C++編程語言是一款功能非常強大的計算機應用語言,其中不但能夠支持C語言中的所用功能,而且還能夠對很多程序設計風格提供支持。在這裡我們會詳細介紹一下有關C++淺拷貝的相關應用方式。
C++淺拷貝就是成員數據之間的一一賦值:把值賦給一一賦給要拷貝的值。但是可能會有這樣的情況:對象還包含資源,這裡的資源可以值堆資源,或者一個文件。。當值拷貝的時候,兩個對象就有用共同的資源,同時對資源可以訪問,這樣就會出問題。深拷貝就是用來解決這樣的問題的,它把資源也賦值一次,使對象擁有不同的資源,但資源的內容是一樣的。對於堆資源來說,就是在開辟一片堆內存,把原來的內容拷貝。
如果你拷貝的對象中引用了某個外部的內容比如分配在堆上的數據),那麼在拷貝這個對象的時候,讓新舊兩個對象指向同一個外部的內容,就是C++淺拷貝;如果在拷貝這個對象的時候為新對象制作了外部對象的獨立拷貝,就是深拷貝
引用和指針的語義是相似的,引用是不可改變的指針,指針是可以改變的引用。其實都是實現了引用語義。 深拷貝和淺拷貝的區別是在對象狀態中包含其它對象的引用的時候,當拷貝一個對象時,如果需要拷貝這個對象引用的對象,則是深拷貝,否則是淺拷貝。
COW語義是“深拷貝”與“推遲計算”的組合,仍然是深拷貝,而非淺拷貝,因為拷貝之後的兩個對象的數據在邏輯上是不相關的,只是內容相同。
無論深淺,都是需要的。當深拷貝發生時,通常表明存在著一個“聚合關系”,而C++淺拷貝發生時,通常表明存在著一個“相識關系”。
舉個簡單的例子:
當你實現一個Composite Pattern,你通常都會實現一個深拷貝(如果需要拷貝的話),很少有要求同的Composite共享Leaf的;
而當你實現一個Observer Pattern時,如果你需要拷貝Observer,你大概不會去拷貝Subject,這時就要實現個C++淺拷貝。 是深拷貝還是淺拷貝,並不是取決於時間效率、空間效率或是語言等等,而是取決於哪一個是邏輯上正確的
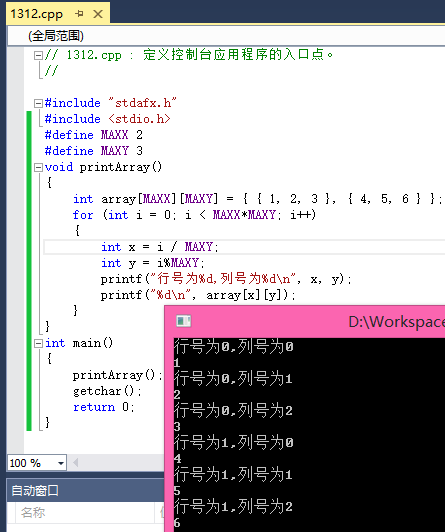
在學習這一章內容前我們已經學習過了類的構造函數和析構函數的相關知識,對於普通類型的對象來說,他們之間的復制是很簡單的,例如:
- int a = 10; int b =a;
在C++淺拷貝中,自己定義的類的對象同樣是對象,誰也不能阻止我們用以下的方式進行復制,例如:
- #include <iostream>
- usingnamespacestd;
- classTest
- {
- public: Test(inttemp)
- {
- p1=temp;
- }
- protected: intp1;
- };
- voidmain()
- {
- Test a(99);
- Test b=a;
- }
普通對象和類對象同為對象,他們之間的特性有相似之處也有不同之處,類對象內部存在成員變量,而普通對象是沒有的,當同樣的復制方法發生在不同的對象上的時候,那麼系統對他們進行的操作也是不一樣的,就類對象而言,相同類型的類對象是通過拷貝構造函數來完成整個復制過程的,在上面的代碼中,我們並沒有看到拷貝構造函數,同樣完成了復制工作,這又是為什麼呢?因為當一個類沒有自定義的拷貝構造函數的時候系統會自動提供一個默認的拷貝構造函數,來完成復制工作。
下面,我們為了說明情況,就普通情況而言(以上面的代碼為例),我們來自己定義一個與系統默認拷貝構造函數一樣的拷貝構造函數,看看它的內部是如何工作的!
代碼如下:
- #include <iostream>
- usingnamespacestd;
- classTest {
- public: Test(inttemp)
- { p1=temp; }
- Test(Test &c_t)
- //這裡就是自定義的拷貝構造函數
- {
- cout<<"進入copy構造函數"<p1p1=c_t.p1;
- //這句如果去掉就不能完成復制工作了,此句復制過程的核心語句 }
- public: intp1; };
- voidmain() { Test a(99); Test b=a;
- cout<cin.get();
- }
上面代碼中的Test(Test &c_t)就是我們自定義的拷貝構造函數,拷貝構造函數的名稱必須與類名稱一致,函數的形式參數是本類型的一個引用變量,且必須是引用。
當用一個已經初始化過了的自定義類類型對象去初始化另一個新構造的對象的時候,拷貝構造函數就會被自動調用,如果你沒有自定義拷貝構造函數的時候系統將會提供給一個默認的拷貝構造函數來完成這個過程,上面代碼的復制核心語句就是通過 Test(Test &c_t)拷貝構造函數內的p1=c_t.p1;語句完成的。如果取掉這句代碼,那麼b對象的p1屬性將得到一個未知的隨機值。
以上就是對C++淺拷貝的相關介紹。