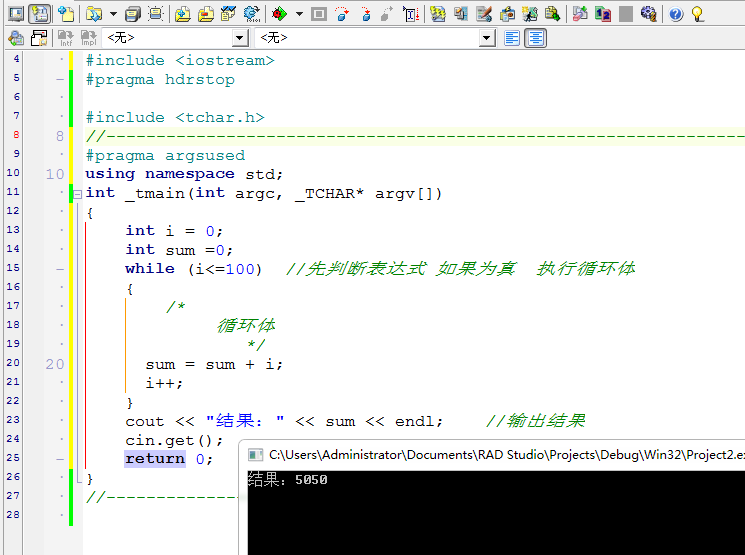
1. 編譯單元,一個.cc,或.cpp作為一個編譯單元.生成.o
2. 普通數據類型的定義,聲明,函數的定義聲明(類函數是一樣的)
extern int x; //變量是聲明,並未實際分配地址,未產生實際目標代碼
void print(); // 函數聲明, 未產生實際目標代碼
如int x; int x = 3 ; void print() {}; //均為定義產生了實際目標代碼。
聲明不產生實際的目標代碼,它的作用是告訴編譯器,OK,我在該編譯單元後面,或者其它編譯單元會有這個x變量,print函數的定義。否則編譯器如果發現程序用到x,print,而前面沒有聲明會報錯。如果有聲明,而沒有定義,那麼鏈接的時候會報錯未定義。
比較常見的是我在source.cc中調用print(),而head.h中聲明print(),而source.cc 中include
head.h從而就有了print的聲明,可以通過編譯,但是如果在所有編譯單元中沒有print函數的定義,那麼鏈
接的時候source.o單元就會出錯,因為它試圖用print函數但是找不到print的定義。
//head.h
void pirnt();
//source.cc
void foo() {
print();
}
由於聲明不產生實際代碼,所以可以有多個重復聲明的存在。
//source1.cc
extern int x;
//source2.cc
extern int x;
甚至同一個編譯單元也可以有多各個重復聲明
//source1.cc
extern int x;
extern int x;
而普通變量定義,函數定義是不允許的。
3. 同一編譯單元內部的重名符號在編譯期就被阻止了,而不同編譯單元之間的重名符號要到鏈接器才會被發
現。
如果你在一個 source1.cc中
//source1.cc
int x;
int x;
出現兩次 int x; int x;即兩個x的定義,會編譯報錯,x重復定義。
如果你的
//source1.cc
int x;
//source2.cc
int x;
g++ –o test source1.cc source2.cc
那麼編譯過程不會出錯,在鏈接過程,由於目標代碼中有兩個全局域的x,會鏈接出錯,x重定義。
不同的編程人員可能會寫不同的模塊,那麼很容易出現這種情況,如何避免呢,namespace可以避免重名。
google 編程規范鼓勵使用不具名空間
//source1.cc
namespace {
int x;
}
//source2.cc
namespace {
int x;
}
OK,現在不會鏈接出錯了因為兩個x不重名了,當然對於這個簡單的例子只在source1.cc中用不具名命名空間就可
避免鏈接出差了。
//注
//source1.cc
namespace {
int x;
}
//source1.cc
static int x;
有什麼區別呢,看上去效果一樣,區別在於不具名空間的x仍然具有外鏈接,但是由於它是不具名的,所以別的單元沒辦法鏈接到,如果
namespace haha{
int x;
}
則在別的單元可以用haha::x訪問到它,static 則因為是內部鏈接特性,所以無法鏈接到。
C++ 中 static 和 anonymouse namespace 的差別
2009-01-02 14:54 | 分類:桌面應用開發
記得以前一個同事問我為什麼程序裡使用了 anonymouse namespace ,想了想 就回答說其實就是保持局部性(這也是我的目的),然後就有人說為什麼不用static,嗯 似乎這兩個東西乍一看沒什麼區別,自己便Google了一下,發現有一個原因就是 anonymousenamespace 裡的 member 都是有外部鏈接的,只不過永遠都不能被外部link到!而 static 就明確為根本沒有外部鏈接!此時就出現問題了,在模板裡無類型的參數必須是有外部鏈接的才可以,否則編譯無法通;比如:
template <void fn()>
class Foobar
{};
namespace
{
void abc()
{
wcout<<_T(”abc”)<<endl;
};
}
static void efg()
{
wcout<<_T(”efg”)<<endl;
};
int _tmain(int argc, _TCHAR* argv[])
{
Foobar<abc>xyz //! ;這一行可以通過
Foobar<efg>rst; //! 注意這一行編譯不過
return 0;
}
也有人認為使用 anon namespace比較好,因為static的方式被C++98標准所批評,呵呵 總體來說 ,其實你完全可以用anony namespace代替static。
4. 關於頭文件。
//head.h
int x;
//source1.cc
#include “head.h”
//source2.cc
#include “head.h”
頭文件不被編譯,.cc中的引用 include “ head.h”其實就是在預編譯的時候將head.h中的內容插入到.cc中。
所以上面的例子如果
g++ –o test source1.cc source2.cc, 同樣會鏈時發現重復定義的全局變量x。
因此變量定義,包括函數的定義不要寫到頭文件中,因為頭文件很可能要被多個.cc引用。
那麼如果我的head.h如下這麼寫呢,是否防止了x的鏈接時重定義出錯呢?
//head.h
#ifndef _HEAD_H_
#define _HEAD_H_
int x;
#endif
//source1.cc
#include “head.h”
//source2.cc
#include “head.h”
現在是否g++ –o test source1.cc source2.cc就沒有問題了呢,答案是否定的。
所有的頭文件都是應該如上加#ifndef #endif的,但它的作用是防止頭文件在同一編譯單元被重復引用。
就是說防止可能的
//source1.cc
#include “head.h”
#include “head.h”
這種情況,當然我們不會主動寫成上面的形式但是,下面的情況很可能發送
//source1.cc
#include “head.h”
#inlcude “a.h”
//a.h
#include “head.h”
這樣就在不經意見產生了同一編譯單元的頭文件重復引用,於是soruc1.cc 就出現了兩個int x;定義。
但是對於不同的編譯單元source1.cc,source2.cc他們都是還會引用head.h的,即使#ifndef #endif的存在。
5. 關於類的聲明和定義。
class A; //類的聲明
類的聲明和普通變量聲明一樣,不產生目標代碼,可以在同一,以及多個編譯單元重復聲明。
class A {
}; //類的定義 www.2cto.com
類的定義就特殊一點了,可能會有疑問,為什麼不能把int x;這樣的變量定義放到.h中(見4)但是可以把
類的定義放在頭文件中重復引用呢?同時類的函數非inline定義(寫在類定義裡面的函數是inline,除外)不能寫在
頭文件中呢。
這是因為類的定義,只是告訴編譯器,類的數據格式是如何的,實例話後對象該占多大空間。
類的定義也不產生目標代碼。因此它和普通變量的聲明唯一的區別是不能在同一編譯單元內出現多次。
//source1.cc
class A;
class A; //類重復聲明,OK
class A{
};
class A{
};
class A{
int x;
}; //同一編譯單元內,類重復定義,會編譯時報錯,因為編譯器不知道在該編譯單元,A a;的話要生產怎樣的a.
//如果class A{};定義在head.h ,而head.h 沒有
//#ifndef #endif 就很可能在同一編譯單元出現類重復定義的編譯錯誤情況。
但是在不同編譯單元內,類可以重復定義,因為類的定義未產生實際代碼。
//source1.cc
class A{
}
//source2.cc
class A{
} //不同編譯單元,類重復定義,OK。所以類的定義可以寫在頭文件中!
//source1.cc
class A{
}
//source2.cc
class A{
int x;
} //不同編譯單元,OK
6. 總結
1.在頭文件中寫變量的聲明,函數聲明,類的定義,inline函數,不要出現變量定義,類的函數非inline定義,函數定
義。
即在頭文件中不要出現可能產生目標代碼的東東。
2.為了防止在一個編譯單元內部頭文件重復引用,所有頭文件都要加上#ifndef #endif
3.鼓勵在.cc中使用不具名namespace,可以有效防止不同編譯單元命名沖突。
4.相關更專業詳細的介紹可以看<<大規模C++程序設計>>的第一章,會有極其好的完整介紹。
其中提到類的定義是具有內部鏈接特性的,即它不是聲明
不能在同一編譯單元重復出現,但是它具有內部鏈接,(所謂內部鏈接指的是該名稱對於所在編譯單元是局部的,在鏈接時不會與其他編譯單元中同樣
的名稱產生命名沖突),所以類如果要在單個編譯單元之外使用它必須被定義在一個頭文件中。
對於聲明和定義,書中給出的定義是:
一個聲明將一個名稱引入程序,一個定義提供了一個實體(例如,類型,實例,函數)在一個程序中的唯一描述。
5. 前面第一條說的不是很確切,按照<<大規模C++程序設計>>中的說法
理論上頭文件中可以放所有具有內部鏈接的東西,包括具有內部鏈接的定義。如
static int x;
static void print() {};
但是不提倡這麼做,因為每一個包含這個頭文件的.cc就對應要開辟一個空間存儲這個x,就是說不同編譯單元都引入static int x;由於是內部鏈接,所以互不影響彼此。
甚至你采用namespace也是如此,如
在.h中
namespace myspace {
static int x;
}
不同.cc文件中都引入該頭文件,在各自編譯單元中調用的myspace::x也是不同的互不影響的!
書中提到
const int width = 3; //見書的23頁
這樣的const變量也要避免出現在頭文件中,不過類似以前c語言中
在頭文件中
#define width 3
還是很常用的啊。難道也要在
.h中
extern const int width;
.cc中
const int width = 5;
這樣雖然可以,不過好麻煩啊,我倒覺得在.h中定義類似const int width =3 問題不大,難道編譯器不會做些特殊的處理優化嗎,也要每個單元分配一個單獨空間?
不過倒是也可以利用下面的方法在.h中聲明一批const 變量。注意和普通static 變量不同,類的成員靜態變量,靜態函數是具有外部鏈接的。如果
static const int SUCCESS = 0; ,SUCCESS不是 const 僅僅是 static int,那麼是不可以在類內初始化的(編譯出錯),需要在某個.cc文件中初始話,因為它是具有外部鏈接的。(在GOOGLE編程規范中,提到禁止使用類類型的全局變量,靜態成員變量視為全局變量,也禁止使用類類型)
class code
{
public:
static const result_code SUCCESS = 0;//program ended successfully
static const result_code INVALID_ADDRESS = 1;//wrong addres
static const result_code READ_FAIL = 2;//cannot read
static const result_code WRITE_FAIL = 3;//cannot write
static const result_code UNKNOWN_ACTION = 4;//dunno...
static const result_code NOT_FOUND = 5;//key not found in paragraph
static const result_code NO_WRITE = 6;//no write since modification
static const result_code SYNTAX_ERR = 7;//command syntax error
static const result_code EMPTY_CLIP = 8;//the clipboard is empty
};
摘自 XpowerLord