根據協議 http://www.rfc-editor.org/rfc/rfc4180.txt 開發
CSV 語法的規則
file = [header CRLF] record *(CRLF record) [CRLF] header = name *(COMMA name) record = field *(COMMA field) name = field field = (escaped / non-escaped) escaped = DQUOTE *(TEXTDATA / COMMA / CR / LF / 2DQUOTE) DQUOTE non-escaped = *TEXTDATA COMMA = %x2C CR = %x0D ;as per section 6.1 of RFC 2234 [2] DQUOTE = %x22 ;as per section 6.1 of RFC 2234 [2] LF = %x0A ;as per section 6.1 of RFC 2234 [2] CRLF = CR LF ;as per section 6.1 of RFC 2234 [2] TEXTDATA = %x20-21 / %x23-2B / %x2D-7E
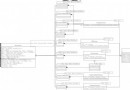
CSV 解析有限狀態機

編碼實現
出於降低代碼圈復雜度的考慮,INIT 狀態與 FIELD_END 狀態合並,兩個狀態唯一的區別是:
當前行數據為空時,INIT 狀態可以在解析的過程中識別出, FIELD_END 則不能解析時識別。
針對該問題,可以在解析前判斷當前行是否為空。不影響代碼邏輯與性能。
引包如下:
#include <fstream> #include <iostream> #include <vector> #include <string>
有限狀態機實現代碼:
typedef enum CSV_RECORD_STATUS
{
// CSV_RECORD_STATUS_INIT = 1001, // use CSV_RECORD_STATUS_FIELD_END instead
CSV_RECORD_STATUS_ESCAPED_PRE = 1002,
CSV_RECORD_STATUS_ESCAPED_SUB,
CSV_RECORD_STATUS_ESCAPED_FIELD,
CSV_RECORD_STATUS_NON_ESCAPED_FIELD,
CSV_RECORD_STATUS_FIELD_END,
CSV_RECORD_STATUS_ERROR_BUTT
}CSV_RECORD_STATUS;
int TransferNonEscapedField(char ch)
{
switch ( ch )
{
case DELIMITER:
return CSV_RECORD_STATUS_FIELD_END;
case QUOTE:
return CSV_RECORD_STATUS_ERROR_BUTT;
default:
return CSV_RECORD_STATUS_NON_ESCAPED_FIELD;
}
}
int TransferEscapedField(char ch)
{
switch ( ch )
{
case QUOTE:
return CSV_RECORD_STATUS_ESCAPED_SUB;
default:
return CSV_RECORD_STATUS_ESCAPED_FIELD;
}
}
int TransferEscapedPre(char ch)
{
switch ( ch )
{
case QUOTE:
return CSV_RECORD_STATUS_ESCAPED_SUB;
default:
return CSV_RECORD_STATUS_ESCAPED_FIELD;
}
}
int TransferEscapedSub(char ch)
{
switch ( ch )
{
case DELIMITER:
return CSV_RECORD_STATUS_FIELD_END;
case QUOTE:
return CSV_RECORD_STATUS_ESCAPED_FIELD;
default:
return CSV_RECORD_STATUS_ERROR_BUTT;
}
}
int TransferFieldEnd(char ch)
{
switch ( ch )
{
case QUOTE:
return CSV_RECORD_STATUS_ESCAPED_PRE;
case DELIMITER:
return CSV_RECORD_STATUS_FIELD_END;
default:
return CSV_RECORD_STATUS_NON_ESCAPED_FIELD;
}
}
int RecordStatus(int preStatus, char ch)
{
switch ( preStatus )
{
//case CSV_RECORD_STATUS_INIT:
// return TransferInit(ch);
// Field
case CSV_RECORD_STATUS_NON_ESCAPED_FIELD:
return TransferNonEscapedField(ch);
case CSV_RECORD_STATUS_ESCAPED_FIELD:
return TransferEscapedField(ch);
// Quote in escaped filed
case CSV_RECORD_STATUS_ESCAPED_PRE:
return TransferEscapedPre(ch);
case CSV_RECORD_STATUS_ESCAPED_SUB:
return TransferEscapedSub(ch);
// Field End
case CSV_RECORD_STATUS_FIELD_END:
return TransferFieldEnd(ch);
// Error
default:
return CSV_RECORD_STATUS_ERROR_BUTT;
}
}
使用有限狀態機解析 CSV:
const char DELIMITER = ','; // COMMA
const char QUOTE = '"';
bool hasError(int status)
{
return (CSV_RECORD_STATUS_ERROR_BUTT == status);
}
bool isTextData(int status)
{
return (CSV_RECORD_STATUS_ESCAPED_FIELD == status) || (CSV_RECORD_STATUS_NON_ESCAPED_FIELD == status);
}
bool isFieldEnd(int status)
{
return (CSV_RECORD_STATUS_FIELD_END == status);
}
void FieldEnd(std::vector<std::string>& record, std::string& field)
{
//std::cout << field << " || ";
record.push_back(field);
field.clear();
}
void RecordHandler(std::vector<std::string>& record, int sequence)
{
//if ( 0 == (sequence % 10000) )
{
std::cout << std::endl << "Records: " << sequence << std::endl;
}
record.clear();
}
bool LastFieldEnd(int status, std::vector<std::string>& record, std::string& field)
{
// error check
if ( (CSV_RECORD_STATUS_ESCAPED_SUB != status) && (CSV_RECORD_STATUS_NON_ESCAPED_FIELD != status) )
{
return false;
}
FieldEnd(record, field);
return true;
}
int CCsvParser::Parse(std::string filename)
{
std::ifstream fin;
fin.open(filename, std::ios::in);
if (!fin.is_open())
{
return false;
}
std::string header;
std::getline(fin, header);
// TODO: deal with header
int recordCount = 0; // count without header
std::string lineData;
std::vector<std::string> record;
std::string field;
bool newField = true;
while(std::getline(fin, lineData))
{
recordCount++;
int curStatus = CSV_RECORD_STATUS_FIELD_END;
record.clear();
field.clear();
// parser line to record
// std::cout << lineData << std::endl;
for (size_t i =0; i < lineData.size(); i++)
{
curStatus = RecordStatus(curStatus, lineData[i]);
if (hasError(curStatus))
{
break; // next line
}
else if (isTextData(curStatus))
{
field.push_back(lineData[i]);
}
else if (isFieldEnd(curStatus))
{
FieldEnd(record, field);
}
}
// line end, deal with last field
LastFieldEnd(curStatus, record, field);
RecordHandler(record, recordCount);
}
fin.close();
return recordCount;
}