學過前面的基本數據類型之後,我們現在可以定義單個變量來表示單個的數據。例如,我們可以用int類型定義變量來表示公交車的216路;可以用float類型定義變量來表示西紅柿3.5元一斤。但是,除了單個孤立的數據之外,現實世界中還有一類批量數據。例如,一個公司所有員工的工資,這些數據的數據類型相同(都是int類型),性質相同(都表示員工的工資),數量很多(成千上萬員工的工資),並且往往形成一個有意義的數據集合(員工工資)。針對這類的批量數據,單獨地定義一個一個的變量來表示顯然是行不通的。為此,C++提供了數組這種構造型數據類型來表達批量數據,它將這些數據組織起來形成一個數據序列,讓這些數據排排坐,吃果果,極大地方便了批量數據的處理。
在C++中,定義一個數組的方法同定義一個變量的方式非常相似,不同的是,變量名變成了數組名,而在數組名之後,我們用中括號“[]”引出了表示數組中數據元素個數的常數。其具體語法形式如下:
數據類型 數組名[個數常量][個數常量]…;
其中,數據類型表示這一系列批量數據的類型。比如,我們要定義一個可以保存多位員工工資的數組,而每個員工工資數據都可以用int類型數據表示,那麼整個數組的數據類型就是int類型;數組名通常是一個表明數組中數據含義的標識符。在這裡,數組中的數據都是員工工資,所以我們可以用arrSalary作為數組名。其中,arr表示這是一個數組(array),而Salary則表示數組中的數據都是工資;數組名後中括號中的個數常量則表示這一系列批量數據的個數。比如,這個公司有100000位員工,我們需要在數組中保存100000個工資數據,那麼這個個數常量自然就是100000。另外需要注意的是,這個個數常量必須大於0,並且必須是常數。根據上面的分析,我們可以這樣來定義用以保存100000個員工工資數據的數組:
// 保存100000個員工工資的數組 int arrSalary[100000];
在定義數組的同時,也可以利用“{}”對數組進行初始化。例如:
// 定義數組並進行初始化
int nArray[5] = { 1,2,3,4,5 };
這行代碼在定義一個長度為5的整型數組nArray的同時,用“{}”把1、2、3、4、5分別賦值給數組中的5個元素,以此來完成數組的初始化。當然,如果不需要對數組中的所有數據都賦初始值,也可以僅對數組的前面部分元素賦值,而剩余的未指定初始值的數據,會被賦值為0或是這種數據的默認初始值。例如:
// 給定數組中前6個元素的初始值,剩下94個數據被賦值為0
int nBigArray[100] = { -10, 23, 542, 33, 543, 87 };
雖然我們可以利用“{}”在定義數組的同時對數組元素賦初始值,可是數組的數據元素往往較多,要想使用“{}”完成其中所有數據的賦值,往往是不太現實的。更多的時候,我們是利用“{}”將數組中的所有元素都賦值為0,完成數組使用前的清零操作。例如:
// 將nBigArray數組中的所有元素賦值為0
int nBigArray[100] = { 0 };
知道更多:多維數組
數組定義中的中括號“[ ]”用於確定數組的維數。在數組名後有幾個“[ ]”就表示這是一個幾維數組,而一個數組的維數,往往代表了其中數據的分類次數。比如,我們要表示一個學校所有學生的成績,我們往往先把所有學生成績按照年級分成三個年級,然後每個年級又可以按照班級分成10個班級,而每個班級又有30名學生。這樣,經過三次分類,我們就可以用一個三維數組來保存一個學校所有學生的成績:
// 記錄學生成績三維數組 int arrScore[3][10][30];
定義好數組後,我們就相當於擁有了多個變量,可以引用數組中的數據元素來進行運算。要想訪問數組中的各個數據,我們通過在數組名後的中括號中給定數組下標來實現。所謂數組下標,它代表了要訪問的數據在數組中的位置。要注意的是,這個表示數據位置的下標是從0開始記數的。比如,在我們前面定義的記錄員工工資的arrSalary數組中,第一個數據是老板的工資,我們就可以通過如下的方式來讀寫訪問第一個數據:
// 數組中第一個數據表示老板的工資,用下標0表示數組的第一個數據 // 賦值為1,表示老板的工資為1 arrSalary[0] = 1; // 讀取數組中的第一個數據,輸出老板的工資 cout<<"老板的工資是:"<這裡我們可以看到,通過在數組名之後的中括號中給定0這個下標,我們可以像讀寫普通變量一樣地來讀寫數組中的第一個數據。以此類推,要想訪問數組中的第二個數據,數組下標就應該是1,要想訪問第n個數據,下標就應該是n-1。例如:
// 數組中的第二個數據表示老板娘的工資, 給定下標1訪問 arrSalary[1] = 99999; // 往後依次就是各個員工的工資 arrSalary[2] = 2000; // …在使用數組下標時,另外需要注意的一個地方是,下標必須大於等於0小於數組定義時的個數常數。簡單來講,一個長度為n的數組,其下標的取值范圍是[0,n-1]。如果下標的取值超出了這個范圍,就會訪問到數組以外的內存區域,引起數組訪問越界的錯誤,輕則造成數據讀寫錯誤,嚴重時甚至會導致程序崩潰。並且,這種錯誤極具隱蔽性,往往很難發現。所以我們一開始在使用數組時,就一定要時刻注意防止數組訪問越界。數組下標與數組中數據元素的對應關系如下圖所示:
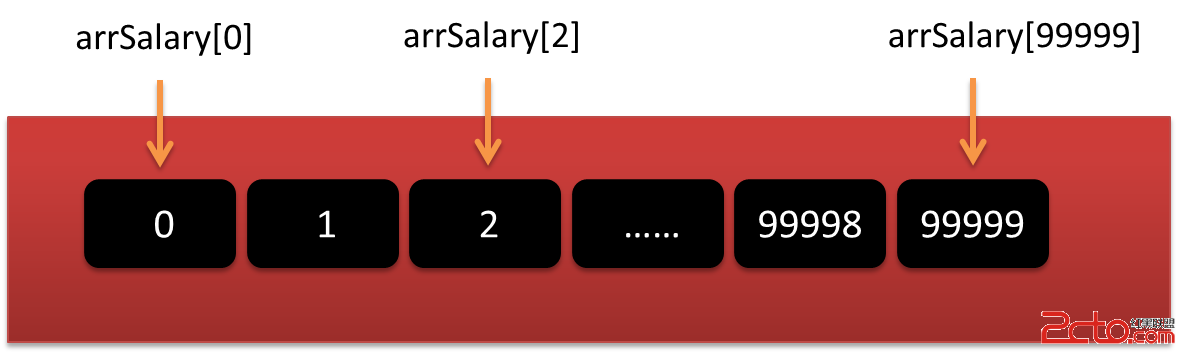
圖3-3 數組中數據元素與下標的對應關系
同樣的道理,對於二維數組、三維數組等多維數組,同樣可以通過給定多個下標來訪問數組中的數據元素。例如:
// 第一個年級,第二個班級,第26位同學的成績是82 arrScore[0][1][25] = 82;這裡我們可以看到,通過下標對數組中元素進行讀寫訪問,就像使用一個單獨的變量一樣簡單。有了數組的幫忙,我們在描述大量性質相同的數據時,就無須單獨地定義多個相同類型的變量,而只需定義一個能容納需要處理數據的數組,然後通過不同的下標就可以訪問到不同的數據,也就像擁有多個單獨變量一樣方便。