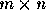by 沖出宇宙
2011-8-24
1、性能優化原理
在談論性能優化技術之前,有幾點大家一定要明確。第一點是必須有編寫良好的代碼,編寫的很混亂的代碼(如注釋缺乏、命名模糊),很難進行優化。第二點是良好的構架設計,性能優化只能優化單個程序,並不能夠優化蹩腳的構架。不過,網絡如此發達,只要不是自己亂想的構架,只要去積極分析別人的成功構架,大家幾乎不會遇到蹩腳的構架。
1.1、計算函數、代碼段調用次數和耗時
函數的調用次數比較好說,用一個簡單的計數器即可。一個更加通用的框架可能是維護一個全局計數,每次進入函數或者代碼段的時候,給存儲的對應計數增加1。
為了精確的計算一段代碼的耗時,我們需要極高精度的時間函數。gettimeofday是其中一個不錯的選擇,它的精度在1us,每秒可以調用幾十萬次。注意到現代cpu每秒能夠處理上G的指令,所以1us內cpu可以處理幾千甚至上萬條指令。對於代碼長度少於百行的函數來說,其單次執行時間很可能小於1us。目前最精確的計時方式是cpu自己提供的指令:rdtsc。它可以精確到一個時鐘周期(1條指令需要消耗cpu幾個時鐘周期)。
我們注意到,系統在調度程序的時候,可能會把程序放到不同的cpu核心上面運行,而每個cpu核心上面運行的周期不同,從而導致了采用rdtsc時,計算的結果不正確。解決方案是調用linux系統的sched_setaffinity來強制進程只在固定的cpu核心上運行。
有關耗時計算的參考代碼:
// 通常計算代碼耗時
uint64_t preTime = GetTime();
//代碼段
uint64_t timeUsed = GetTime() - preTime;
// 改進的計算方式
struct TimeHelper{
uint64_t preTime;
TimeHelper():preTime(GetTime())
{}
~TimeHelper(){
g_timeUsed = GetTime() - preTime;
}
};
// 調用
{
TimeHelper th;
// 代碼段
}
// g_timeUsed保存了耗時
// 得到cpu的tick count,cpuid(重整時鐘周期)消耗約300周期(如果不需要特別精確的精度,可以不執行cpuid
inline uint64_t GetTickCPU()
{
uint32_t op; // input: eax
uint32_t eax; // output: eax
asm volatile(
"pushl %%ebx \n\t"
"cpuid \n\t"
"popl %%ebx \n\t"
: "=a"(eax) : "a"(op) : "cc" );
uint64_t ret;
asm volatile ("rdtsc" : "=A" (ret));
return ret;
}
// 得到cpu的主頻, 本函數第一次調用會耗時0.01秒鐘
inline uint64_t GetCpuTickPerSecond()
{
static uint64_t ret = 0;
if(ret == 0)
{
const uint64_t gap = 1000000 / 100;
uint64_t endTime = GetTimeUS() + gap;
uint64_t curTime = 0;
uint64_t tickStart = GetTickCPU();
do{
curTime = GetTimeUS();
}while(curTime < endTime);
uint64_t tickCount = GetTickCPU() - tickStart;
ret = tickCount * 1000000L / (curTime - endTime + gap);
}
return ret;
}
1.2、其他策略
除了基本的計算執行次數和時間外,還有如下幾種分析性能的策略:
a、基於概率
通過不斷的中斷程序,查看程序中斷的位置所在的函數,出現次數最多的函數即為耗時最嚴重的函數。
b、基於事件
當發生一次cpu硬件事件的時候,某些cup會通知進程。如果事件包括L1失效多少次這種,我們就能知道程序跑的慢的原因。
c、避免干擾
性能測試最忌諱外界干擾。比如,內存不足,讀內存變成了磁盤操作。
1.3、性能分析工具-callgrind
valgrind系列工具因為免費,所以在linux系統上面最常見。callgrind是valgrind工具裡面的一員,它的主要功能是模擬cpu的cache,能夠計算多級cache的有效、失效次數,以及每個函數的調用耗時統計。
callgrind的實現機理(基於外部中斷)決定了它有不少缺點。比如,會導致程序嚴重變慢、不支持高度優化的程序、耗時統計的結果誤差較大等等。
我們編寫了一個簡單的測試程序,用它來測試常見性能分析工具。代碼如下:
// 計算最大公約數
inline int gcd(int m, int n)
{
PERFOMANCE("gcd"); // 全局計算耗時的define
int d = 0;
do{
d = m % n;
m = n;
n = d;
}while(d > 0);
return m;
}
// 主函數
int main(){
int g = 0;
uint64_t pretime = GetTickCPU();
for(int idx = 1; idx < 1000000;idx ++)
g += gcd(1234134,idx);
uint64_t time = GetTickCPU() - pretime;
printf("%d,%lld\n", g, time);
return 0;
}
callgrind運行的結果如下:
我們把輸出的結果在windows下用callgrind的工具分析,得到如下結果:
1.4、g++性能分析
gprof是g++自帶的性能分析工具(gnu profile)。它通過內嵌代碼到各個函數裡面來計算函數耗時。按理說它應該對高度優化代碼很有效,但實際上它對-O2的代碼並不友好,這個可能和它的實現位置有關系(在代碼優化之後)。gprof的原理決定了它對程序影響較小。
下圖是同樣的程序,用gprof檢查的結果:
我們可以看到,這個結果比callgrind計算的要精確很多