C++ 編譯花了大量精力使得class和原始類(primitive types)的用法一致。比如array的應用:
A a[100];// A is class
int b[100];
雖然a是用戶定義的類的對象,但是用起來與整數型的array相比並無差別。我們現在看看語義上的差別。
如果A是具有值語義的POD(參見我關於值語義的博客:http://www.cnblogs.com/ly8838/p/3929025.html ),測試顯示A 的創建和讀寫與一般變量沒有任何差別,當然性能也不會有差別。
也就是說,A a[3] ;和 A a1, a2,a3; 在語義上完全一樣,也沒有絲毫性能上的區別。
我們有一個簡單的struct:
struct StackObject
{
int _a;
int _b;
StackObject(): _a(0), _b(1)
{
}
};
和簡單的測試函數:
void TestArraySemantics()
{
StackObject sa[10]; //line 1:call vector constructor iterator
sa[0]._a= 1;
sa[9]._b = 10;
}
在VC++2010中運行時,我們看到line1調用了編譯自生的函數。這是一個通用的“矩陣構造循環(vector constructor iterator)”:
它的大致實施如下:
void Vector_constructor_iterator(
int array_size,
int array_element_size,
void (*Ctr)(void *addr),
char *arrayStartAddress)
{
for(int i = 0; i < array_size; ++i)
{
void *objAddr = arrayStartAddress + i * array_element_size;
Ctr(objAddr);
}
}
這是一個典型的 C 函數,它將 StackObject 的構造函數作為函數指針進行調用。
從這個函數來看,它使得A a[3]; 和A a1,a2, a3; 的語義發生了根本變化。我們不但要調用編譯產生的函數,還要用指針間接地調用StackObject的構造函數。測試結果顯示,用array比不用array的“構造”速度大約下降30%。考慮到array的應用價值,這個速度的下降是可以理解和接受的。
加了destructor後,A a[10] 的語義又有了新的變化。如果讀了我的上篇關於異常處理的博客(http://www.cnblogs.com/ly8838/p/3961119.html )可知:編譯必須保證所有創建的object“全部”被摧毀,所以它必須“記住”創建過程中的熱點。
我們加另一個dummy 類,來測試destructor對array 的影響:
struct StackObject2
{
int _a;
int _b;
StackObject2(): _a(0), _b(1)
{
}
~StackObject2()
{
_a = _b = 0;
}
};
我們的測試函數改為
void TestArraySemantics()
{
clock_t begin = clock();
for (int i = 0; i < 100000; ++i)
{
StackObject sa[3]; //line1:test without d’tr
sa[0]._a= 1;
sa[1]._b = 2;
sa[2]._b = 3;
}
clock_t end = clock();
auto spent = double(end - begin) / CLOCKS_PER_SEC;
printf("spent for 'array' is %f\n", spent);
begin = clock();
for (int i = 0; i < 100000; ++i)
{
StackObject2 sa[3]; //line2:test with d’tr
sa[0]._a= 1;
sa[1]._b = 2;
sa[2]._b = 3;
}
end = clock();
spent = double(end - begin) / CLOCKS_PER_SEC;
printf("spent for 'array with dtro' is %f\n", spent);
begin = clock();
for (int i = 0; i < 100090; ++i)
{
StackObject sa1, sa2, sa3; //line3:test without array
sa1._a= 1;
sa2._b = 2;
sa3._b = 3;
}
end = clock();
spent = double(end - begin) / CLOCKS_PER_SEC;
printf("spent for 'none-array' is %f\n", spent);
}
上面的line2試圖創建帶有destructor的StackObject2類的array. 在VC++,我們注意到這時編譯產生另一名字稍稍不同的函數“eh vector constructor iterator”,然而察看生成的代碼,發現它和vector constructor iterator大大不同了。它的偽碼大致如此:
void Vector_constructor_iterator_with_dtor(
int array_size,
int array_element_size,
void (*Ctr)(void *addr),
void (*Dtr)(void *addr),
char *arrayStartAddress)
{
int lastCreated = -1;
try
{
for(int i = 0; i < array_size; ++i)
{
void *objAddr = arrayStartAddress + i * array_element_size;
Ctr(objAddr);
lastCreated = i;
}
}
catch(...)
{
// destroy partially created array in case or fault
for(int i = 0; i <= lastCreated; ++i)
{
void *objAddr = arrayStartAddress + i * array_element_size;
Dtr (objAddr);
}
}
}
比較偽碼我們看出:Vector_constructor_iterator_with_dtor 和 Vector_constructor_iterator 的主要區別是增加了異常處理的機制,用來銷毀“已經構造”的矩陣元素。
運行 TestArraySemantics 表明,帶有destructor的類的array構造速度下降了近 300%。
所以,去除不必要的destructor的重要性又一次充分體現。
C++ built-in array對class object的支持是十分重要的語言構造,它是C++把class object和原始變量同樣對待的又一反映,它大大增加了C++的附加值。
然而我們一如既往,需要對C++這一語言構造的語義深入了解。以便正確使用C++ built-in array。
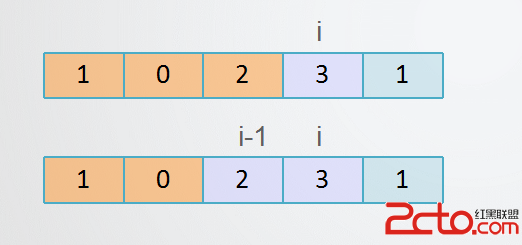
就是交換array[k]和array[i]中的數據。
為什麼要這樣呢?
生活中你想想,一個杯子裡是酒精,一個杯子裡是牛奶,如何把他們相互交換,肯定要借助一個空杯子中轉一下。 例如:A 酒精 B牛奶 C空杯子
C<-A
A<-B
B<-C
這裡t就是那個空杯子。一個道理!
一維的動態數組就不說了,給你一個二維動態數組的例子:
#include "stdafx.h"
#include <iostream>
using namespace std;
int main()
{
int r; //行數
int c; //列數
cout<<"Please input the number of rows of the dynamic array: ";
cin>>r; //輸入行數
cout<<"Please input the number of columns of the dynamic array: ";
cin>>c; //輸入列數
//創建二維動態數組
int **p=new int*[r];
for(int i=0;i<r;i++)
{
p[i]=new int[r];
}
cout<<"The array named p["<<r<<"]["<<c<<"] is created."<<endl;
//循環賦值
int temp;
for(int i=0;i<r;i++)
{
for(int j=0;j<c;j++)
{
cout<<"Please input a value of p["<<i<<"]["<<j<<"] in the array: ";
cin>>temp;
*(*(p+i)+j)=temp; //尋址賦值
}
}
//循環顯示
cout<<"The dynamic array is "<<endl;
for(int i=0;i<r;i++)
{
for(int j=0;j<c;j++)
{
cout<<*(*(p+i)+j)<<" "; //尋址讀取
}
cout<<endl;
}
return 0;
}...余下全文>>