引言
以前讀《C++ Primer》的時候一直有一種感覺:該書雖然是C++入門書籍,初學者讀之卻覺晦澀,越往後讀越是如此。等到稍加理解後再讀該書,頓感醍醐灌頂,茅塞頓開。究其原因,在於原作者Stanley Lippman總是會有意無意地從編譯器的角度來介紹語言的細節:對新手而言,哪裡會去關注這樣底層的實現呢?
當讀到《Inside The C++ Object Model》時,上述感覺愈發強烈,兩書之間漸進講述的細節讓人讀後大呼過瘾,也深感大師級作者筆觸間的睿智。
眾所周知,C++是一門支持多范式的語言(《Effective C++》Item1),其中最為重要,對C語言最大的變革便是面向對象的設計思想。而本書,依其簡介,探索“對象導向程序所支持的C++對象模型”下的程序行為。對於“對象導向性質之基礎實現技術”以及“各種性質背後的隱含利益交換”提供一個清楚的認識。檢驗由程序變形所帶來的效率沖擊。提供對象導向觀念和底層對象模型之間的效率測量。
關於對象
從C語言轉化到C++時,一個顯而易見的區別在於從全局數據過渡到數據封裝,那麼其布局成本(Layout Costs)如何?答案是並未增加。本文後續將講述C++在布局以及存取時間上主要的額外負擔是由virtual引起,包括:
此外還有一些多重繼承的額外負擔,除此,C++毫無理由比C慢。
C++對象模式
類的成員包括類數據成員(靜態和非靜態)和類成員函數(靜態,非靜態和虛函數)。
考慮如下簡單對象模型:
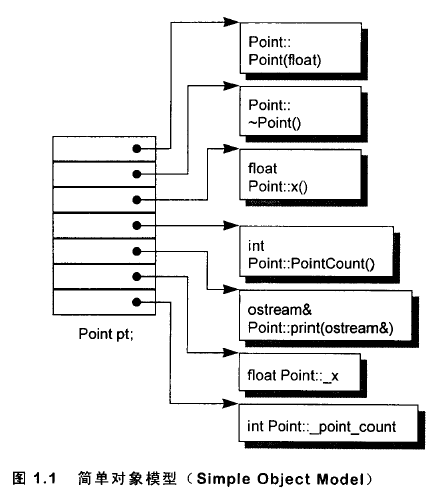
我們看到,成員本身並不在對象裡,只有指向對象的指針才在,如此可以避免成員因類型不同而導致存儲空間不同。顯然,成員以每個slot的索引值來尋址。
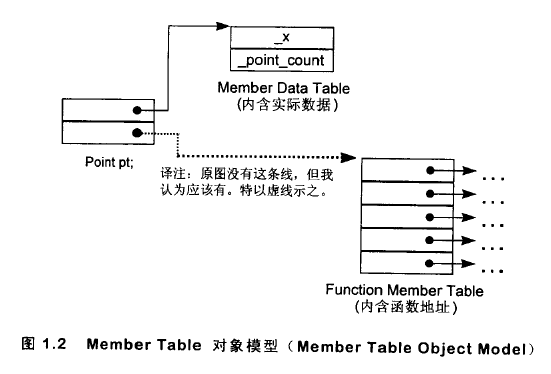
考慮表格驅動對象模型(見上中圖1.2):
該方案中,把所有成員分離放在數據成員表和成員函數表兩個表中。類對象則含有指向這兩個表的指針。
遺憾的是,以上兩種方案都沒有真正應用於C++編譯器中,但它們的設計思想,或多或少被有所繼承。
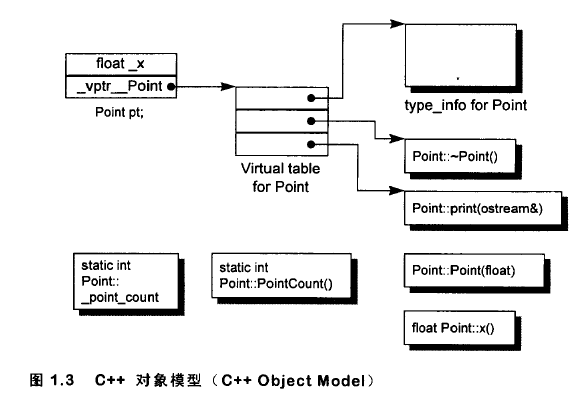
來看C++對象模型的實現(見上右圖1.3):
在該模型中,非靜態數據成員放在類對象中,靜態數據成員則放在類對象外;靜態和非靜態函數成員也放在類對象外;虛函數以下步驟支持:
該模型的優點在於空間和存取時間的效率,主要缺點在於非靜態數據成員修改時必須重新編譯。
加上繼承
在虛擬繼承的情況下,基類不管被派生多少次,都只有一個實體(subobject)。C++最初的繼承模型不運用任何間接性:基類實體的數據成員被直接放在派生類對象中。後來又引入虛基類,則通過一些間接的基類表現方法。具體實現本文不做闡述,留待後續博文。
對象的差異
C++程序設計模型直接支持三種程序設計典范:
1.程序模型:即來自C語言的部分;
2.抽象數據類型模型:即封裝與抽象;
3.面向對象模型:定義基類並派生出子類。
記住,純粹以一種典范寫程序,有利於整體行為的良好穩固。
多態
C++以下列方法支持多態:
1.隱含的轉化操作:把派生類的引用/指針轉化為基類的引用/指針;
2.虛函數機制:動態綁定;
3.dynamic_cast和typeid運算符。
那麼,需要多少內存才能表現一個類對象呢?