提到輸入輸出流,作為CPPer很自然的就會想到std::iostream,對於文本流的處理,iostream可以說足夠強大,應付一般復雜度的需求毫無壓力。對二進制流處理卻只能用“簡陋”來形容,悲催的是,作為一個在多媒體軟件領域默默耕耘多年的碼農日常打交道最多的偏偏就是二進制流。
前些年流行過一本書叫做什麼男人來自火星女人來自金星之類的,同樣的,如果說文本流來自火星那二進制流就是來自金星。對一個文本流,我們可能期望這樣的接口函數:
1 string text = stream.get_line(); // 基礎接口 2 string word = stream.get_word(); // 增強接口
而對二進制流,我們期望的接口可能是這個樣子的:
1 int read_bytes = stream.read(buffer, size); // 基本接口 2 int value = stream.read_int32(); // 增強接口
做為iostream靈魂的插入/提取運算符("<<"/">>")重載對文本流來說是神一般的存在,但在二進制流中卻完全無法使用,因為二進制流需要精確到byte(甚至bit)的控制,所以會有下面這樣的接口:
int v1 = stream.read_uint16(); // 讀取short int int v2 = stream.read_int16(); // 讀取unsigned short int int v3 = stream.read_uint24(); // 讀取3字節無符號整型,沒錯是3字節24位 int v4 = stream.read_int24(); // 想想這個函數有多變態!
基於編譯期推導的運算符重載很難滿足類似的需求。在我看來,把兩類方法合並在同一個類中是得不償失的,核心需求幾乎沒什麼相似之處,非核心的需求則無關緊要,而且基本上不會有既是文本流又是二進制流的情況出現。iostream偏偏就這麼做了,對此,只(wo)能(cuo)呵(le)呵(ma)了。
二進制流按照流的方向可以劃分為輸入流和輸出流(廢話);按另外一個緯度上則可以劃分為順序訪問流和可隨機訪問流,兩者最主要的區別是是否支持定位操作(seek),前者不支持,後者支持,比如標准輸入輸出流就是順序訪問流,而文件流一般都是可隨機訪問流。站在更高的層次上來理解,順序訪問流內置了一個時間箭頭,既不能回頭也不能跳躍,可隨機訪問流則是內置的空間軸,沒有方向性(或者說方向性很弱),如果你願意完全可以從一個文件的尾部往頭部讀。因此帶有時間屬性的實時流一般是順序訪問流,比如錄音、錄屏產生的數據流,比如在線直播視頻的直播流。
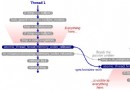
兩個緯度各兩個分類共四種組合,由此我們就可以設計一個newbility的架構出來了:
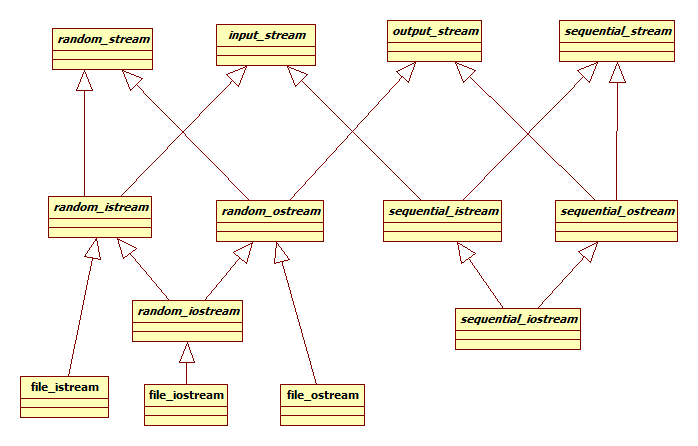
哈哈,是不是很強大,是不是……怕了?……怕了就對了,這還只是抽象接口類,如果再把實現類以及各種派生考慮進去,這個系統的復雜度至少還要增加兩倍。
……
上面的圖是開個玩笑,圖中的系統是典型的臆造抽象,連過度設計都算不上,甚至不如沒有設計。雖然誇張了些,但現實中也不是沒有犯了類似錯誤的系統,比如DirectShow的base classes內部的實現代碼就頗有些神似的地方(說出這樣的話,我對DirectShow的怨念得有多深啊……)。
解決任何問題的第一步首先就是簡化問題,也就是抓住主要矛盾,忽略次要矛盾。至少在曾經某一段時間,CPPer特別追求精致的設計,而精致的設計往往首先就把簡單的問題復雜化了,還記得那個經典的C++版的Hello World嗎?精致設計的目的本是為了代碼復用,而現實卻是:越簡單的代碼越容易復用,越是精心設計的代碼越容易因為復雜而難以復用。回到我們的問題,首先要找到主要矛盾,也就是核心需求:一組能應付大部分日常任務的簡單的輸入和輸出流,注意,這裡用的是“輸入和輸出流”而不是“輸入輸出流”。事實上,在實際的開發工作中很少會遇到要求一個流即是輸入流又是輸出流的情況,如果遇到又往往是因為業務需求復雜,此種情況下即使專門寫一個應對特殊需求的流也不是不可接受。
所以,“既是輸入流又是輸出流”這種需求被我們作為次要矛盾砍掉了,尚未考慮清楚的繼承關系也暫時砍掉,文件流之類的派生擴展也砍掉,系統的剩余部分就簡單的一目了然了:

只有四個孤零零的抽象類。輸出流和輸入流類似但無關聯,所以我們以輸入流為例做進一步的考察,也就是兩個抽象類:random_istream和sequential_istream。前面說過了,順序訪問流和可隨機訪問流最主要的區別是順序訪問流不支持支持定位操作(seek)而可隨機訪問流支持,也就是說,如果sequential_istream設計成下面這樣:
1 class sequential_istream
2 {
3 public:
4 virtual void read(void* buffer, int bytes) = 0;
5 };
則random_istream是這樣的:
class random_istream
{
public:
virtual void read(void* buffer, int bytes) = 0;
virtual void seek(int offset) = 0;
};
發現什麼沒有?random_istream是sequential_istream的超集,這意味著可以讓random_istream從sequential_istream繼承下來,既不必設計成兩個孤零零的類,也不必為了通用強行給兩個類提取一個公共基類。從概念上講也是完美的,一個可隨機訪問的流當然可以當作順序流來訪問,這是典型的“is-a”的關系。重新調整後的設計如下:
1 class input_stream
2 {
3 public:
4 virtual void read(void* buffer, int bytes) = 0;
5 };
6
7 class random_istream : public input_stream
8 {
9 public:
10 virtual void seek(int offset) = 0;
11 };
這裡去掉順序流的sequential關鍵字,讓概念的繼承邏輯更加順暢。
事實上,還有另外一種設計方案,可以把input_stream設計成胖接口(fat interface),同時支持順序流和可隨機訪問流:
1 class input_stream
2 {
3 public:
4 virtual void read(void* buffer, int bytes) = 0;
5 virtual void seek(int offset) = 0;
6 virtual bool seekable() const = 0;
7 };
注意seekable這個方法,它返回了一個布爾值指示seek方法是否有效,有效表明這是一個可隨機訪問的流,無效則是順序流。
我們沒有采用這個方案,雖然少了一層繼承關系看起來簡單了,實際應用卻並不比前面的方案簡單。seekable在語義上是一種狀態屬性(有這個說法嗎)表示對象的一類狀態,一個布爾型可以表示兩種狀態,每增加一個則應用復雜度就翻一倍,呈指數增長(不要信我,我隨口亂說的)。這裡雖然只有一個狀態屬性,但已經足以給我們造成不少的困擾了:
上面的問題也是胖接口固有的問題,所以一定要慎重使用胖接口,這次我們選擇了拋棄。
把各種派生類和各種輔助類都加上,得到最終的結構圖:
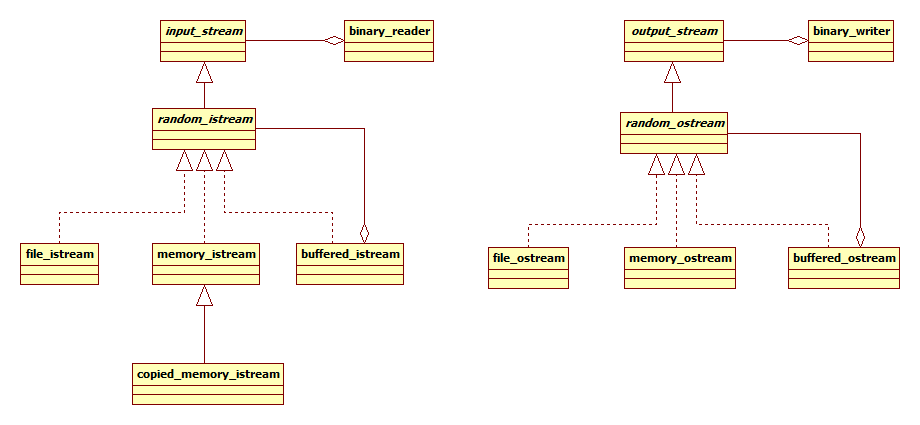
至此,我們的工作已基本完成,剩下的都是無聊的體力活。
input_stream和random_istream接口:
1 class input_stream
2 {
3 public:
4 virtual void read(void* buffer, uint32_t bytes) = 0;
5 virtual void skip(uint32_t bytes) = 0;
6 virtual uint64_t tell() const = 0;
7 };
8
9
10 class random_istream : public input_stream
11 {
12 public:
13 virtual void seek(int64_t offset, seek_origin origin) = 0;
14 virtual uint64_t size() const = 0;
15 };
注意skip方法,這個方法用於在順序讀入時跳過指定字節數,其功能也可以通過read後丟棄數據的方式實現,在random_istream中則可以直接使用seek方法實現,最終決定加入這個方法主要是為了使用方便,在效率上則與當前流的最優替代方式相當。
output_stream和random_ostream:
1 class output_stream
2 {
3 public:
4 virtual void write(void* buffer, uint32_t bytes) = 0;
5 virtual void flush() = 0;
6 virtual uint64_t tell() const = 0;
7 };
8
9 class random_ostream : public output_stream
10 {
11 public:
12 virtual void seek(int64_t offset, seek_origin origin) = 0;
13 };
binary_reader和binary_writer兩個類是對input_stream和output_stream的擴展,采用外部擴展的方式相對於繼承擴展更加靈活。如果用繼承擴展的話binary_reader究竟從input_stream還是random_istream繼承呢,或者是把binary_reader設計成獨立的接口類,實現類比如file_istream同時繼承binary_reader和random_istream呢?這些都是讓人糾結的問題,並且每一種方案都不完美。外部擴展的方式則堪稱完美,實現起來也簡單,只要給binary_reader塞一個input_stream的指針就可以了,用起來就像下面這個樣子:
1 input_stream* ist = ... 2 3 binary_reader reader(ist); 4 5 int v1 = reader.read_uint8(); 6 7 reader.skip(4); 8 int v2 = reader.read_uint16_be(); 9 ... 10 11 // seek操作也可以支持 12 13 random_istream* ist = ... 14 15 binary_reader reader(ist); 16 17 int v1 = reader.read_uint8(); 18 19 ist->seek(4, see_origin::current); 20 int v2 = reader.read_uint16_be(); 21 ...
binary_reader的完整聲明大體如下,binary_writer與之類似:
1 class binary_reader
2 {
3 public:
4 binary_reader(input_stream* stream);
5
6 void read(void* buffer, uint32_t read_bytes);
7 void skip(uint32_t offset);
8
9 uint64_t tell() const;
10
11 uint8_t read_uint8();
12
13 uint16_t read_uint16_be();
14 uint32_t read_uint24_be();
15 uint32_t read_uint32_be();
16 uint64_t read_uint64_be();
17
18 uint16_t read_uint16_le();
19 uint32_t read_uint24_le();
20 uint32_t read_uint32_le();
21 uint64_t read_uint64_le();
22
23 ....
24
25 private:
26 input_stream* _stream;
27 };
……
花了一周的業余時間總算把這一篇寫完了,一個簡單的設計方案想講清楚卻也不是那麼容易。這個方案特別是具體接口函數的設計還很不完善,需要在實際應用的過程中逐漸豐富改進,當然了,在一個簡單的方案上做改進想來也不會太麻煩。下一篇,准備寫一下這個方案背後的東西——錯誤處理,具體來講是基於異常的錯誤處理方案。
流是一種形象的說法。
如:cin >> i >> j;是輸入數據到i和j,直觀上是從cin這個對象流出來的。
cout << i << j;則是輸出i和j到對象cout
"<<"和">>"是一種特殊的函數,operator <<(),如果取名為output,
則cout << i <<j;可以表示為 output(output(cout,i),j);
只不過<<看起來簡潔形象多了。
流沒什麼玄機,就是用於輸入輸出的一些類。
在C語言中,輸入輸出是使用語句scanf()和printf()來實現的,而C++中是使
用類來實現的。
#include iostream.h
main() //C++中main()函數默認為int型,而C語言中默認為void型。
{
int a;
cout< cin>>a; /*輸入一個數值*/
cout< return 0;
}
cin,cout,endl對象,他們本身並不是C++語言的組成部分。雖然他們已經是AN
SI標准C++中被定義,但是他們不是語言的內在組成部分。在C++中不提供內在
的輸入輸出運算符,這與其他語言是不同的。輸入和輸出是通過C++類來實現的
,cin和cout是這些類的實例,他們是在C++語言的外部實現。
在C++語言中,有了一種新的注釋方法,就是‘//’,在該行//後的所有說明都
被編譯器認為是注釋,這種注釋不能換行。C++中仍然保留了傳統C語言的注釋
風格/*……*/。
C++也可采用格式化輸出的方法:
#include iostream.h
int main()
{
int a;
cout< cin>>a;