作者:莊曉立 (liigo)
日期:2011-1-19
原創鏈接:http://blog.csdn.net/liigo/archive/2011/01/19/6153829.aspx
轉載請保持本文完整性,並注明出處:http://blog.csdn.net/liigo
關鍵字:HTML,解析器(Parser),節點(Node),標簽(Tag)
這是進入2011年以來,本人(liigo)“重復發明輪子”系列博文中的最新一篇。本文主要探討如何設計和實現一個基本的HTML文本解析器。
眾所周知,HTML是結構化文檔(Structured Document),由諸多標簽(<p>等)嵌套形成的著名的文檔對象模型(DOM, Document Object Model),是顯而易見的樹形多層次結構。如果帶著這種思路看待HTML、編寫HTML解析器,無疑將導致問題復雜化。不妨從另一視角俯視HTML文本,視其為一維線狀結構:諸多單一節點的順序排列。仔細審視任何一段HTML文本,以左右尖括號(<和>)為邊界,會發現HTML文本被天然地分割為:一個標簽(Tag),接一段普通文字,再一個標簽,再一段普通文字…… 如下圖所示:
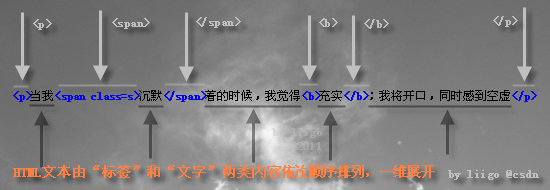
標簽有兩種,開始標簽(如<p>)和結束標簽(</p>),它們和普通文字一起,順序排列,共同構成了HTML文本的全部。
為了再次簡化編程模型,我(liigo)繼續將“開始標簽”“結束標簽”“普通文字”三者統一抽象歸納為“節點”(HtmlNode),相應的,“節點”有三種類型,要麼是開始標簽,要麼是結束標簽,要麼是普通文字。現在,HTML在我們眼裡更加單純了,它就是“節點”的線性順序組合,是一維的“節點”數組。如下圖所示:HTML文本 = 節點1 + 節點2 + 節點3 + ……

在正式編碼之前,先確定好“節點”的數據結構。作為“普通文字”節點,需要記錄一個文本(text);作為“標簽”節點,需要記錄標簽名稱(tagName)、標簽類型(tagType)、所有屬性值(props);另外還要有個類型(type)以便區分該節點是普通文字、開始標簽還是結束標簽。這其中固然有些冗余信息,比如對標簽來說不需要記錄文本,對普通文字來說又不需要記錄標簽名稱、屬性值等,不過無傷大雅,簡潔的編程模型是最大的誘惑。用C/C++語言語法表示如下:
view plaincopy to clipboardprint?
enum HtmlNodeType
{
NODE_UNKNOWN = 0,
NODE_START_TAG,
NODE_CLOSE_TAG,
NODE_CONTENT,
};
enum HtmlTagType
{
TAG_UNKNOWN = 0,
TAG_A, TAG_DIV, TAG_FONT, TAG_IMG, TAG_P, TAG_SPAN, TAG_BR, TAG_B, TAG_I, TAG_HR,
};
struct HtmlNodeProp
{
WCHAR* szName;
WCHAR* szValue;
};
#define MAX_HTML_TAG_LENGTH (15)
struct HtmlNode
{
HtmlNodeType type;
HtmlTagType tagType;
WCHAR tagName[MAX_HTML_TAG_LENGTH+1];
WCHAR* text;
int propCount;
HtmlNodeProp* props;
};
enum HtmlNodeType
{
NODE_UNKNOWN = 0,
NODE_START_TAG,
NODE_CLOSE_TAG,
NODE_CONTENT,
};
enum HtmlTagType
{
TAG_UNKNOWN = 0,
TAG_A, TAG_DIV, TAG_FONT, TAG_IMG, TAG_P, TAG_SPAN, TAG_BR, TAG_B, TAG_I, TAG_HR,
};
struct HtmlNodeProp
{
WCHAR* szName;
WCHAR* szValue;
};
#define MAX_HTML_TAG_LENGTH (15)
struct HtmlNode
{
HtmlNodeType type;
HtmlTagType tagType;
WCHAR tagName[MAX_HTML_TAG_LENGTH+1];
WCHAR* text;
int propCount;
HtmlNodeProp* props;
};
具體到編寫程序代碼,要比想象中容易的多。編碼的核心要點是,以左右尖括號(<和>)為邊界自然分割標簽和普通文字。左右尖括號之間的當然是標簽節點(開始標簽或結束標簽),左尖括號(<)之前(直到前一個右尖括號或開頭)、右尖括號(>)之後(直到後一個左尖括號或結尾)的顯然是普通文字節點。區分開始標簽或結束標簽的關鍵點是,看左尖括號(<)後面第一個非空白字符是否為/。對於開始標簽,在標簽名稱後面,間隔至少一個空白字符,可能會有形式為“key1=value1 key2=value2 key3”的屬性表,關於屬性表,後文有專門的函數負責解析。此外有一點要注意,屬性值一般有引號括住,引號內出現的左右尖括號應該不被視為邊界分隔符。
下面就是負責把HTML文本解析為一個個節點(HtmlNode)的核心代碼(不足百行,夠精簡吧):
view plaincopy to clipboardprint?
void HtmlParser::ParseHtml(const WCHAR* szHtml)
{
m_html = szHtml ? szHtml : L"";
freeHtmlNodes();
if(szHtml == NULL || *szHtml == L) return;
WCHAR* p = (WCHAR*) szHtml;
WCHAR* s = (WCHAR*) szHtml;
HtmlNode* pNode = NULL;
WCHAR c;
bool bInQuotes = false;
while( c = *p )
{
if(c == L")
{
bInQuotes = !bInQuotes;
p++; continue;
}
if(bInQuotes)
{
p++; continue;
}
if(c == L<)
{
if(p > s)
{
//Add Text Node
pNode = NewHtmlNode();
pNode->type = NODE_CONTENT;
pNode->text = duplicateStrUtill(s, L<, true);
}
s = p + 1;
}
else if(c == L>)
{
if(p > s)
{
//Add HtmlTag Node
pNode = NewHtmlNode();
while(isspace(*s)) s++;
pNode->type = (*s != L/