適配器,迭代器,算法,函數對象和函數適配器。
1、容器:
容器是用來存儲和組織其他對象的對象。STL容器類的模板在標准頭文件中定義。主要如下所示

①序列容器
基本的序列容器是上面圖中的前三類:

關於三者的優缺點主要是:
A:vector<T>矢量容器:可以隨機訪問容器的內容,在序列末尾添加或刪除對象,但是因為是從尾部刪除,過程非常慢,因為必須移動插入或刪除點後面的所有對象。
矢量容器的操作:(自己以前有個表,貼出來大家看看)

其中的capacity表示容量,size是當前數據個數。矢量容器如果用戶添加一個元素時容量已滿,那麼就增加當前容量的一半的內存,比如現在是500了,用戶添加進第501個,那麼他會再開拓250個,總共就750個了。所以矢量容器當你添加數據量很大的時候,需要注意這一點哦。。。
如果想用迭代器訪問元素是比較簡單的,使用迭代器輸出元素的循環類似如下:
[cpp] view plaincopy
[cpp] view plaincopy
排序矢量元素:
對矢量元素的排序可以使用<algorithm>頭文件中定義的sort()函數模板來對一個矢量容器進行排序。但是有幾點要求需要注意
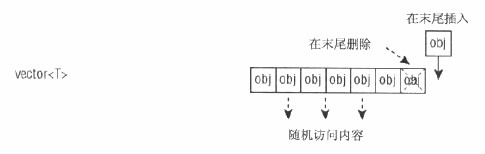
B:deque<T>容器:非常類似vector<T>,且支持相同的操作,但是它還可以在序列開頭添加和刪除。
deque<T>雙端隊列容器與矢量容器基本類似,具有相同的函數成員,但是有點不同的是它支持從兩端插入和刪除數據,所以就有了兩個函數:push_front和pop_front。並且有兩個迭代器變量
[cpp] view plaincopy
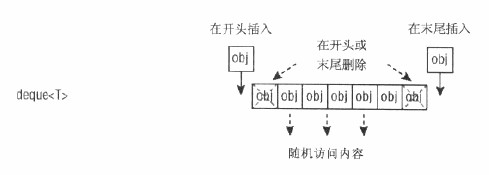
C:list<T>容器是雙向鏈表,因此可以有效的在任何位置添加和刪除。列表的缺點是不能隨機訪問內容,要想訪問內容必須在列表的內部從頭開始便利內容,或者從尾部開始。
②關聯容器
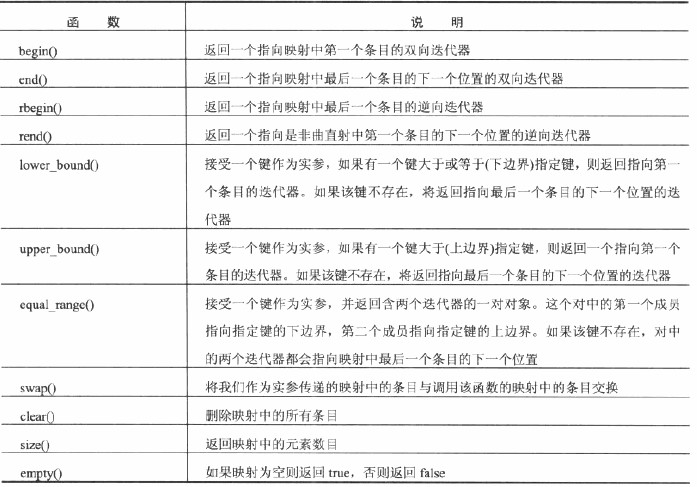
map<K, T>映射容器:K表示鍵,T表示對象,根據特定的鍵映射到對象,可以進行快速的檢索。
有關它的創建以及查找的操作作如下總結
[cpp] view plaincopy
2、容器適配器:
容器適配器是包裝了現有的STL容器類的模板類,提供了一個不同的、通常更有限制性的功能。具體如下所示

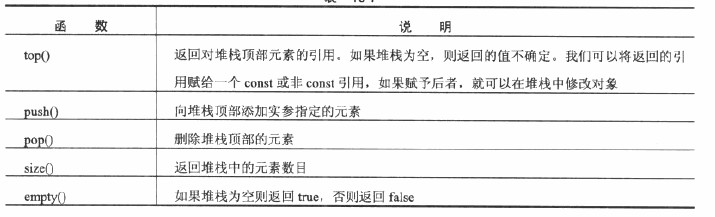
A:queue<T>隊列容器:通過適配器實現先進先出的存儲機制。我們只能向隊列的末尾添加或從開頭刪除元素。push_back() pop_front()
代碼:queue<string, list<string> > names;(這就是定義的一個適配器)是基於列表創建隊列的。適配器模板的第二個類型形參指定要使用的底層序列容器,主要的操作如下


B:priority_queue<T>優先級隊列容器:是一個隊列,它的頂部總是具有最大或最高優先級。優先級隊列容器與隊列容器一個不同點是優先級隊列容器不能訪問隊列後端的元素。
默認情況下,優先級隊列適配器類使用的是矢量容器vector<T>,當然可以選擇指定不同的序列容器作為基礎,並選擇一個備用函數對象來確定元素的優先級代碼如下
[cpp] view plaincopy
[cpp] view plaincopy
3、迭代器:
具體它的意思還沒怎麼看明白,書上介紹迭代器的行為與指針類似,這裡做個標記 ,看看後面的例子再給出具體的解釋
,看看後面的例子再給出具體的解釋
具體分為三個部分:輸入流迭代器、插入迭代器和輸出流迭代器。
 、
、

看這一章的內容看的我有點抑郁了都,摘段課本介紹的內容,還是可以幫助理解的
<iterator>頭文件中定義了迭代器的幾個模板:①流迭代器作為指向輸入或輸出流的指針,他們可以用來在流和任何使用迭代器或目的地之間傳輸數據。②插入迭代器可以將數據傳輸給一個基本序列容器。頭文件中定義了兩個流迭代器模板:istream_iterator<T>用於輸入流,ostream_iterator<T>用於輸出流。T表示從流中提取數據或寫到流中的對象的類型。頭文件還定義了三個插入模板:insert<T>, back_insert<T>和front_inset<T>。其中T也是指代序列容器中數據的類型。
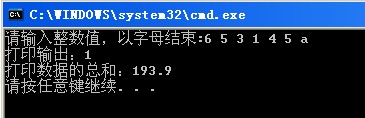
輸入流迭代器用下面的程序來說明下,可見具體注釋
[cpp] view plaincopy
輸出結果:
耽誤時間太多。以後再寫吧
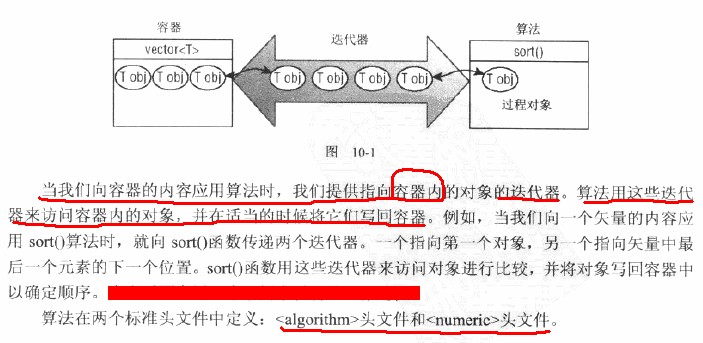
4、算法:
算法是操作迭代器提供的一組對象的STL函數模板,對對象的一個操作,可以與前面的容器迭代器結合起來看。如下圖介紹
5、函數對象:
函數對象是重載()運算符的類類型的對象。就是實現operator()()函數。
函數對象模板在<functional>頭文件中定義,必要時我們也可以定義自己的函數對象。做個標記,等有具體實例來進行進一步的解釋。
6、函數適配器:
函數適配器是允許合並函數對象以產生一個更復雜的函數對象的函數模板。
Map是STL的一個關聯容器,它提供一對一(其中第一個可以稱為關鍵字,每個關鍵字只能在map中出現一次,第二個可能稱為該關鍵字的值)的數據處理能力,由於這個特性,它完成有可能在我們處理一對一數據的時候,在編程上提供快速通道。這裡說下map內部數據的組織,map內部自建一顆紅黑樹(一種非嚴格意義上的平衡二叉樹),這顆樹具有對數據自動排序的功能,所以在map內部所有的數據都是有序的,後邊我們會見識到有序的好處。
下面舉例說明什麼是一對一的數據映射。比如一個班級中,每個學生的學號跟他的姓名就存在著一一映射的關系,這個模型用map可能輕易描述,很明顯學號用int描述,姓名用字符串描述(本篇文章中不用char *來描述字符串,而是采用STL中string來描述),下面給出map描述代碼:
Map<int, string> mapStudent;
1. map的構造函數
map共提供了6個構造函數,這塊涉及到內存分配器這些東西,略過不表,在下面我們將接觸到一些map的構造方法,這裡要說下的就是,我們通常用如下方法構造一個map:
Map<int, string> mapStudent;
2. 數據的插入
在構造map容器後,我們就可以往裡面插入數據了。這裡講三種插入數據的方法:
第一種:用insert函數插入pair數據,下面舉例說明(以下代碼雖然是隨手寫的,應該可以在VC和GCC下編譯通過,大家可以運行下看什麼效果,在VC下請加入這條語句,屏蔽4786警告 #pragma warning (disable:4786) )
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
第二種:用insert函數插入value_type數據,下面舉例說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(map<int, string>::value_type (1, “student_one”));
mapStudent.insert(map<int, string>::value_type (2, “student_two”));
mapStudent.insert(map<int, string>::value_type (3, “student_three”));
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
第三種:用數組方式插入數據,下面舉例說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent[1] = “student_one”;
mapStudent[2] = “student_two”;
mapStudent[3] = “student_three”;
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
以上三種用法,雖然都可以實現數據的插入,但是它們是有區別的,當然了第一種和第二種在效果上是完成一樣的,用insert函數插入數據,在數據的插入上涉及到集合的唯一性這個概念,即當map中有這個關鍵字時,insert操作是插入數據不了的,但是用數組方式就不同了,它可以覆蓋以前該關鍵字對應的值,用程序說明
mapStudent.insert(map<int, string>::value_type (1, “student_one”));
mapStudent.insert(map<int, string>::value_type (1, “student_two”));
上面這兩條語句執行後,map中1這個關鍵字對應的值是“student_one”,第二條語句並沒有生效,那麼這就涉及到我們怎麼知道insert語句是否插入成功的問題了,可以用pair來獲得是否插入成功,程序如下
Pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (1, “student_one”));
我們通過pair的第二個變量來知道是否插入成功,它的第一個變量返回的是一個map的迭代器,如果插入成功的話Insert_Pair.second應該是true的,否則為false。
下面給出完成代碼,演示插入成功與否問題
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
Pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(pair<int, string>(1, “student_one”));
If(Insert_Pair.second == true)
{
Cout<<”Insert Successfully”<<endl;
}
Else
{
Cout<<”Insert Failure”<<endl;
}
Insert_Pair = mapStudent.insert(pair<int, string>(1, “student_two”));
If(Insert_Pair.second == true)
{
Cout<<”Insert Successfully”<<endl;
}
Else
{
Cout<<”Insert Failure”<<endl;
}
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
大家可以用如下程序,看下用數組插入在數據覆蓋上的效果
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent[1] = “student_one”;
mapStudent[1] = “student_two”;
mapStudent[2] = “student_three”;
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
3. map的大小
在往map裡面插入了數據,我們怎麼知道當前已經插入了多少數據呢,可以用size函數,用法如下:
Int nSize = mapStudent.size();
4. 數據的遍歷
這裡也提供三種方法,對map進行遍歷
第一種:應用前向迭代器,上面舉例程序中到處都是了,略過不表
第二種:應用反相迭代器,下面舉例說明,要體會效果,請自個動手運行程序
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
map<int, string>::reverse_iterator iter;
for(iter = mapStudent.rbegin(); iter != mapStudent.rend(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
第三種:用數組方式,程序說明如下
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
int nSize = mapStudent.size()
//此處有誤,應該是 for(int nIndex = 1; nIndex <= nSize; nIndex++)
//by rainfish
for(int nIndex = 0; nIndex < nSize; nIndex++)
{
Cout<<mapStudent[nIndex]<<end;
}
}
5. 數據的查找(包括判定這個關鍵字是否在map中出現)
在這裡我們將體會,map在數據插入時保證有序的好處。
要判定一個數據(關鍵字)是否在map中出現的方法比較多,這裡標題雖然是數據的查找,在這裡將穿插著大量的map基本用法。
這裡給出三種數據查找方法
第一種:用count函數來判定關鍵字是否出現,其缺點是無法定位數據出現位置,由於map的特性,一對一的映射關系,就決定了count函數的返回值只有兩個,要麼是0,要麼是1,出現的情況,當然是返回1了
第二種:用find函數來定位數據出現位置,它返回的一個迭代器,當數據出現時,它返回數據所在位置的迭代器,如果map中沒有要查找的數據,它返回的迭代器等於end函數返回的迭代器,程序說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
map<int, string>::iterator iter;
iter = mapStudent.find(1);
if(iter != mapStudent.end())
{
Cout<<”Find, the value is ”<<iter->second<<endl;
}
Else
{
Cout<<”Do not Find”<<endl;
}
}
第三種:這個方法用來判定數據是否出現,是顯得笨了點,但是,我打算在這裡講解
Lower_bound函數用法,這個函數用來返回要查找關鍵字的下界(是一個迭代器)
Upper_bound函數用法,這個函數用來返回要查找關鍵字的上界(是一個迭代器)
例如:map中已經插入了1,2,3,4的話,如果lower_bound(2)的話,返回的2,而upper-bound(2)的話,返回的就是3
Equal_range函數返回一個pair,pair裡面第一個變量是Lower_bound返回的迭代器,pair裡面第二個迭代器是Upper_bound返回的迭代器,如果這兩個迭代器相等的話,則說明map中不出現這個關鍵字,程序說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent[1] = “student_one”;
mapStudent[3] = “student_three”;
mapStudent[5] = “student_five”;
map<int, string>::iterator iter;
iter = mapStudent.lower_bound(2);
{
//返回的是下界3的迭代器
Cout<<iter->second<<endl;
}
iter = mapStudent.lower_bound(3);
{
//返回的是下界3的迭代器
Cout<<iter->second<<endl;
}
iter = mapStudent.upper_bound(2);
{
//返回的是上界3的迭代器
Cout<<iter->second<<endl;
}
iter = mapStudent.upper_bound(3);
{
//返回的是上界5的迭代器
Cout<<iter->second<<endl;
}
Pair<map<int, string>::iterator, map<int, string>::iterator> mapPair;
mapPair = mapStudent.equal_range(2);
if(mapPair.first == mapPair.second)
{
cout<<”Do not Find”<<endl;
}
Else
{
Cout<<”Find”<<endl;
}
mapPair = mapStudent.equal_range(3);
if(mapPair.first == mapPair.second)
{
cout<<”Do not Find”<<endl;
}
Else
{
Cout<<”Find”<<endl;
}
}
6. 數據的清空與判空
清空map中的數據可以用clear()函數,判定map中是否有數據可以用empty()函數,它返回true則說明是空map
7. 數據的刪除
這裡要用到erase函數,它有三個重載了的函數,下面在例子中詳細說明它們的用法
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
//如果你要演示輸出效果,請選擇以下的一種,你看到的效果會比較好
//如果要刪除1,用迭代器刪除
map<int, string>::iterator iter;
iter = mapStudent.find(1);
mapStudent.erase(iter);
//如果要刪除1,用關鍵字刪除
Int n = mapStudent.erase(1);//如果刪除了會返回1,否則返回0
//用迭代器,成片的刪除
//一下代碼把整個map清空
mapStudent.earse(mapStudent.begin(), mapStudent.end());
//成片刪除要注意的是,也是STL的特性,刪除區間是一個前閉後開的集合
//自個加上遍歷代碼,打印輸出吧
}
8. 其他一些函數用法
這裡有swap,key_comp,value_comp,get_allocator等函數,感覺到這些函數在編程用的不是很多,略過不表,有興趣的話可以自個研究
9. 排序
這裡要講的是一點比較高深的用法了,排序問題,STL中默認是采用小於號來排序的,以上代碼在排序上是不存在任何問題的,因為上面的關鍵字是int型,它本身支持小於號運算,在一些特殊情況,比如關鍵字是一個結構體,涉及到排序就會出現問題,因為它沒有小於號操作,insert等函數在編譯的時候過不去,下面給出兩個方法解決這個問題
第一種:小於號重載,程序舉例
#include <map>
#include <string>
Using namespace std;
Typedef struct tagStudentInfo
{
Int nID;
String strName;
}StudentInfo, *PStudentInfo; //學生信息
Int main()
{
int nSize;
//用學生信息映射分數
map<StudentInfo, int>mapStudent;
map<StudentInfo, int>::iterator iter;
StudentInfo studentInfo;
studentInfo.nID = 1;
studentInfo.strName = “student_one”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 90));
studentInfo.nID = 2;
studentInfo.strName = “student_two”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 80));
for (iter=mapStudent.begin(); iter!=mapStudent.end(); iter++)
cout<<iter->first.nID<<endl<<iter->first.strName<<endl<<iter->second<<endl;
}
以上程序是無法編譯通過的,只要重載小於號,就OK了,如下:
Typedef struct tagStudentInfo
{
Int nID;
String strName;
Bool operator < (tagStudentInfo const& _A) const
{
//這個函數指定排序策略,按nID排序,如果nID相等的話,按strName排序
If(nID < _A.nID) return true;
If(nID == _A.nID) return strName.compare(_A.strName) < 0;
Return false;
}
}StudentInfo, *PStudentInfo; //學生信息
第二種:仿函數的應用,這個時候結構體中沒有直接的小於號重載,程序說明
#include <map>
#include <string>
Using namespace std;
Typedef struct tagStudentInfo
{
Int nID;
String strName;
}StudentInfo, *PStudentInfo; //學生信息
Classs sort
{
Public:
Bool operator() (StudentInfo const &_A, StudentInfo const &_B) const
{
If(_A.nID < _B.nID) return true;
If(_A.nID == _B.nID) return _A.strName.compare(_B.strName) < 0;
Return false;
}
};
Int main()
{
//用學生信息映射分數
Map<StudentInfo, int, sort>mapStudent;
StudentInfo studentInfo;
studentInfo.nID = 1;
studentInfo.strName = “student_one”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 90));
studentInfo.nID = 2;
studentInfo.strName = “student_two”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 80));
}
10. 另外
由於STL是一個統一的整體,map的很多用法都和STL中其它的東西結合在一起,比如在排序上,這裡默認用的是小於號,即less<>,如果要從大到小排序呢,這裡涉及到的東西很多,在此無法一一加以說明。
還要說明的是,map中由於它內部有序,由紅黑樹保證,因此很多函數執行的時間復雜度都是log2N的,如果用map函數可以實現的功能,而STL Algorithm也可以完成該功能,建議用map自帶函數,效率高一些。