一天,我在思考 NSArray 枚舉方法 (也稱迭代方法): Mac OS X 10.6 和 iOS 4 帶來了以塊(block)組成的美麗新世界,enumerateObjectsUsingBlock: 方法隨之而來。我感覺這個方法要慢於快速枚舉 (for (object in array) { ... }),因為有總體開銷,但我並不能確定。因此我決定做一次性能測評。
都有哪些枚舉方法?
總體來說,我們有4種可以使用的枚舉方法 (參考 Mike Ash 的 周五常見問題 2010-04-09: Objective-C 的枚舉方法對比)。
1、objectAtIndex: enumeration 使用一個 for 循環,遞增循環變量,然後用 [myArray objectAtIndex:index] 來訪問元素。這是最基本的枚舉形式。
- NSUInteger count = [myArray count];
- for (NSUInteger index = 0; index < count ; index++) {
- [self doSomethingWith:[myArray objectAtIndex:index]];
- }
2、NSEnumerator 外部迭代(external iteration)的形式: [myArray objectEnumerator] 返回一個對象,這個對象有 nextObject 方法。我們可以循環調用這個方法,直到返回 nil 為止。
- NSEnumerator *enumerator = [myArray objectEnumerator];
- id object;
- while (object = [enumerator nextObject]) {
- [self doSomethingWith:object];
- }
3、NSFastEnumerator The idea behind 快速枚舉 的思想是利用 C 數組快速訪問 來優化迭代。不僅它理論上比傳統的 NSEnumerator 更快,而且 Objective-C 2.0 提供了這種簡明的語法:
- id object;
- for (object in myArray) {
- [self doSomethingWith:object];
- }
4、Block enumeration塊枚舉)引入 blocks 後出現的方法,它可以基於塊來迭代訪問一個數組。它的語法沒有快速枚舉那麼簡潔,但它有一個有趣的特性: 並發枚舉。如果枚舉的順序並不重要,而且實施的處理可以並發進行,不用鎖,這種方法可以在多核系統上帶來相當明顯的效率提升。詳情參考 並發枚舉一節。
- [myArray enumerateObjectsUsingBlock:^(id object, NSUInteger index, BOOL *stop) {
- [self doSomethingWith:object];
- }];
- [myArray enumerateObjectsWithOptions:NSEnumerationConcurrent usingBlock:^(id obj, NSUInteger idx, BOOL *stop) {
- [self doSomethingWith:object];
- }];
線性枚舉
首先,我們討論一下線性枚舉:一個項目接著前一個。
圖表
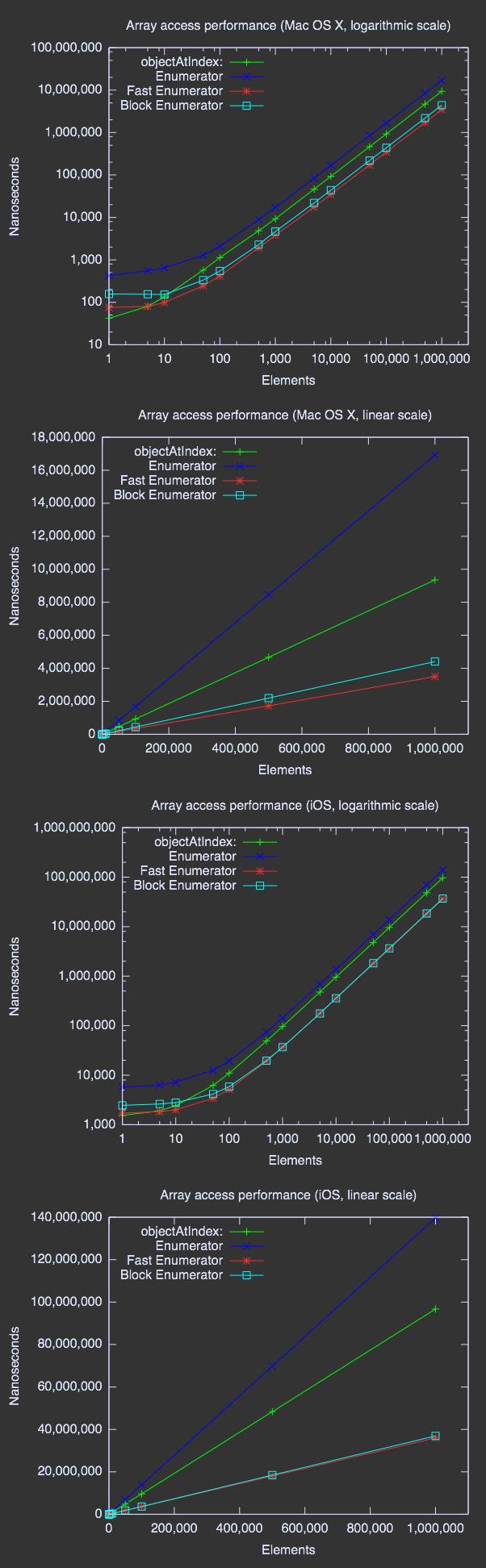
結論
fast enumeration和NSEnumeration之間的區別在很多地方已經非常明顯:對於iPhone 4S,前者花費約0.037秒而後者需要0.140秒。這已經相差了3.7陪。
奇怪的一點
首次在程序中分配 NSArray 和首次用objectEnumerator 獲取 enumerator 都需要異常長的時間才能完成。例如,在我 2007 年的 17 寸 MacBook Pro 上分配含一個元素的數組,所需時間的中位數是 415 納秒。但首次分配的時候會需要 500,000 納秒,有時甚至要到 1,000,000 納秒!獲取 enumerator 也是如此:盡管中位數只有 673 納秒,首次獲取卻要花 500,000 納秒以上。
我只能猜測其中的原因,但我懷疑延遲加載是罪魁禍首。在實際應用中,你可能不會注意到這一點,因為等到執行你的代碼時,Cocoa 或 Cocoa Touch 很可能已經創建過數組了。
並發枚舉
如果情況允許,你可以選擇用塊枚舉來並發枚舉對象。這意味著計算的工作量可以分散到幾個 CPU 內核上。並不是每種枚舉過程中的處理都是可並發的,因此只有沒用到鎖的時候,才能使用並發枚舉:要麼每一步操作確實是絕對相互獨立的,要麼有原子性的操作可用 (如 OSAtomicAdd32 之類)。
那麼,它相比其他枚舉類型有多大優勢呢?
圖表
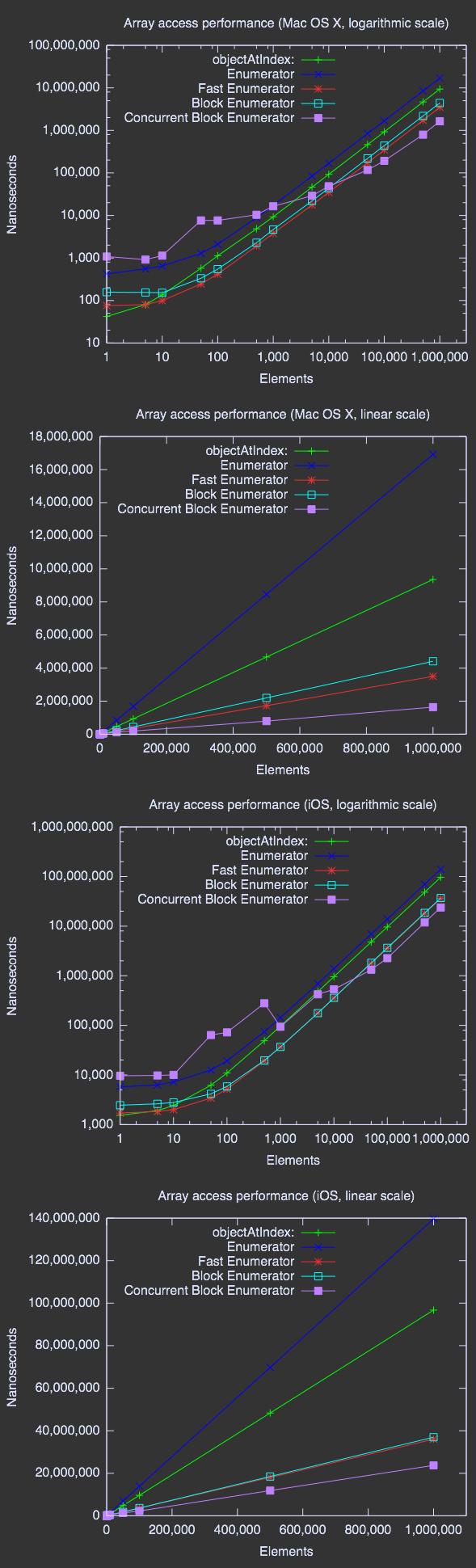
結論
元素不多時,並發枚舉是目前最慢的方法。主要原因可能是為了讓數組能並發訪問而做的准備工作和開啟線程我不知道用的是 GCD 還是“傳統的”線程,這不重要;這是我們不需關心的實現細節)。
盡管如此,如果數組足夠大,並發枚舉突然就成了最快的方法了,正如我們所料。在 iPhone 4S 上枚舉 100 萬個元素,用並發枚舉需要 0.024 秒,但快速枚舉需要 0.036 秒。相形之下,還是同一個數組,NSEnumeration 要用 0.139 秒! 這已經是非常大的差距了,足有 5.7 倍之多。
在我的辦公室,2011 iMac 24"采用了酷睿i7四核CPU,同時在0.0016秒之內列舉了百萬項。同一數組快速枚舉了0.0044秒和NSEnumeration o.oo93秒。那個因數是5.8,它非常接近於ipone 4S的結果。在這裡,我期待一個更大的差異,雖然,在我的2007 MacBook采用了Core2 Duo雙核CPU,在這裡因數剛好是3.7.當同時枚舉的阈值成為有用,在某處以我的測試是10,000和50,000分子之間。用更少的分子元素,去掉正常的塊迭代。