函數是C++程序的基本功能單元,就像一塊塊磚頭可以有規則地壘成一座房子,而一個個函數也可以有規則地組織成一個程序。我們在大量使用他人設計好的函數的同時,也在設計大量的函數供自己或他人使用。一個設計良好的函數,概念清晰職責明確,使用起來將非常容易,可以很大程度地提高我們的開發效率。反過來,一個設計糟糕的函數,概念不清職責不明,不僅難以使用,有時甚至會導致嚴重的錯誤。函數設計的好壞,成為評價一個程序員水平高低的重要標准。關於函數的設計,業界已經積累了相當多的經驗規則。這些經驗規則是每個新入行的程序員都應當了解和遵循的,並且需要在開發活動中將這些規則加以靈活應用。函數的兩個基本要素是函數的聲明和定義,下面分別從這兩方面來談一談相關的最佳實踐經驗。
函數的聲明,也稱為函數的接口,它是函數跟外界打交道的界面。它就像函數箱子上的標簽一樣,可通過這個標簽了解箱子中封裝的是什麼功能,需要什麼樣的輸入數據,以及能夠返回什麼樣的結果。換句話說,只要知道了一個函數的聲明,也就知道了該如何使用這個函數。大量實踐表明,一個函數是否好用,往往由其接口設計的好壞決定。在設計實現函數時,不僅要讓函數的功能正確,還要讓函數的接口清晰明了,有較高的可讀性。只有這樣,在使用這個函數時,才會清楚函數的功能及函數的輸入/輸出參數等,從而正確使用這個函數。如果函數的接口不清楚,則很容易造成函數的錯誤使用。
在函數接口的設計上,通常應當遵循如下幾條規則。
函數是對某個相對獨立的功能的封裝,而功能往往表現為某個動作和相應的作用對象。比如“拷貝字符串”這個功能,就是由“拷貝”這個動作以及動作的對象“字符串”共同構成。所以為了更好地表達函數的功能,在給函數命名時,最好使用函數的主要動作和作用對象組合而成的動賓短語,這樣就可以做到望文生義,讓函數的功能一目了然。例如:
// 計算面積 // Get是動作,Area是動作的對象 int GetArea(int nW, int nH); // 拷貝字符串 // cpy是動作,str是動作的對象 char* strcpy(char* strDest,const char* strSrc);
2. 使用完整清晰的形式參數名,表達參數的含義
參數表示函數所作用的對象及需要處理的數據,也就是函數所表示的動作的賓語。所以,最好能夠使用完整清晰的參數名來明確這個賓語的具體意義。如果某個函數沒有參數,也最好使用void填充,表示這個函數不需要任何參數。同樣是函數,不同的形式參數名可以帶來不同的效果,例如:
// 參數的含義明確, // 可以清楚地知道第一個參數表示寬度,第二個參數表示高度, // 整個函數的功能就是設置寬度和高度的值 void SetValue(int nWidth, int nHeight); // 參數的含義不明確, // 只能去猜測這兩個參數的含義,從而也就無法理解整個函數的功能 void SetValue(int a, int b); // 值得推薦的接口設計,沒有參數就使用void填充 int GetWidth(void);
3. 參數的順序要合理
在某些情況下,表示特定意義的多個參數的順序已經具有了業界普遍遵循的規則,比如復制字符串函數,總是把目標字符串作為第一個參數,而把源字符串作為第二個參數。這些規則我們應當逐漸熟悉並遵守,而不應該標新立異自行其事地打破這種規則。例如,寫一個設置矩形參數的函數:
// 不遵循參數順序規則的接口設計 void SetRect( int nRight, int nBottom, int nTop, int nLeft);
SetRect()函數的函數名很好地表達了這個函數的功能,形式參數名也清楚地表達了各個參數的意義,但它並不是一個好的接口設計,因為其中參數的順序不符合業界的普遍規則。如果該函數寫好了讓他人使用,而他人是按照業界的普遍規則來調用該函數的,則很可能因為參數順序的問題而導致函數被錯誤使用。這裡,規范的參數順序應該是:
// 規范的接口順序——先左上角的X和Y,後右下角的X和Y void SetRect(int nLeft, int nTop, int nRight, int nBottom);
4. 避免函數有太多的參數
雖然C++對函數參數的個數沒有限制,但參數個數不宜過多,應該盡量控制在5個以內。如果參數太多,在使用時容易將參數類型或順序搞錯,給函數的使用帶來困難。如果確實需要向函數傳遞多個數據,可以使用結構體來將多個數據打包,然後以傳遞整個結構體來代替傳遞多個參數數據。例如:
// 創建字體函數 HFONT CreateFontIndirect( const LOGFONT *lplf );
這裡,LOGFONT結構體就打包了創建字體所需要的多個數據,比如字體名字,字號等等。通過傳遞一個LOGFONT結構體指針,在函數內就可以通過這個指針訪問它所包裝的多個數據,也就相當於向CreateFontIndirect()函數傳遞了創建字體所需的多個參數。
函數的返回值代表了從函數返回的結果數據的類型。如果函數有結果數據通過返回值返回,則使用結果數據的類型作為返回值的類型。而有時候函數沒有結果數據通過返回值返回,不需要返回值,則可以使用void關鍵字作為返回值類型。但為了增加函數的可用性,我們有時也會給函數附加一個bool類型的返回值,用來表示函數執行成功與否。如果函數返回值用於出錯處理,這樣的返回值一定要清楚、准確,采用一些比較特殊的值,比如0、-1或nullptr,也可以是自己定義的錯誤類型編號等。
好的函數遵循的規則可以用圖5-9來表述。
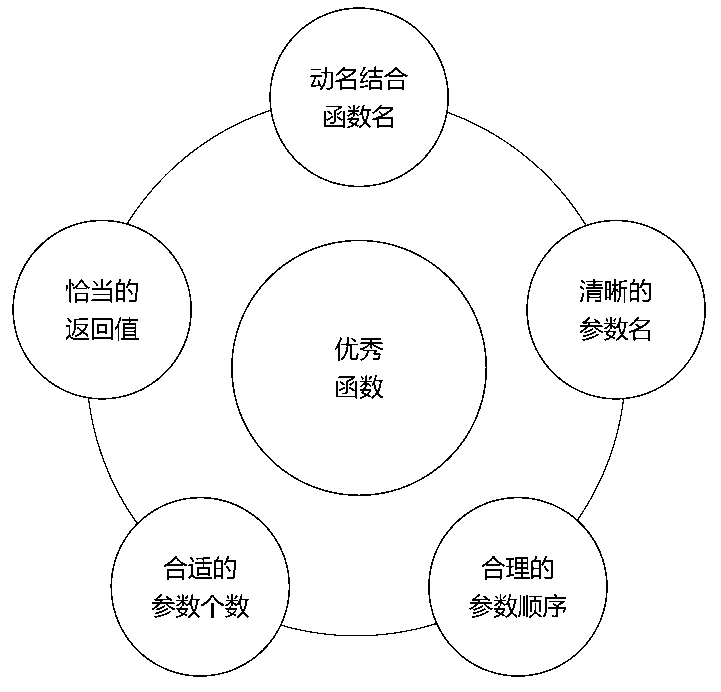
圖5-9 優秀函數的五項修煉
函數接口設計的好壞,決定了這個函數是否好用,而至於這個函數到底是否能用,則取決於我們對函數主體的設計與實現。雖然各個函數實現的功能各不相同,函數主體也大不一樣,但還是有一些普遍適用的經驗規則供我們學習和參考,從而設計出優秀的函數體。
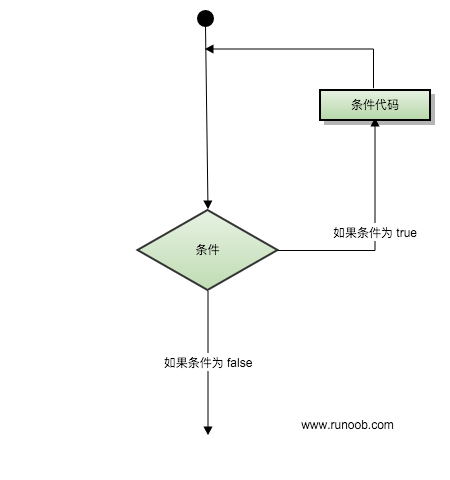
某些函數對參數是有特定要求的,例如,設置年齡的函數,其表示年齡的參數當然不能為負數;函數的參數為指針的,大多數時候這個指針參數也不能為nullptr。如果我們無法確保函數的使用者每次都能以正確的參數調用該函數,那就需要在函數的“入口處”對函數參數的有效性進行檢查,避免因無效的參數而導致更大錯誤的發生,增強程序的健壯性。如果需要對無效的參數進行處理,則可以采用條件語句,根據參數的有效性對用戶進行提示或者直接返回函數執行失敗信息等。例如:
// 設置年齡
bool SetAge( int nAge )
{
// 在函數入口處對參數的有效性進行檢查
// 如果參數不合法,則提示用戶重新設置
if( nAge < 0 )
{
cout<<"設置的年齡不能為負數,請重新設置。"<<endl;
// 返回false,表示函數執行失敗
return false;
}
// 如果參數合法,則繼續進行處理...
}
這裡,我們首先用if條件語句在函數入口處對參數的有效性進行了檢查。如果參數不合法,則提示用戶重新進行設置,並返回false表示函數執行失敗;如果參數合法,就繼續進行處理。通過對參數的有效性進行檢查,可以很大程度上提高函數功能的正確性,避免了年齡為負數這種不合邏輯的錯誤的發生。
如果只需要對參數的有效性進行檢查,而無需對無效的參數進行處理,還可以簡單地使用斷言(assert)來對參數的有效性進行判斷檢查,防止函數被錯誤地調用。斷言可以接受一個邏輯判斷表達式為參數,如果整個表達式的值為true,則斷言不起任何作用,函數繼續向下執行。如果表達式的值為false,斷言就會提示我們斷言條件不成立,函數的參數不合法,需要我們進行處理。例如,要設計一個除法函數Divide(),為了避免表示除數的參數為0這種錯誤的發生,我們就可以在函數入口處使用斷言來對該參數進行判斷,並提示函數是否被錯誤地調用。
#include <assert.h> // 引入斷言頭文件
using namespace std;
double Divide( int nDividend, int nDivisor )
{
// 使用斷言判斷表示除數的參數nDivisor是否為0
// 如果不為0,“0 != nDivisor”表達式的值為true
// 斷言通過,程序繼續往下執行
assert( 0 != nDivisor );
return (double)nDividend/nDivisor;
}
int main()
{
// 除數為0,Divide()函數被錯誤地調用
double fRes = Divide( 3, 0 );
return 0;
}
如果我們在主函數中以0為除數錯誤地調用Divide()函數,當函數執行到斷言處時,斷言中的條件表達式“0 != nDivisor”的值為false,則會觸發斷言,系統會終止程序的執行並提示斷言發生的位置,以便於我們找到錯誤並對其進行修復。直到最後所有斷言都得到通過,使參數的有效性得到保證。
值得注意的是,在函數入口處的參數合法性檢查,雖然可以在一定程度上增加程序的健壯性,但“天下沒有免費的午餐”,它是以消耗一定的程序性能為代價的。所以在使用的時候,我們需要在程序的健壯性和性能之間進行權衡,以做出符合需要的選擇。如果程序對健壯性的要求更高,那麼我們盡可能地進行參數合法性檢查;反之,如果程序對性能的要求更高,或者是這個函數會被反復多次執行,那麼我們將盡量避免在函數入口處進行參數合法性檢查,而是將檢查工作前移到函數的調用處,在調用函數之前對參數合法性進行檢查,以期在保證程序健壯性的同時不過分地損失程序性能。
知道更多:靜態(編譯期)斷言 -- static_assert
除了可以使用assert斷言在運行時期對參數的有效性進行檢查之外,我們還可以使用靜態(編譯期)斷言static_assert對某些編譯時期的條件進行檢查。一個靜態斷言可以接受一個常量條件表達式和一個字符串作為參數:
static_assert(常量條件表達式, 字符串);
在編譯時期,編譯器會對靜態斷言中的常量條件表達式進行求值,如果表達式的值為false,亦即斷言失敗時,靜態斷言會將字符串作為錯誤提示消息輸出。例如:
static_assert(sizeof(long) >= 8, "編譯需要64位平台支持");
一個靜態斷言在判斷某種假設是否成立(比如,判斷當前平台是否是64位平台)並提供相應的解決方法時十分有用,程序員可以根據靜態斷言輸出的提示信息快速找到問題所在並進行修復。必須注意的是,由於靜態斷言是在編譯期進行求值,所以它不能用於依賴於運行時變量值的假設檢驗。例如:
double Divide( int nDividend, int nDivisor )
{
// 錯誤:nDivisor是一個運行時的變量,無法用靜態斷言對其進行檢查
static_assert( 0 != nDivisor, "除數為0");
return (double)nDividend/nDivisor;
}
靜態斷言中的條件表達式必須是一個常量表達式,能夠在編譯時期對其進行求值。如果我們需要對運行時期的某些條件進行檢驗,則需要使用運行時assert斷言。
如果函數的返回值是指針類型,則不可返回一個指向函數體內部定義的局部變量的“指針”。因為這些局部變量會在函數執行結束時被自動銷毀,這些指針所指向的內存位置成了無效內存,而這些指針也就成了“野指針”(所謂的“野指針”,就是指向某個無效內存區域的指針。一開始,這個指針可能指向的是某個變量,或者某個申請得到內存資源,當這個變量被銷毀或者內存資源被釋放以後,這一區域就成為了無效內存區域,而仍舊指向這一無效內存區域的指針也就成了“野指針”)。當我們在函數返回後再次嘗試通過這些指針訪問它所指向的數據時,其內容可能保持原樣也可能已經被修改,不再是它原來在函數返回前的數據,而這些指向不確定內容的“指針”,會給程序帶來極大的安全隱患。例如:
// 錯誤地返回了指向局部變量的指針
int* GetVal()
{
int nVal = 5; // 局部變量
// 取得局部變量的地址並返回
return &nVal;
}
當在函數之外得到這個指針並繼續使用時,什麼事情都可能發生,例如:
// 得到一個從函數返回的指向其局部變量的指針 int* pVal = GetVal(); // 沒人會預料這個動作會產生什麼樣的結果,也許地球會因此毀滅 *pVal = 0;
除了上面兩個在函數入口和返回值上一進一出的規則外,在函數體的設計和實現上,我們還應當遵守下面這四項基本原則:
戀愛中的女孩,總是喜歡聽對方說“我只愛你一個,你是我的唯一”。而C++中的函數也像個戀愛中的女孩一樣,有著同樣的喜好。在C++中,我們總是將一個大問題逐漸分解成多個小問題,而函數,往往就是專門用於解決某一個小問題的。這也就決定了它的職責應該做到明確而單一。
明確,表示這個函數就是專門用來解決某一個小問題的。這一點往往反映在函數名上,我們總是用一個動詞或動名詞來表示函數的職責。比如,print()函數表示這個函數是負責打印輸出的,而strcmp()函數則是用於字符串比較的。函數名應當能夠准確地反映一個函數的職責。如果我們發現無法用某個簡單的動詞或動名詞來給某個函數命名,這往往就意味著這個函數的職責還不夠明確,也許我們還需要對其進行進一步的細化分解。
單一,意味著整個函數只做函數名所指明的那件事情——print()函數就只是打印輸出,不會去比較字符串,而strcmp()函數也只是比較字符串,而不會去把字符串輸出。一旦我們發現函數做了它自己不應該做的事情,這時最好的解決辦法是,將這個函數分解成更小的兩個函數,從而各司其職,互不干擾。比如,在一個查找最好成績的函數中,我們同時也畫蛇添足地查找了最差的成績,雖然表面上看起來一個函數作了兩件事情,起到了事半功倍的效果。但是,如果我們只需要最好成績,那麼這個同時查找的最壞成績會無端地消耗性能做了無用功,最後的結果往往是事倍功半。面對這種情況,我們應該將這個函數分解成更小的兩個函數,一個專門負責查找最好成績,而另一個專門負責查找最差成績。這樣,兩個函數各司其職,我們需要什麼功能就單獨調用某個函數就好了,兩個功能不要混在同一個函數中。
函數職責明確而單一是函數定義中最重要的一條規則,如果我們違反了這條規則,無異於大聲宣布自己腳踏兩只船,其下場自然是可想而知了。
函數職責的明確而單一,也就決定了函數的代碼應當短小而精干。反過來,如果發現某個函數太過繁瑣而冗長,那麼就該考慮考慮它的職責是否做到了明確而單一了。有人擔心短小的函數無法實現強大的功能,而實際上,經過良好的分層設計,函數借由調用下一層函數,將一個復雜的功能分解成多個小功能交由下一級函數實現,短小的函數同樣可以實現非常強大的功能。又有人擔心,函數都是短小而精干的,那樣就會讓函數的數量增多,會導致程序代碼量的增加。可事實是,讓函數保持短小而精干,不但沒有增加程序的代碼量,反而是減少了代碼量。因為這個過程往往將程序中重復的代碼提取成了獨立的函數,避免了許多代碼的重復,自然會減少代碼量。而且,這個過程也將我們的思路整理得更加清晰,增加了程序代碼的可讀性。
按照一般的實踐經驗,一個屏幕頁面應該能夠完整地顯示一個函數的所有代碼,這樣我們在查看編輯這個函數的時候就不需要翻頁,讓代碼閱讀起來更容易,同時也減少錯誤的發生。如果我們在這個代碼量范圍內,無法實現整個函數的功能,那麼我們就應該考慮這個函數的職責是否足夠明確而單一,是否還可以繼續細分成多個更小的函數。時刻牢記,無論是誰,都同樣討厭像裹腳布一樣又臭又長的函數。
在那些肥皂泡沫劇中,常常會出現“我愛你,你愛他,他愛我”的三角戀關系,而在函數的實現中,如果不留意,也容易出現這種三角的調用關系。在C++程序中,我們總是通過函數的嵌套調用來將某個比較復雜的問題逐漸細化分解,這可以很好地將復雜的問題簡單化,便於我們個個擊破。但是,我們也應當注意分解的層次。如果分解的原則不明確,分解的層次太深太混亂,就有可能會出現“我調用你,你調用他,而他又調用我”的“三角戀”式調用關系,最終讓整個程序陷入嵌套調用的無限循環中。例如:
// 函數的嵌套調用
// 函數的前向聲明
int GetArea();
int GetWidth();
int GetHeight();
// 函數的嵌套調用形成了無限循環
int GetWidth()
{
return GetArea()/GetHeight();
}
int GetHeight()
{
return GetArea()/GetWidth();
}
int GetArea()
{
int w = GetWidth();
int h = GetHeight();
return w*h;
}
在這裡,GetArea()函數調用了GetWidth()函數,而GetWidth()函數又反過來調用了GetArea()函數,這樣就形成了一個嵌套調用循環,這個循環會不斷地進行下去,直到最後資源耗盡程序崩潰為止。更讓人絕望的是,編譯器並不會發現這種邏輯上的錯誤,因而並不會給出任何的提示信息,使得這種錯誤有著極強的隱蔽性,更難以發現。
如果函數的嵌套層次太多,會讓整個程序的結構思路混亂,讓無論是寫代碼的人還是看代碼的人都陷入一團亂麻而無法自拔。每次讓我們迷路的地方,不是曲折的鄉間小道,而往往是那些設計巧妙的立交橋。因為它們縱橫交錯,遮擋了我們的視線。而嵌套分層太多的函數就相當於互相交錯的立交橋,在搞清楚它們干了什麼之前還得記住它們誰調用了誰。所以,不要讓我們的函數嵌套的層次太多,那樣只會讓我們的程序陷入混亂,而不會收到任何好的效果。
如果兩個函數有部分相似的功能,初學者的做法往往是,將一個函數中已經寫好的代碼直接復制過來,粘貼到另一個函數中。代碼的重復是程序員痛苦的根源。這一復制粘貼的過程,看似節省了我們編寫代碼的時間,實際上卻可能隱藏著各種各樣的錯誤:復制過來的代碼,只是實現了相似功能而已,我們往往還需要對其進行修改才能滿足新的需求,而這一過程可能會在復制過來的代碼中引入新的混亂;另外一方面,如果我們發現被復制的代碼有錯誤需要進行更新,因為代碼的重復,我們不得不修改多個地方的相同代碼,有時甚至會遺忘修改重復代碼中的錯誤而將錯誤遺留在代碼中,從而導致更多更大的錯誤。而正是因為這樣,我們為了修改這些可能出現的錯誤所花費的時間,往往遠超過我們復制粘貼代碼所節省的那一點點時間,這顯然是得不償失的。
那麼,如果遇到了函數中有相似功能的情況,我們該如何避免函數中代碼的重復呢?一條最簡單的規則是:每當我們想要復制大段代碼的時候,就想想是不是應該把這段代碼提取成一個單獨的函數。這樣,兩個擁有相似功能的函數就都可以調用這同一個函數來實現其中相似的功能。例如,在打印進貨單(PrintIn()函數)和出貨單(PrintOut()函數)的時候,我們都需要在頁眉部分打印公司名字等內容:
// 打印進貨單
void PrintIn(int nCount)
{
// 打印頁眉
cout<<"ABC有限公司"<<endl;
cout<<"進貨單"<<endl;
// 打印內容
cout<<"今日進貨"<<nCount<<"件"<<endl;
}
// 打印出貨單
void PrintOut(int nCount,int nSale)
{
// 打印頁眉
cout<<"ABC有限公司"<<endl;
cout<<"出貨單"<<endl;
// 打印內容
cout<<"今日出貨"<<nCount<<"件"<<endl;
cout<<"銷售額"<<nSale<<"元"<<endl;
}
對比這兩段代碼,我們可以發現在兩個函數中,負責打印頁眉的代碼幾乎完全一致。面對這種情況,我們應該將這段相似的代碼提取成一個獨立的函數(PrintHeader()函數)。這個函數會完成兩段代碼中相同的功能(打印公司名),而對於稍有差異的功能(打印不同的單名),則可以使用參數來加以區分:
// 提取得到的專門負責打印頁眉的PrintHeader()函數
void PrintHeader(string strType)
{
// 打印頁眉
cout<<"ABC有限公司"<<endl;
// 用參數對函數的行為進行自定義,使函數更具通用性
cout<<strType<<endl;
}
// 在PrintIn()和PrintOut()函數中調用
// PrintHeader()函數實現頁眉的打印
void PrintIn(int nCount)
{
// 打印頁眉
PrintHeader("進貨單");
//…
}
void PrintOut(int nCount,int nSale)
{
// 打印頁眉
PrintHeader("出貨單");
// …
}
通過這樣的函數提取,不僅避免了直接復制粘貼所可能帶來的諸多問題,同時使得代碼的結構更加清晰,易於我們的編碼實現。更重要的是,提取函數後的代碼更加易於後期的維護,如果將來公司的名稱發生了變化,或者是需要在頁眉部分增加新的內容,我們只需要修改PrintHeader()一個函數就行了,而PrintIn()和PrintOut()函數無需做任何修改就可以實現新的功能。這種方式,比直接復制粘貼更省時省力。
以上這四項基本原則,都是來自實踐的經驗總結,無數前輩的代碼驗證了這幾條經驗規則的正確性。簡單地講,它們可以總結成這樣一副簡單的對聯:“應明確單一,宜短小精干;忌嵌套太多,勿重復代碼”。如果能夠把這副對聯高掛於廳堂之上並時時念叨,必能保函數平安,程序興旺。

圖5-10 “函數倒了”