一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(一)——地:起因
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(二)——月:自旋鎖
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(三)——地:q3.h 與 RingBuffer
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(四)——月:關於RingQueue(上)
這兩天狀態不是很好,我甚至把最新的《鹿鼎記》(梁棟版)快看完了,基本上是躺床上看的,其實不算好看,可能是太無聊了。不過我還是把 disruptor 大致看明白了,也修改了 disruptor 的測試代碼,基本接近 RingQueue 的測試了。不過目前的測試結果跟 RingQueue 比還有點差距,不過也不算大。反正 disruptor 沒有想像中的那麼快,不知道是什麼原因造成的,語言本身的問題?也許我應該找 disruptor 的 C++ 版本試試。而且 disruptor 在生產者和消費者越多的時候越慢,反正有點匪夷所思。同時也更新了一下 RingQueue ,也把類似 disruptor 的 ops/sec 這樣的吞吐率加上去了。
disruptor 的 測試代碼在:https://github.com/shines77/RingQueue/blob/master/disruptor/RingBufferPerfTest.java
後面我會寫一篇關於 disruptor 的詳細分析(主要分析多生產者和多消費者,能力有限,不過新版的跟網上看到的文章有些變化),有經驗的也可以先幫我測測,幫我找一下問題,除了 disruptor 的休眠策略不如我的以外,其他看起來都還不錯的。同時,我在 korall 提供的那個 wikipedia 的地址裡也找到了兩篇關於 多生產者和多消費者 的 wait-free 算法論文,研究了一會,不知道是否是正確的,即使是正確的,實現後是否一定更快?
根據第三篇評論裡網友 korall 的提醒,我們討論一下 lock-free(無鎖) 的定義,我們這麼定義它:
如果一個方法是 lock-free 的,那麼它將保證線程無限次調用這個方法都能夠在有限步內完成,而不會因為其他線程被阻塞而導致本線程無法在有限步內完成,即“無鎖”。
lock-free 的反義詞是 lock(有鎖的)、blocking(阻塞),同義詞是:non-blocking(非阻塞)。
參考自:http://ifeve.com/lock-free-and-wait-free/
wait-free(無等待) 的定義:
如果一個方法是 wait-free 的,那麼它將保證每一次調用都可以在有限的步驟內結束,也可以理解為“無循環”,或“循環次數”為常數次或有限次。
參考自:http://ifeve.com/lock-free-and-wait-free/
上一篇分析了 Sinclair 的 q3.h 的原理,以及根據網友 korall 的提醒,我們可以看到,q3.h 的 push() 前半部分領號的過程是 lock-free 的,這裡 lock-free(無鎖) 的定義是指假如有一個線程在領號的過程中被無限休眠或崩潰(假設存在崩潰的可能性),也不會造成別的線程在領號的過程中因此而被阻塞。而 push() 的後半部分,即提交成功的確認過程,不是 lock-free 的,而是阻塞的,因為假設在線程A裡,在領號完成之後到 q->head.second = next; 這句生效之前的任何地方,如果線程A被無限休眠或崩潰,那麼其他線程在確認提交的過程是會被阻塞的,因為前面一個序號沒提交成功,後面的線程都必須“死等”,從而造成“死鎖”,所以這個過程的確是一個“鎖”。同理,pop() 也一樣,前半部分是 lock-free(),後面的確認過程是一個“鎖”。
由此可知,q3.h 的整個 push() 和 pop() 是由兩個 lock-free 結構和兩個 “鎖” 構成的,雖然這兩個"鎖"是 push() 和 pop() 各自獨立的,即 push() 的 “鎖” 競爭只會發生在 push() 線程之間,pop() 的 “鎖” 競爭也只會發生在 pop() 線程之間,lock-free 部分也類似。但是兩個 “鎖” + 兩個 lock-free 結構,總體來看,競爭似乎也不算小。
所以,我們為什麼不干脆直接用一個 “鎖” 來解決?至少這是一個值得嘗試的方案,這就是後來混合自旋鎖 RingQueue::spin2_push() 誕生的原因。
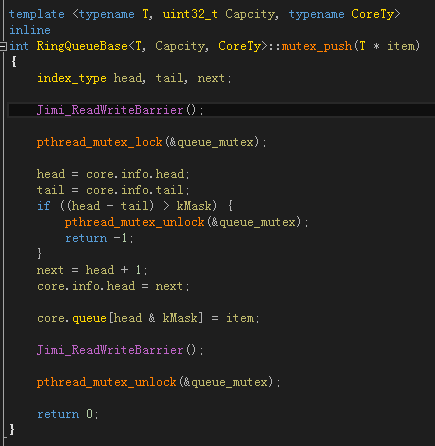
不過一開始我並沒有這麼想,起初,是先根據 q3.h 的大致思路,盡量考慮 CAS 來實現,即所謂的 lock-free,這個代碼就是 include\RingQueue\RingQueue.h 裡 RingQueue::push(),RingQueue::pop(),代碼截圖如下:
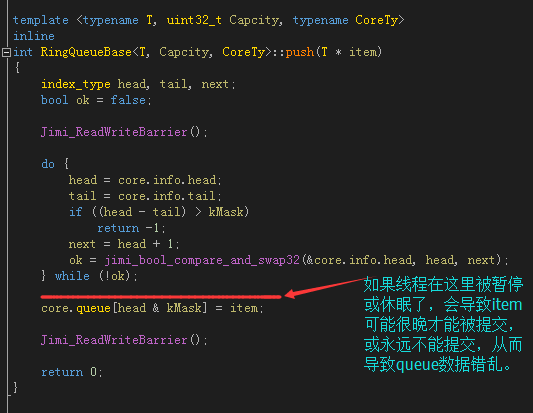
很快,我們發現有問題,如上圖,因為CAS完成後,線程是有可能被休眠的,一旦休眠就有可能出現上面提到的問題。主要的原因是,雖然CAS保證了領到的 head 是唯一的,但是不能同時把 core.queue[head & kMask] = item; 也一起更新了,如果可以的話,就完美了。後來我想到了使用Double CAS,使用Double CAS更新 core.info.head 的同時一起更新 core.queue[head & kMask] 不就好了嗎。可是,很快,我也發現,x86 上的Double CAS要求更新的內存地址必須是連續的,也就是說 core.info.head 和 core.queue[head & kMask] 在內存上不是連續的話,是無法使用Double CAS的,至少在目前的 x86 CPU 上不行,而由於邏輯上的問題,我們沒辦法讓它們變成連續的內存。除非 Intel 將來實現我們想要的增強型 Double CAS……
所以這個方法是不行的。這個方法雖然簡單,但沖突次數很多,所以速度不算很快,而且通過合理性驗證也能證明是有bug的,截圖如下。有興趣的朋友可以在main()裡把這一句://RingQueue_Test(0, true); 的注釋去掉試試,同時還要把 test.h 裡的#define TEST_FUNC_TYPE 定義為 0。
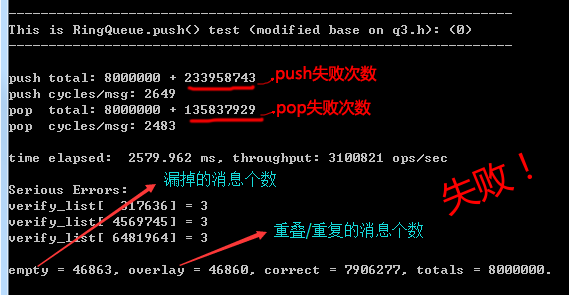
於是我開始寫“鎖”,想當然的,我們構造了這麼一個結構體spin_mutex_t,之所以叫 spin_mutex 是因為 tbb 裡就管自旋鎖叫 spin_mutex,因為其邏輯上確是一個“互斥量”,所以叫 mutex 也貼切,不過一般習慣叫spin_lock。
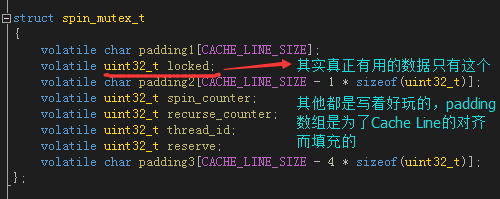
其實真正有用的數據只有一個uint32_t locked,為1時是“鎖”狀態,為0時是“未鎖”狀態。padding1, padding2, padding3是為了對齊而填充的,因為我們並沒有對結構體本身聲明字節對齊(我懶得弄了),所以開頭只好加個padding1這麼弄了,浪費那麼一點內存沒關系。後面那些spin_counter,recurse_counter,thread_id什麼是用來擴展的,這裡沒有用到,寫著好玩的。
之所以說想當然,是因為我從來也沒寫過自旋鎖,於是寫成了這樣:
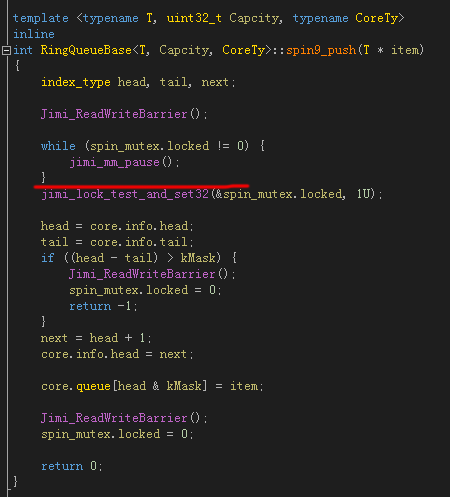
jimi_lock_test_and_set32() 其實就是 InterlockedExchange() 或者 __sync_lock_test_and_set(),一開始用 while (spin_mutex.locked != 0) 判斷是否為 0 (未鎖)狀態,如果是 0 才進入鎖區域,然後用原子操作把 “鎖” 狀態更新為 1 (鎖)狀態,最後出了鎖區域,再把鎖狀態置為 0 (未鎖)。一切看起來很正常,可是運行起來會活鎖 (livelock),也許偶爾會放一個消息進來,但非常非常慢,甚至可能變成死鎖 (deadlock),反正狀態幾乎是未知的。分析原因,注意上圖中的劃紅線的地方,雖然前面可能檢測的鎖狀態的確是 0 (未鎖)狀態,但是如果線程在紅線的地方被休眠了,那麼因為鎖狀態依然是 0,那麼其他線程也可以進入鎖區域,然後把鎖狀態設為了 1,等該線程被重新喚醒以後,它不知道鎖已經是 1 (鎖)狀態,它也處於鎖保護的區域,並且把鎖狀態也重新設置為 1,這將導致兩個線程同時處在鎖區域內,這將導致共享的資源出現同步的問題。另一方面,jimi_lock_test_and_set32()是有可能因緩存行(Cache Line)被其他線程鎖住而失敗的,因此有時候並不能成功寫入狀態1,這將使多個線程同時進入鎖區域的問題更加頻繁。當隊列滿了或空了的時候,狀態就變得不可預測了。
這個代碼也保留在了 RingQueue::spin9_push() RingQueue::spin9_pop() 裡,也可以看整理過後的版本 RingQueue::spin8_push() RingQueue::spin8_pop(),兩者是一樣的。
不過,很快的,我們用 CAS (Compare-And-Swap) 改進了前面錯誤的代碼。CAS 的說明可參考 第三篇 裡的相關介紹。
int val_compare_and_swap(volatile int *dest_ptr,
int old_value, int new_value)
{
int orig_value = *dest_ptr;
if (*dest_ptr == old_value)
*dest_ptr = new_value;
return orig_value;
}
我們需要的是判斷鎖狀態為 0 的同時把鎖狀態置為 1,CAS 剛好能夠實現我們的效果,因為 CAS 操作是原子性的,所以不會出現我們前面所遇到的多於一個線程同時進入鎖區域的問題。
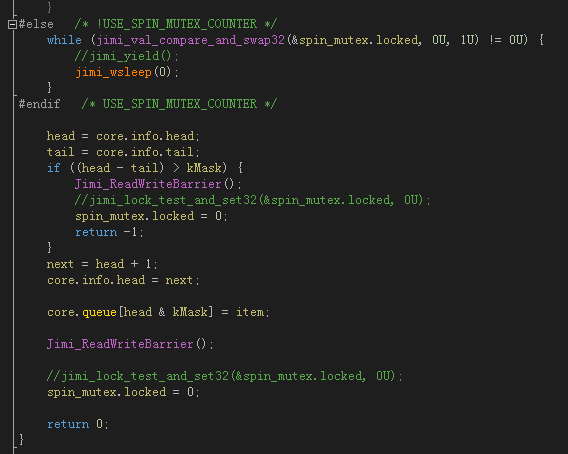
這是自旋鎖的第一個版本,RingQueue::spin_push(),你可以看到,其實它並沒有自旋,而是jimi_wsleep(0)了一下,jimi_wsleep(0)在Windows下等價於Sleep(0),在Linux下等價於sched_yield()。這裡並沒有休眠,而是切換到了別的線程。
還有一個問題,就是上圖中兩個 “spin_mutex.locked = 0;“ 語句的前面一行,我都注釋掉了一行原子寫操作的代碼。那是我原來寫的,可是後來仔細分析,進鎖的時候用 CAS 把門關上了,最後 “解鎖” 的時候是沒必要用原子操作來更新鎖狀態的,置 0 的瞬間就代表了解鎖。這樣效率會好很一些,為什麼呢,你仔細想想就會明白,唯一需要的就是在更新鎖狀態之前要加一個內存屏障/編譯器內存屏障,如代碼中的Jimi_ReadWriteBarrier()。這個也是後來看了很多其他代碼所證實的,其實也沒什麼稀奇的,不過如果你不明白,還是要提一下。
不過我也寫了自旋的版本,具體可以參看 RingQueue::spin_push() 的代碼,需要在 test.h 裡面把宏 USE_SPIN_MUTEX_COUNTER 定義為 1才能打開自旋的版本,自旋循環控制參數為宏 MUTEX_MAX_SPIN_COUNT (默認設置為1)。
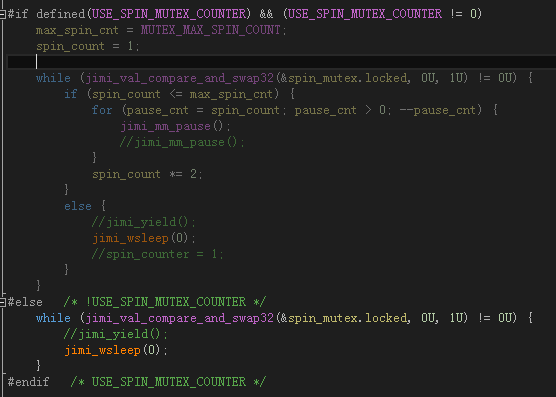
這個策略是跟 Intel 多線程庫 tbb 的 spin_mutex 學的。
就是這麼小的一個改進,速度已經不錯了,不過缺點是不夠穩定。
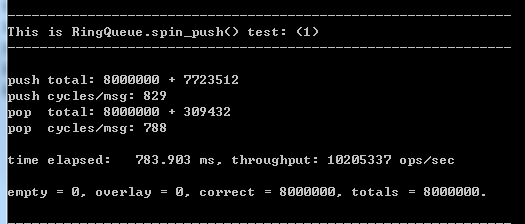
有時候是這樣的:
這裡說一下我的測試環境:
CPU: Intel Q8200 2.4G 4核
系統: Windows 7 sp1
內存: 4G / DDR2 1066
編譯器:Visual Studio 2013 Ultimate update 2
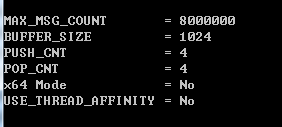
使用的是 4 個 push() 線程(生產者),4個 pop() 線程(消費者),消息總數為 8000000 條(八百萬),隊列的容量為 1024 (buffer_size),x86模式,不開啟CPU親緣性。
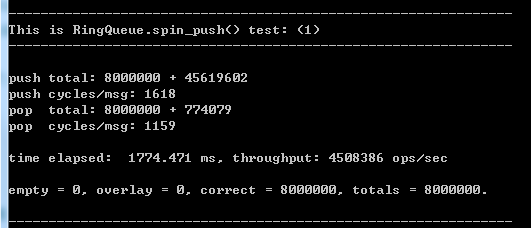
如果你對這個速度沒有概念,我們找一個東西來作為基准,用 mutex (互斥鎖) 再合適不過了,Windows下它叫臨界區(CriticalSection),Linux下它叫pthread_mutex_t:
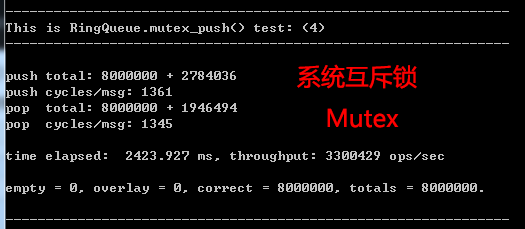
這個是 PUSH_CNT = 2, POP_CNT = 2 下得到的結果,不過對於系統的互斥鎖,這個值是多少差別不大。
系統互斥鎖的版本是:RingQueue::mutex_push()。
下面是 豆瓣 Sinclair 的 q3.h 的測試結果,可以看到,並不是很快,甚至比系統互斥鎖(Mutex)還要慢一點,由於其只有當 (PUSH_CNT + POP_CNT) <= CPU核心數 時才能正常工作,否則會很慢很慢,所以下面的數據也是在 PUSH_CNT = 2, POP_CNT = 2 下得到的:

說句實話,RingQueue::spin_push() 依然還是太簡單了一點,即使是模仿 tbb 的自旋版本也談不上有多復雜,感覺哪裡還不是太夠。
我在 c++1y boost 交流群(QQ群:296561497)裡曾經看 DengHe.Net 貼過一個 C# 用反射工具反編譯的關於 Thread.Yield() 的源碼(發到群裡的是圖片),其實類似的東西在哪裡好像也看過,只是你不到真正要用的時候,是不會發現它的問題的。我後來在兩個群裡翻聊天記錄找了一個多小時,結果還是沒找到,其實我知道網上能搜到,不過還是覺得好像 DengHe 貼的那個好像有點特別,後來他告訴我就是反編譯的 SpinWait.cs,其實那個時候我也找到 SpinWait.cs,由於我對 C# 也不是很熟,沒想到用反射工具。
其實 Thread.Yield() 是怎麼回事還是大致知道的,不過的確有個確定的版本會更加有參考性一點,C#的 Thread.Yield() 除了參數是固定不能修改的以外,其他的設置還是比較合理的,這也是 RingQueue::spin2_push() 的雛形。當然我還是做了一些小調整,因為混合自旋鎖要想效率高,就看你怎麼調整這些參數,這是一個休眠的策略。或者說是一門休眠的藝術,再後面一點我會詳細描述。今天就先賣個關子。。。
RingQueue的源碼最關鍵的地方就在 include\RingQueue\test.h 裡面了,這裡的宏定義是各個部分的編譯開關,我基本都寫了注釋,如果有不懂的可以自己研究,或者問我,基本上我考慮的東西算比較多了,裡面最重要的就是 PUSH_CNT 和 POP_CNT 的定義,顧名思義,PUSH_CNT 就是 push() 的線程數,POP_CNT 就是 pop() 的線程數,分別對應著生產者(producer)和消費者(consumer)的個數。如果你想測試 q3.h,那麼你的 (PUSH_CNT + POP_CNT) 必須小於等於你的CPU核心數,否則會慢得出奇。例如你的 CPU 是雙核的,就知道定義為 PUSH_CNT = 1, POP_CNT = 1 了,如果你不測 q3.h,那麼建議你把 PUSH_CNT 和 PUSH_CNT 設置成跟你的 CPU 核心數一樣,即 PUSH_CNT = 2, POP_CNT = 2。因為一般來講,把總線程數設置為 CPU 核心數的兩倍是比較能夠提高 CPU 的利用率的,這是一組較優解,雖然不一定是最優解,其他設置請自行看 test.h。
今天就寫到這裡吧,本來想一口氣寫完的,如果可以的話,以後再合並在一起。
其實還有個問題耽擱了寫文章,就是我也不知道哪根筋不對,在 REDUI 群裡宣傳我的博文,還跟某些人有點小吵起來,經過兩天時間,雖然有些摩擦,最終他們還是接受了我關於 RingQueue 的一些思路和想法,最後還討論到了一起去,也算是有點小開心吧,至少比 SkyNet 群好多了。其實說白了也沒多少東西要講,不過細節不少,我還自己發現了一些奇怪的問題,其實我是想把那些細節講好,但我發現現在的確控制得不是很好,也許我應該憋長一點再發(文章),或者你直接看源碼比較快。
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下載UTF-8編碼版:https://github.com/shines77/RingQueue-utf8。 我敢說是一個不錯的混合自旋鎖,你可以自己去下載回來看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,還支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等,當然可能不支持ARM,沒測試環境。
(未完待續……敬請期待……)
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(一)——地:起因
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(二)——月:自旋鎖
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(三)——地:q3.h 與 RingBuffer
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(四)——月:關於RingQueue(上)