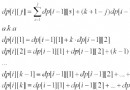再說 c++11 內存模型
可見性與亂序
在說到內存模型相關的東西時,我們常常會說到兩個名詞:亂序與可見性,且兩者經常交錯著使用,容易給人錯覺仿佛是兩個不同的東西,其實不是這樣,他們只是從不同的角度來描述一個事情,本質是相同的。比如說,我們有如下代碼:
atomic<int> g_payLoad = {0};
atomic<int> g_guard = {0};
// thread 0
void foo1()
{
g_payLoad.store(42, memory_order_relaxed);
g_guard.store(1, memory_order_relaxed);
}
// thread 1
void foo2()
{
int r = g_guard.load(memory_order_relaxed);
if (r)
{
r = g_payLoad.load(memory_order_relaxed);
}
}
因為 g_guard 與 g_payLoad 的讀寫都是以 relaxed 方式進行,因此我們會認為 foo2() 中 g_guard.load() 與 g_payLoad.load() 有可能會亂序(從不同的地址 load, cpu 可能會 speculate & prefetch,etc),但從另一個角度來看,g_payLoad 被 reorder 到 g_guard 之前(其它類型亂序同理),其實就相當於 g_payLoad 在 foo1 中的修改沒有被 foo2 所看到,同一件事情的兩個不同角度,如此而已。
但在處理 c++11 的內存模型時,語言標准上的措詞卻基本上是基於“可見性”來描述的(和 Java 的內存模型描述基本一致),看得多了,我也漸漸發現從“可見性”來理解問題有時真會容易很多,不信請繼續看。
Happen-before
Happen-before 指的是程序指令間的一種關系,且是一種運行時的關系,是動態的,如果指令 A happen-before B, 則 A 的副作用能夠被 B 所看到,容易理解對吧?且暫時可簡單認為 happen-before 具有傳遞性(transitive)(准確地說是在不考慮 consume ordering的情況下), 如果 A happen-before B, B happen-before C,則我們可以認為 A happen-before C。
兩條指令 A 與 B 如要滿足 happen-before 關系,必須滿足如下條件之一:
A sequence-before B: 這個指的是在同一個線程裡兩條指令的關系,從程序源碼上看如果指令 A 在 B 之前,則 A sequence before B, 比如前面代碼中 g_payLoad.store() 這一行代碼就是 sequence-before g_guard.store().
A synchronize-before B: 這個指的是兩個線程間的指令的關系,接下來一節再介紹。
因此當我們在理解代碼時,如果想弄清楚當前線程裡某些代碼是否能看到公共變量在別的線程裡被修改後的效果,我們應該第一時間這樣來考慮,當前使用這些公共變量的代碼能與別的線程裡修改這些公共變量的代碼建立一個 happen-before 的關系嗎?如果有 happen-before 關系,則可以看到,如果沒有則不一定,還是使用前面的例子:
// thread 0
g_payLoad.store(42, memory_order_relaxed); // 1
g_guard.store(1, memory_order_relaxed); // 2
// thread 1
int r = g_guard.load(memory_order_relaxed); // 3
if (r) r = g_payLoad.load(memory_order_relaxed); // 4
如果 g_payLoad.load() 要 load 到 #1 中所寫入的值,則這兩者之間必須要有 happen-before 關系,而他們之間要有 happen before 關系,只需滿足如下兩個條件之一:
它們真的有 happen-before 關系,即上述代碼中, #1 happen-before #4, 不過這個沒法只根據 1 和 4 這兩行代碼來證明, 原因下面一節會具體解釋。
g_guard.store() 與 g_guard.load() 之間有 happen-before 關系, 即 #2 和 #3 之間有 happen-before 關系,則根據傳遞性,我們可以知道 #1 happen-before #4.
Synchronize-with
Sychronize-with 指的是兩個線程間的指令在運行時的一種特殊關系,這種關系是通過 acquire/release 語義來達成的,具體來說,如果:
線程 A 中對某個變量 m 以 release 的方式進行修改,m.store(42, memory_order_release).
線程 B 中對變量 m 以 acquire 的方式進行讀取,並且讀到線程 A 所寫的值(或以 A 為開始的一個 release sequence 所寫入的值),則線程 B 中讀 m 變量的那條指令與線程 A 中修改 m 的指令存在 synchronize-with 的關系。
順便說一下 release sequence,操作 A 對變量 m 的 release sequence 指的是滿足如下兩個條件且作用於 m 上的操作的序列:
該操作與 A 在同一個線程內,且跟在 A 操作之後。
該操作在其它線程內,但是是以 Read-Modify-Write(RMW) 的方式對 m 進行修改。
其中, A 操作以 store release 的方式修改變量 m,而 RMW 操作是一種很特殊的操作,它的 read 部分要求永遠能讀到該變量最新的值。[參看 c++ 標准 29.3.12]
下圖展示了一個經典的 synchonize-with 的例子:
這裡有一點需要明確,操作 A 與 操作 B 是否存在 synchronize-with 關系,關鍵在於 B 是否讀到了 A 所寫入的內容(或 release sequence 寫入的內容), 而 B 是否能讀到 A 寫入的內容與 A 這個操作是否已經進行了無關,c++ 標准的規定是,假如讀到了,則 A synchronize-with B, 否則則不,因此對於某些關鍵變量,如果你想保證當你去讀它時,總能讀到它在別的線程裡寫入的最新的值,一般來說,你需要額外再設置一個 flag 用於進行同步,一個標准的模式就是前面例子中的 g_payLoad 與 g_guard。 g_payLoad 是你關注的關鍵信息或者說想要發布到別的線程的關鍵信息,而 g_guard 則是一個 flag,用於進行同步或者說建立 happen-before 的關系,只有建立了 happen-before 關系,你去讀 g_payLoad 時,才能保證讀到最新的內容。
sequential consistency
sequential consistency 這種模型實在是太美好了,它讓編碼變得這樣地簡單直接,一切都是和諧有序的,社會主義般地美好,而這種美好又是那麼地觸手可及,只要你完全不要使用其它模型,SC 就是你的了!而你所需付出的代價只是一點點效率上損失,就那麼一點點!但不幸 c++ 程序員裡面處女座的太多,因此我們得處理 acquire/release,甚至是 relaxed。而當 SC 與其它模型混合在了一起時,一定不要想當然以為有 SC 出現的地方就都是曾經的美好樂園,不一定了。
以 sequential consistency 方式進行的 load() 操作含有 acquire 語義。
以 sequential consistency 方式進行的 store() 操作含有 release 語義。
所有 sequential consistency 操作在全局范圍內有一個一致的順序,但這個順序與 happen-before/synchronize-with 沒有直接聯系,sequential consistency Load 不一定會 Load() 到最新的值,sequential consistency write() 也並不一定就馬上會被其它非 sequential consistency load() 所能 load() 到。
需要注意的是 sequential consistency 類型的 fence,它是個例外,和純粹的 SC load 和 SC store 不同,SC fence 能建立 happen-before 關系,參看 c++ 標准 29.3.6:
假如存在兩個作用於變量 m 的操作 A 和操作 B,A 修改 m,而 B 讀取 m,如果存在兩個 memory_order_seq_cst 類型的 fence X 與 Y,使得:
1. A sequence-before X,且 Y sequence-before B.
2. 且 X 在全局順序上處於 Y 之前(因為 X 和 Y 是 memory_order_seq_cst 類型的,因此肯定有一個全局順序)。
則 B 會讀到 A 寫入的數據。
Dekker and Petterson's Algo
現在讓我們嘗試用前面介紹的知識來解決兩個問題,如下是一個簡化版的 Dekker's Algo,假設所有數據的初始值都是 0,則顯然,如果所有內存操作都是以 relaxed 方式進行的話,則 r1 == r2 == 0 是可能的,因為 thread 0 裡對 g_a 的讀取不一定能看到 thread 1 對 g_a 的修改,對 g_b 的讀取同理,現在的問題是,怎麼才能阻止同時讀到 r1 == r2 == 0?
// thread 0
g_a.store(42, memory_order_relaxed); // 1
r1 = g_b.load(memory_order_relaxed); // 2
// thread 1
g_b.store(24, memory_order_relaxed); // 3
r2 = g_a.load(memory_order_relaxed); // 4.
直接機械地套用 acquire/release 是不行的,#1 和 #4 不一定能建立 synchronize-with 關系,且 g_a 本身是關鍵變量,我們需要保證的是能讀到它的最新值,直接用它來建立 synchonize-with 顯然不能保證這點,#3 和 #2 同理。一個解法是分別在兩個 thread 裡分別加入一個 SC fence:
// thread 0
g_a.store(42, memory_order_relaxed);
atomic_thread_fence(memory_order_seq_cst); // fence 1
r1 = g_b.load(memory_order_relaxed);
// thread 1
g_b.store(24, memory_order_relaxed);
atomic_thread_fence(memory_order_seq_cst); // fence 2
r2 = g_a.load(memory_order_relaxed); // 4
原理很簡單,因為 fence 1 和 fence 2 是 sequential consistency 類型的, 因此它們的副作用在全局上有一個固定順序,要麼 fence 1 先於 fence 2,要麼 fence 2 先於 fence 1,根據前一節的介紹,我們知道要麼 g_a 讀到 42, 要麼 g_b 讀到 24, 因此肯定不會出現 r1 == r2 == 0.
現在是第二個問題,如下是 Peterson's Algo 的簡化寫法, 用於實現互斥鎖,問題的關鍵是怎麼保證 flag0 在線程 1 裡能讀到線程 0 對它的修改?等價問題是怎麼阻止 #3 被 reorder 到 #1 之前,#6 被 reorder 到 #4 之前?
// Thread 0
flag0.store(true, memory_order_relaxed); // 1
r0 = turn.store(0, memory_order_relaxed); // 2
r1 = flag1.load(memory_order_relaxed); // 3
// Thread 1
flag1.store(true, memory_order_relaxed); // 4
r0 = turn.exchange(1, memory_order_relaxed); // 5
r1 = flag0.load(memory_order_relaxed); // 6
現在我們嘗試用 acquire/release 語義來解決它,假設 thread 0 先執行並進入了臨界區,然後 thread 1 後執行,當 thread 1 執行到 #6 時,怎麼保證能看到 thread 0 對 flag0 的修改呢?根據前面第二節的介紹,我們知道關鍵在於要保證 #1 happen-before #6,又由於 #1 和 #6 分別在不同的線程,因此其實就是要保證 #1 synchronize-with #6,因此我們需要在 thread 0 中以 release 的方式寫一個變量 A,然後在 thread 1 中以 acquire 的方式讀取該變量 A,那麼我們應該選取哪個變量作為這個關鍵變量呢?
flag0 不行,原因與前面第一節的例子相同,flag0 是我們要讀取的關鍵變量,我們要保證的是能讀取到它的最新值,而不是通過它來實現 synchronize-with.
flag1 也不行,flag1 在 thread 0 只有一個 load 操作,沒有 release 語義(但如果用 flag1.fetech_add(0, memory_order_acq_rel) 呢?應該也是行的,只是不是最好,多了一次無謂的寫操作)。
最優選擇應該是 turn 變量。
因此得到如下解法如下:
// Thread 0
flag0.store(true, memory_order_relaxed); // 1
r0 = turn.exchange(1, memory_order_acq_rel); // 2
r1 = flag1.load(memory_order_acquire); // 3
// Thread 1
flag1.store(true, memory_order_relaxed); // 4
r0 = turn.exchange(2, memory_order_acq_rel); // 5
r1 = flag0.load(memory_order_acquire); // 6
讓我啰嗦點指出其中一個關鍵,#2 和 #5 能建立 synchronize-with 關系的關鍵在於 exchange 是一個 RMW 操作,且它的讀部分是要求能夠讀到最新的值(c++ 標准 29.3.12),因此當 thread 0 先執行時,turn 會被以 release 的方式被寫入一個值,再然後後面 thread 1 執行 #3 ,會以 acquire 的方式對 turn 進行讀取,因為 RMW 保證它的 load 會 load 到最新的值,因此此時 #2 synchronize-with #5,皆大歡喜。