【本文鏈接】
http://www.cnblogs.com/hellogiser/p/special-expressions.html
假定x = 9999即 10011100001111
答案: 8
思路: 將x轉化為2進制,看含有的1的個數。
注: 每執行一次x = x&(x-1),會將x用二進制表示時最右邊的一個1變為0,因為x-1將會將該位(x用二進制表示時最右邊的一個1)變為0。
(x&y)+((x^y)>>1)的功能是取兩個數的平均值 (x+y)/2 很牛X的一個思路,雖然不算高效,但如果在匯編中的話,這種方法可以不產生高位溢出。
大概思路應該是這樣: x=x1+x2+x3,y=y1+y2+y3. (x+y)/2=(x1+y1)/2+(x2+y2)/2+(x3+y3)/2. 把x和y裡對應的每一位(指二進制位)都分成三類,每一類分別計算平均值,最後匯總。其中,一類是x,y對應位都是1,用x&y計算其平均值;一類是x,y中對應位有且只有一位是1,用(x^y)>>1計算其平均值;還有一另是x,y中對應位均為0,計算得0。
下面我再分別說明一下前兩種情況是怎樣計算的:
1) 第一部分,x,y對應位均為1,相加後再除以2還是原來的數,如兩個00001111相加後除以2仍得00001111。
2) 第二部分,x,y對應位有且只有一位為1,用“異或”運算提取出來,然後>>1(右移一位,相當於除以2),即到到第二部分的平均值。
3) 第三部分,x,y對應位均為零,因為相加後再除以二還是0,所以不用計算。
4) 三部分匯總之後就是(x&y)+((x^y)>>1)。
順便解釋一下前面說到可以避免溢出。 假設x,y均為unsigned char型數據(0~255,占用一字節),顯然,x,y的平均數也在0~255之間,但如果直接x+y可能會使結果大於255,這就產生溢出,雖然最終結果在255之內,但過程中需要額外處理溢出的那一位,在匯編中就需要考慮這種高位溢出的情況,如果(x&y)+((x^y)>>1)計算則不會。
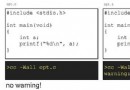
C++ Code 1(int)a實際上是以浮點數a為參數構造了一個整型數,該整數的值是1。
(int&)a則是告訴編譯器將a當作整數看(並沒有做任何實質上的轉換)。因為1以整數形式存放和以浮點形式存放其內存數據是不一樣的,因此兩者不等。
對b的兩種轉換意義同上,但是0的整數形式和浮點形式其內存數據是一樣的,因此在這種特殊情形下,兩者相等(僅僅在數值意義上)。
注意,程序的輸出會顯示(int&)a=1065353216,這個值是怎麼來的呢?前面已經說了,1以浮點數形式存放在內存中,按ieee754規定,其內容為0x0000803F(已考慮字節反序)。這也就是a這個變量所占據的內存單元的值。當(int&)a出現時,它相當於告訴它的上下文:“把這塊地址當做整數看待!不要管它原來是什麼。”這樣,內容0x0000803F按整數解釋,其值正好就是1065353216(十進制數)。
【本文鏈接】
http://www.cnblogs.com/hellogiser/p/special-expressions.html