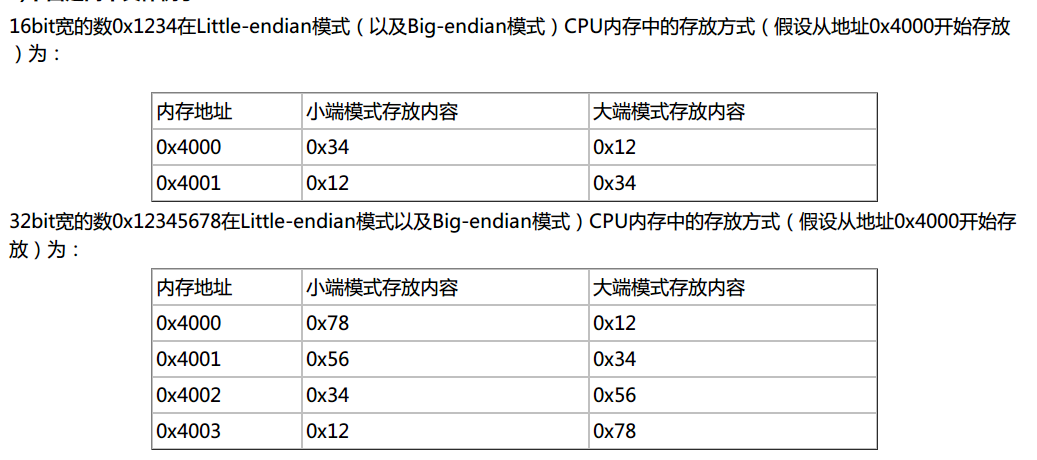
大端編碼方式:字數據的高字節存儲在低地址中。
小端編碼方式:字數據的低字節存儲在低地址中。
簡單而直觀地說,(當然這種理解方式是不嚴謹的)。
看了下一篇CSDN博客寫得挺全面,文末會給出相關地址,不過內容實在是有點太多了,所以還是自己寫寫學習筆記吧,雖然不是新知識了,溫故而知新總是好的。
在這裡請允許我摘錄自己需要的那部分:
另有就是面試的時候經常會遇到的,寫一個小程序判斷編譯器是大端還是小端模式(大端返回0,小端返回1):
= (c.b ==
每次看到這個代碼都覺得很蛋疼,主要是因為自己理解得本來就不是特別深刻,所以給出另外一種更直觀明了的判斷方法:
= (c.b ==
因為聯合體的中所有成員都是從低地址開始存放的,所以直接去比較c.b和0x12的值即可,如果相同,那就說明是大端格式了(返回1);如果不同,那就說明是小端格式了(返回0)。
大小端地址是怎麼來的?
在操作系統中我們存儲數據以字節為單位,一個字節byte型8個bit,char型short型16個bit,還有int型float型long型(取決於編譯器)32個bit,double的64個bit。這個時候就需要區分存儲模式了。
而int型和long型又要取決於平台和編譯器,比如編寫C或者C++程序,有時考慮到跨平台的兼容性問題,我們就需要明確使用__int8, __int16, __int32, __int64。
實際上,操作系統一般都是小端的,而像Java和所有網絡通信協議都是大端的,所以當我們進行網絡編程如socket編程的時候就要注意這點,也因此我們經常需要用到這些函數等進行大小端字節序的轉換(不過應用的時候我只會照搬照套,實際上理解得並不深刻)。
如果想要再深入理解的話,就要翻翻計算機操作系統相關的書籍了。這方面的相關知識實在是太薄弱了...《現代操作系統》這本書不錯,《自己動手寫操作系統》這本書聽說也很好,名字聽著就顯得很親民——自己寫。。。有機會要讀一讀寫一寫。
如果還想了解一下其他相關知識,可以參考下面的博文:
《詳解大端模式和小端模式》