與其他函數不同,構造函數除了有名字,參數列表和函數體之外,還可以有初始化列表。初始化列表以冒號開頭,後跟一系列以逗號分隔的初始化字段。在C++中,struct和class唯一的區別就是struct的所有成員默認都是public的,所以如果不考慮成員的可訪問性,這兩者是沒有區別的,而這裡我們不考慮訪問性的問題,所以下面的代碼都以struct來演示。
struct foo
{
string name ;
int id ;
foo(string s, int i):name(s), id(i){} ; // 初始化列表
};
構造函數的執行可以分成兩個階段,初始化階段和計算階段,初始化階段先於計算階段。
所有類類型(class type)的成員都會在初始化階段初始化,即使該成員沒有出現在構造函數的初始化列表中。
一般用於執行構造函數體內的賦值操作,下面的代碼定義兩個結構體,其中Test1有構造函數,拷貝構造函數及賦值運算符,為的是方便查看結果。Test2是個測試類,它以Test1的對象為成員,我們看一下Test2的構造函數是怎麼樣執行的。
struct Test1
{
Test1() // 無參構造函數
{
cout << Construct Test1 << endl ;
}
Test1(const Test1& t1) // 拷貝構造函數
{
cout << Copy constructor for Test1 << endl ;
this->a = t1.a ;
}
Test1& operator = (const Test1& t1) // 賦值運算符
{
cout << assignment for Test1 << endl ;
this->a = t1.a ;
return *this;
}
int a ;
};
struct Test2
{
Test1 test1 ;
Test2(Test1 &t1)
{
test1 = t1 ;
}
};
調用代碼
Test1 t1 ; Test2 t2(t1) ;
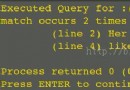
輸出

解釋一下,第一行輸出結果對應調用代碼中第一行,構造一個Test1對象。第二行輸出對應Test2構造函數中的代碼,用默認的構造函數初始化對象test1,這就是所謂的初始化階段。第三行輸出對應Test1的賦值運算符,對test1執行賦值操作,這就是所謂的計算階段。
初始化類的成員有兩種方式,一是使用初始化列表,二是在構造函數體內進行賦值操作。使用初始化列表主要是基於性能問題,對於內置類型,如int, float等,使用初始化類表和在構造函數體內初始化差別不是很大,但是對於類類型來說,最好使用初始化列表,為什麼呢?由上面的測試可知,使用初始化列表少了一次調用默認構造函數的過程,這對於數據密集型的類來說,是非常高效的。同樣看上面的例子,我們使用初始化列表來實現Test2的構造函數
struct Test2
{
Test1 test1 ;
Test2(Test1 &t1):test1(t1){}
}
使用同樣的調用代碼,輸出結果如下。

第一行輸出對應調用代碼的第一行。第二行輸出對應Test2的初始化列表,直接調用拷貝構造函數初始化test1,省去了調用默認構造函數的過程。所以一個好的原則是,能使用初始化列表的時候盡量使用初始化列表。
除了性能問題之外,有些時場合初始化列表是不可或缺的,以下幾種情況時必須使用初始化列表
對於沒有默認構造函數的類,我們看一個例子。
struct Test1
{
Test1(int a):i(a){}
int i ;
};
struct Test2
{
Test1 test1 ;
Test2(Test1 &t1)
{
test1 = t1 ;
}
};
以上代碼無法通過編譯,因為Test2的構造函數中test1 = t1這一行實際上分成兩步執行。
1. 調用Test1的默認構造函數來初始化test1
2. 調用Test1的賦值運算符給test1賦值
但是由於Test1沒有默認的構造函數,所謂第一步無法執行,故而編譯錯誤。正確的代碼如下,使用初始化列表代替賦值操作。
struct Test2
{
Test1 test1 ;
Test2(Test1 &t1):test1(t1){}
}
成員是按照他們在類中出現的順序進行初始化的,而不是按照他們在初始化列表出現的順序初始化的,看代碼。
struct foo
{
int i ;
int j ;
foo(int x):i(x), j(i){}; // ok, 先初始化i,後初始化j
};
再看下面的代碼
struct foo
{
int i ;
int j ;
foo(int x):j(x), i(j){} // i值未定義
};
這裡i的值是未定義的,雖然j在初始化列表裡面出現在i前面,但是i先於j定義,所以先初始化i,但i由j初始化,此時j尚未初始化,所以導致i的值未定義。所以,一個好的習慣是,按照成員定義的順序進行初始化。
同樣再看看下面的代碼
class Data{
public:
int i;
int j;
int k;
Data(int a):j(a),k(i),i(i)
{
}
};
這種寫法有問題,按照此寫法,只有j的值等於a的值,k和i的值都是未定義的。