本文地址:http://www.cnblogs.com/archimedes/p/c-library-ctype.html,轉載請注明源地址。
ctype.h是C標准函數庫中的頭文件,定義了一批C語言字符分類函數(C character classification functions),用於測試字符是否屬於特定的字符類別,如字母字符、控制字符等
我們經常將字符排序並分成不同的類別,為了識別一個字母,可以編寫:
if('A' <= c && c <= 'Z' || 'a' <= c && c <= 'z')
......
當執行字符集是ASCII碼的時候,可以得到正確的結果,但是這種慣用用法不適合其他字符集
同樣,為了判斷一個數字,可以這樣編寫:
if('0' <= c && c <= '9')
......
判斷空白,可以編寫代碼:
if(c == ' ' || c == '\t' || c == '\n')
......
但是問題來了,我們很快就會厭倦代碼中充斥著類似這樣的判斷語句而變長,最容易聯想的解決辦法是引入函數來替代這些判斷語句,於是將出現如下的代碼:
if(isalpha(c))
...
if(isdigit(c))
...
if(isspace(c))
...
貌似問題得到了解決,但是考慮一個典型的文本處理程序對輸入流中的每一個字符會平均調用3次這樣的函數,就會嚴重影響程序的執行效率
於是想到進一步的改進,考慮使用宏來替代這些函數,
#define isdigit(x) ((x) >= '0' && (x) <= '9')
這會產生問題,如宏參數x具有副作用;例如,如果調用isdigit(x++)或isdigit(run_some_program()),可能不是很顯然,isdigit的參數將被求值兩次。早期版本的Linux就使用了這種潛在犯錯的方法。關於宏的缺點,本文就不贅述。
為保障安全和代碼緊湊,進一步的改進,使用一個或多個轉換表的宏集合,每個宏有如下形式:
#define _XXXMASK 0x... #define isXXX(c) (_Ctytable[c] & _XXXMASK)
字符c編入以_Ctytable命名的轉換表索引中,每個表項的不同位以索引字符為特征。如果任何一個和掩碼_XXXXMASK相對應的位被設置了,那個字符就要在測試類別中,對所有正確的參數,宏展開成一個緊湊的非零表達式。
這種方法的弊端:當宏的參數不在它的定義域內,就會訪問轉換表外的存儲空間
<ctype.h>定義的宏如下表所示:
isalnum
是否為字母數字
isalpha
是否為字母
islower
受否為小寫字母
isupper
是否為大寫字母
isdigit
是否為數字
isxdigit
是否為16進制數字
iscntrl
是否為控制字符
isgraph
是否為圖形字符(例如,空格、控制字符都不是)
isspace
是否為空格字符(包括制表符、回車符、換行符等)
isblank
是否為空白字符 (C99/C++11新增)(包括水平制表符)
isprint
是否為可打印字符
ispunct
是否為標點
tolower
轉換為小寫
toupper
轉換為大寫
下圖來自Plauger和Brodie的Standard C:
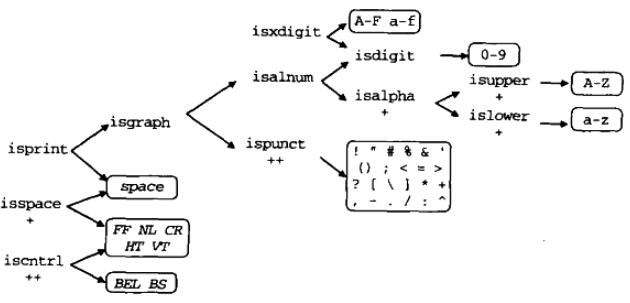
P.J.Plauger版本C標准庫 Ctype 中判斷字符是否屬於某個類型,主要是通過轉換表來實現的
以判斷是否為小寫字母為例:
/* ctype.h */ #ifndef _CTYPE #define _CTYPE /* _Ctype 轉換位 */ #define _XA 0x200 /* extra alphabetic */ #define _XS 0x100 /* extra space */ #define _BB 0x80 /* BEL, BS, etc. */ #define _CN 0x40 /* CR, FF, HT, NL, VT */ #define _DI 0x20 /* '0' - '9' */ #define _LO 0x10 /* 'a' - 'z' */ #define _PU 0x08 /* punctuation */ #define _SP 0x04 /* space */ #define _UP 0x02 /* 'A' - 'Z' */ #define _XD 0x01 /* '0' - '9', 'A' - 'F', 'a' - 'f' */ /* 聲明外部的 _Ctype 轉換表 */ extern const short *_Ctype; /* 判斷是否為小寫字母的帶參數宏 islower */ #define islower(c) (_Ctype[(int)(c)] & _LO) // 其余省略 ... #endif
_Ctype 轉換表:
/* xctype.c _Ctype 轉換表 -- ASCII 版 */
#include <limits.h>
#include <stdio.h>
#include "ctype.h"
#if EOF != -1 || UCHAR_MAX != 255
#error WRONG CTYPE table
#endif
/* 組合位 */
#define XDI (_DI|_XD)
#define XLO (_LO|_XD)
#define XUP (_UP|_XD)
/* 轉換表 */
static const short ctype_tab[257] = { 0, /* EOF */
_BB, _BB, _BB, _BB, _BB, _BB, _BB, _BB,
_BB, _CN, _CN, _CN, _CN, _CN, _BB, _BB,
_BB, _BB, _BB, _BB, _BB, _BB, _BB, _BB,
_BB, _BB, _BB, _BB, _BB, _BB, _BB, _BB,
_SP, _PU, _PU, _PU, _PU, _PU, _PU, _PU,
_PU, _PU, _PU, _PU, _PU, _PU, _PU, _PU,
XDI, XDI, XDI, XDI, XDI, XDI, XDI, XDI,
XDI, XDI, _PU, _PU, _PU, _PU, _PU, _PU,
_PU, XUP, XUP, XUP, XUP, XUP, XUP, _UP,
_UP, _UP, _UP, _UP, _UP, _UP, _UP, _UP,
_UP, _UP, _UP, _UP, _UP, _UP, _UP, _UP,
_UP, _UP, _UP, _PU, _PU, _PU, _PU, _PU,
_PU, XLO, XLO, XLO, XLO, XLO, XLO, _LO,
_LO, _LO, _LO, _LO, _LO, _LO, _LO, _LO,
_LO, _LO, _LO, _LO, _LO, _LO, _LO, _LO,
_LO, _LO, _LO, _PU, _PU, _PU, _PU, _BB,
};
const short *_Ctype = &ctype_tab[1];
舉一個例子來說明:
當判斷‘a’是否為小寫字母的時候,使用宏islower,通過宏替換,也即執行(_Ctype[(int)(c)] & _LO)
預處理之後,假設當前的c是'a'那麼變成了: (_Ctype[(int)('a')] & _LO)
字符'a'的值為97所以接下來便是: (_Ctype[97] & _LO)_Ctype[97]的轉換宏是 _LO ,通過查_Ctype 轉換表, _LO 的值又是 0x10,所以最後是:
(_LO & _LO) ----> 0x10 & 0x10 ----> 1, 說明當前字符為小寫字母
其他的字符的判斷都可以通過類似的替換與‘&’得到,不一一贅述。
附上linux內核中的ctype.h實現,基本原理相似

《C標准庫》
Plauger和Brodie的《Standard C》