1 typedef unsigned char BYTE;
2 class CPageRank
3 {
4 public:
5 CPageRank(int nWebNum = 5, bool bLoadFromFile = false);
6 ~CPageRank();
7
8 int Process();
9 float *GetWeight();
10
11 private:
12 void InitGraph(bool bLoadFromFile = false);
13 void GenerateP();
14 BYTE *m_pu8Relation; //節點關系 i行j列表示j是否指向i
15 float *m_pf32P; //轉移矩陣
16
17 //緩存
18 float *m_pf32Weight0;
19 float *m_pf32Weight1;
20 int *m_pl32Out;
21 int m_nNum;
22 float m_f32DampFactor; //阻尼系數
23
24 int m_nMaxIterTime;
25 float m_f32IterErr;
26 float *m_pf32OutWeight;//輸出的最終權重
27 };
下面就是具體各個函數的實現了。
首先構造函數主要是初始化一些迭代相關變量,分配空間等,這裡把生成節點指向圖的工作也放在這裡,支持直接隨機生成和讀取二進制文件兩種方式。
1 CPageRank::CPageRank(int nWebNum, bool bLoadFromFile)
2 {
3 m_f32DampFactor = 0.85;
4 m_nMaxIterTime = 1000;
5 m_f32IterErr = 1e-6;
6
7 m_nNum = nWebNum;
8 m_pu8Relation = new BYTE[m_nNum * m_nNum];
9 m_pf32P = new float[m_nNum * m_nNum];
10 m_pf32Weight0 = new float[m_nNum];
11 m_pf32Weight1 = new float[m_nNum];
12 m_pl32Out = new int[m_nNum];//每個節點指向的節點數
13
14 InitGraph(bLoadFromFile);
15 }
析構函數自然就是釋放內存了:
1 CPageRank::~CPageRank()
2 {
3 delete []m_pl32Out;
4 delete []m_pf32P;
5 delete []m_pf32Weight0;
6 delete []m_pf32Weight1;
7 delete []m_pu8Relation;
8 }
下面就是隨機生成或讀取文件產生節點指向關系,如果隨機生成的話,會自動保存當前生成的圖,便於遇到問題時可復現調試:
1 void CPageRank::InitGraph(bool bLoadFromFile)
2 {
3 FILE *pf = NULL;
4 if(bLoadFromFile)
5 {
6 pf = fopen("map.dat", "rb");
7 if(pf)
8 {
9 fread(m_pu8Relation, sizeof(BYTE), m_nNum * m_nNum, pf);
10 fclose(pf);
11 return;
12 }
13 }
14
15 //建立隨機的節點指向圖
16 int i, j;
17 srand((unsigned)time(NULL));
18 for(i = 0; i < m_nNum; i++)
19 {
20 //指向第i個的節點
21 for(j = 0; j < m_nNum; j++)
22 {
23 m_pu8Relation[i * m_nNum + j] = rand() & 1;
24 }
25 //自己不指向自己
26 m_pu8Relation[i * m_nNum + i] = 0;
27 }
28
29 pf = fopen("map.dat", "wb");
30 if(pf)
31 {
32 fwrite(m_pu8Relation, sizeof(BYTE), m_nNum * m_nNum, pf);
33 fclose(pf);
34 }
35 }
既然已經產生了各個節點的關系了,那PageRank的核心思想就是根據關系,生成出上面的轉移矩陣P:
1 void CPageRank::GenerateP()
2 {
3 int i,j;
4 float *pf32P = NULL;
5 BYTE *pu8Relation = NULL;
6
7 //統計流入流出每個節點數
8 memset(m_pl32Out, 0, m_nNum * sizeof(int));
9 pu8Relation = m_pu8Relation;
10 for(i = 0; i < m_nNum; i++)
11 {
12 for(j = 0; j < m_nNum; j++)
13 {
14 m_pl32Out[j] += *pu8Relation;
15 pu8Relation++;
16 }
17 }
18
19 //生成轉移矩陣,每個節點的權重平均流出
20 pu8Relation = m_pu8Relation;
21 pf32P = m_pf32P;
22 for(i = 0; i < m_nNum; i++)
23 {
24 for(j = 0; j < m_nNum; j++)
25 {
26 if(m_pl32Out[j] > 0)
27 {
28 *pf32P = *pu8Relation * 1.0f / m_pl32Out[j];
29 }
30 else
31 {
32 *pf32P = 0.0f;
33 }
34 pu8Relation++;
35 pf32P++;
36 }
37 }
38
39 //考慮阻尼系數,修正轉移矩陣
40 pf32P = m_pf32P;
41 for(i = 0; i < m_nNum; i++)
42 {
43 for(j = 0; j < m_nNum; j++)
44 {
45 *pf32P = *pf32P * m_f32DampFactor;
46 pf32P++;
47 }
48 }
49 }
接下來就需要求解出各個節點的權重,process函數裡先調用GenerateP生成出P矩陣,然後采用迭代法求解,當時為了測試收斂速度,直接返回了迭代次數:
1 int CPageRank::Process()
2 {
3 int i,j,k,t;
4 float f32MaxErr = 0.0f;
5 float *pf32Org = m_pf32Weight0;
6 float *pf32New = m_pf32Weight1;
7 float f32MinWeight = (1 - m_f32DampFactor) / m_nNum;
8
9 //設置初始值,全1
10 for(i = 0; i < m_nNum; i++)
11 {
12 pf32Org[i] = 1.0f / m_nNum;//rand() * 2.0f / RAND_MAX;
13 }
14
15 //生成P矩陣
16 GenerateP();
17
18 //迭代
19 for(t = 0; t < m_nMaxIterTime; t++)
20 {
21 //開始迭代
22 f32MaxErr = 0.0f;
23 for(i = 0; i < m_nNum; i++)
24 {
25 pf32New[i] = f32MinWeight;
26 int l32Off = i * m_nNum;
27 for(j = 0; j < m_nNum; j++)
28 {
29 pf32New[i] += m_pf32P[l32Off + j] * pf32Org[j];
30 }
31
32 float f32Err = fabs(pf32New[i] - pf32Org[i]);
33 if(f32Err > f32MaxErr)
34 {
35 f32MaxErr = f32Err;
36 }
37 }
38
39 //迭代誤差足夠小,停止
40 if(f32MaxErr < m_f32IterErr)
41 {
42 break;
43 }
44
45 //交換2次迭代結果
46 float *pf32Temp = pf32Org;
47 pf32Org = pf32New;
48 pf32New = pf32Temp;
49 }
50
51 //迭代結果存在pf32New中
52 m_pf32OutWeight = pf32New;
53 return t;
54 }
最後的結果已經存在了m_pf32OutWeight中了,下面函數直接傳出結果:
1 float * CPageRank::GetWeight()
2 {
3 return m_pf32OutWeight;
4 }
這樣,整個算法就算完成了,考慮到篇幅,貼上來的代碼把opencv顯示相關的代碼去掉了,完整代碼見https://bitbucket.org/jcchen1987/mltest。
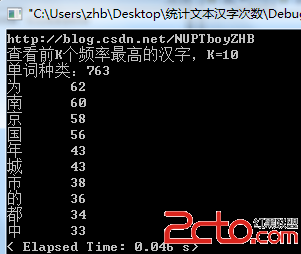
下面是結果圖,即便節點數較多時,算法收斂也比較快。