(寫於2011-07-30)
在Windows NT系列的操作系統中最常用的兩種字符集是ANSI和Unicode。ANSI是一種泛稱,每一個國家或地區的ANSI編碼都不一樣,比如在Windows XP簡體中文版中,ANSI的編碼為GBK,而在Windows XP日文版中ANSI的編碼是JIS。Unicode的全稱是Universal Multiple-Octet Coded Character Set,中文含義是“通用多八位編碼字符集”。Unicode的目標是為世界是所有的字符提供一套唯一的、統一的字符編碼,所以不管理在作保地方任何操作系統,一個確定字符的編碼都是唯一的。由於Unicode采用大於等於2個字節來儲存字符編碼,所以有可能在不同的操作系統中儲存的字節順序不一樣,可分為大端方式和小端方式。
存儲方式
以“中文”兩個漢字舉例說明,在Windows XP簡體中文版中,“中文”兩個字的ANSI/GBK和Unicode分別為:
字符
中
文
ANSI/GBK
0XD6D0
0XCEC4
Unicode
0X4E2D
0X6587
在VC中,定義字符有兩種方式:char類型和wchar_t類型。char類型采用ANSI/GBK編碼,而wchar_t采用Unicode編碼,wchar_t也是常說的寬字符型。
定義如下兩個字符串
char* str = "中文"; wchar_t* wcstr = L"中文";
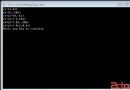
通過調試我們可以看到這兩個字符串在內存中的儲存方式。編譯後,指針str所指向的地址為0x004188CC,“中文”兩個字在內存中的表示方式為:d6 d0 ce c4,剛好是“中文”兩個字的GBK碼,從而可知,如一個字符串在VC中被定義為char*類型,那麼字符將被編為ANSI/GBK碼,如圖 1所示。
編碼
十六進制內容
ANSI
D6 D0 CE C4
Unicode
FF FE 2D 4E 87 65
Unicode big endian
FE FF 4E 2D 65 87
UTF-8
EF BB BF E4 B8 AD E6 96 87
從表中可以看出,對於選擇ANSI編碼,會采用系統默認編碼按大端方式直接儲存,對於Windows XP簡體中文版,系統默認編碼是GBK,所以文件中儲存的內容就是“中文”兩個字的的GBK編碼D6 D0 CE C4。
如果是Unicode編碼,按照規定,要在文件的開頭加上一個“ZERO WIDTH NO-BREAK SPACE”標識,可直譯為“零寬度非換行空格”,目標是標識文件是以哪一種方式來儲存Unicode碼。“中文”的Unicode碼為“4E2D 6587”常用三種方式儲存
表 2
儲存方式
字符串編碼內容
UTF-16 Little Endian (小端)
2D4E 8765
UTF-16 Big Endian (大端)
4E2D 6587
UTF-8
E4B8AD E69687
注:UTF-8是變長的,儲存一個字母要一個字節,一個漢字要三個字節;UTF-16是定長的,不管是儲存一個字母還是一個漢字都需要兩個字節,所以用UTF-16儲存字母時會造成空間浪費。
這三種儲存方式所對應的標識為
表 3
儲存方式
對應的標識
UTF-16 Little Endian (小端)
FF FE
UTF-16 Big Endian (大端)
FE FF
UTF-8
EF BB BF
所以從表 1 可知,
1、 如果選擇“Unicode”,會將字符串編譯為Unicode碼,按UTF-16小端方式儲存;
2、 如果選擇“Unicode big endian”,會將字符串編譯為Unicode碼,按UTF-16大端方式儲存;
3、 如果選擇“UTF-8”,會將字符串編譯為Unicode碼,按UTF-8方式儲存。
從上面我們也可知道,如果一個文本文件的前兩個字節是“FFFE”,那麼這個文件一定是按小端方式儲存字符的Unicode碼,第三個字節是Unicode碼的低字節,第四個字節是Unicode碼的高字節,根據這兩個高低字節就可以得出一個Unicode字符。第五個字節是第二個字符的Unicode碼的低字節,第六個字節是第二個字符的Unicode碼的高字節。
UTF-8碼是將字符的Unicode碼按一定規則存放到1~4個字節中,根據UFT-8碼也可以得出字符的Unicode碼,請別參考其他文檔。
知道字符在計算機如何編碼,如何儲存後,那麼如何將這些輸出呢?
Widows在內部維護了一塊控制台輸出緩沖區,如要要向控制台輸出字符串,只要將字符串所對應的內存區域復制到控制台緩沖區,Windows就會以默認的字符編碼將控制台緩沖區的內容輸出到控制台窗口。對於Windows XP簡體中文版,默認的字符編碼是GBK,所以Windows會以GBK碼的方式輸出控制台緩沖區的內容。要想Windows XP簡體中文版的控制台窗口能正確輸出控制緩沖區的內容,那麼必須保證復制到控制台緩沖區的字符編碼是GBK碼。
對於C語言的printf()函數和C++語言中的std::cout對象,其實都是調用系統“kernel32.dll”中的WriteConsole()函數,將字符串所對應的內存區域復制到控制台的緩沖區。
對於char*類型的字符串,C語言提供的輸出函數是printf(),對於wchar_t*類型的字符串,C語言提供的輸出函數是wprintf()。
在VC中,char*類型的字符被編譯為ANSI(GBK)碼,正好和輸出緩沖區的編碼類型一致,所以可以直接輸出。對於wchar_t*類型字符串,VC在編譯程序時,會將字符串編譯為Unicode碼,如果程序運行時,直接將字符串對應的內存區域復制到輸出緩沖區,由於字符串的編碼和控制台的默認編碼不至,控制台將Unicode碼當作GBK碼輸出到控制台時就會出現亂情況。
一個可行的辦法是先將Unicode碼轉換成GBK碼,然後再復制到控制台的輸出緩沖區,這樣就不會出現亂碼的問題。
在C語言和C++語言中輸出char*類型和wchar_t*類型的字符串
//C語言輸出char*類型的字符串(ANSI/GBK)
void cprintchar(const char* str)
{
printf("%s\n",str);
}
//C語言輸出wchar_t*類型的字符串(Unicode)
void cprintwchar(const wchar_t* wcstr)
{
//告訴程序控制台緩沖區使用哪種編碼
//<locale.h>
setlocale(LC_ALL,"ZHI");
wprintf(L"%ls\n",wcstr);
}
//C++語言輸出char*類型字符串(ANSI/GBK)
void ccprintchar(const char* str)
{
std::cout << str << std::endl;
}
//C++語言輸出wchar_t*類型字符串(Unicode)
void ccprintwchar(const wchar_t* wcstr)
{
//告訴程序控制台緩沖區使用哪種編碼
//需要<locale>
std::wcout.imbue(std::locale("ZHI"));
std::wcout << wcstr << std::endl;
}